
技术摘要:
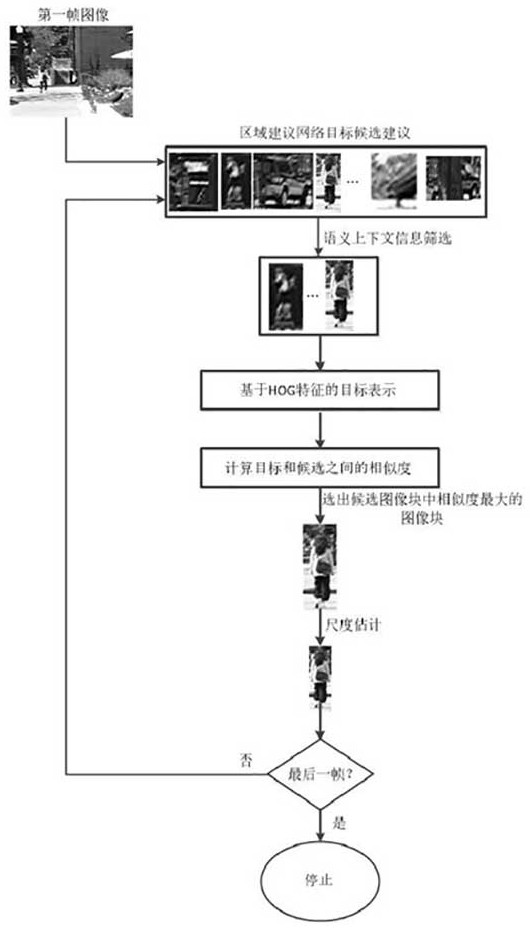
本发明提出了一种基于具有语义评估和区域建议的突变运动目标跟踪方法,用以解决现有方法运行效率不高,跟踪精度较低的问题。本发明的步骤为:首先初始化区域建议网络的模型参数和目标图像块的状态参数;由上一状态得到密集采样候选图像块,由区域建议网络生成目标区域候 全部
背景技术:
在计算机视觉领域中,视频中运动目标的跟踪是一个热点研究问题,但是由于跟 踪环境的复杂性,目标运动的不确定性和摄像机成像等因素,往往导致相邻两帧图像中目 标的位移量很大,致使目标跟踪失败。针对目标突变这一现象,传统的基于目标平滑性假设 的众多算法很容易跟踪失败。而区域建议可以在全局内给出目标建议,从而在目标出现突 变运动时区域建议可以覆盖目标的真实状态来达到跟踪目标。因此,用区域建议的方法解 决运动目标突变的状况,可以保证目标跟踪算法的鲁棒性。 在视频跟踪中,用区域建议网络的方法来解决目标突变运动的问题,首先要解决 传统区域建议方法两个明显的问题:(1)区域建议网络由离线训练,可以检测出特定的一些 类别的目标。在跟踪时如果将所有的区域建议都用来进行目标匹配,效率会大大降低;(2) 区域建议网络所给出的区域往往不能直接作为图像块用来进行匹配。因此,必须寻找一种 能够减少无关的区域建议和有效的从候选块截取图像块的目标跟踪方法。
技术实现要素:
针对现有的突变运动目标跟踪方法跟踪效果交叉的问题,本发明提出了一种基于 具有语义评估和区域建议的突变运动目标跟踪方法,将区域建议和语义评估引入到跟踪 中,在全局提供更加可靠的目标候选样本,从而解决突变运动的目标跟踪问题。 为达到上述目的,本发明采用以下技术方案: 一种基于具有语义评估和区域建议的突变运动目标跟踪方法,其步骤如下: 步骤一:初始化区域建议网络模型:将网络模型选用VGG-16模型用来提取图像特 征,设置最大目标建议数量、重叠阈值和测试量表,设定候选目标建议输出的阈值; 步骤二:采用语义评估和区域建议在全局内获得少量高质量的含有目标的区域建 议:1)根据跟踪目标与目标建议的图像块的语义信息判断目标的类别,将不属于该目标类 别的候选区域去除;2)根据上下文位置信息在候选区域位置上截取与目标图像块大小形同 的区域作为候选图像块; 步骤三:采用混合跟踪算法搜索候选图像块:1)将目标区域候选图像块和当前图 片上一帧目标位置的图像块进行对比;2)将于目标图像块的相似度值最大的候选目标图像 块做为当前帧的最后候选图像块的位置;3)在确定目标图像块位置后,以图像块中点为中 心,在当前帧以固定步长截取与当前目标图像块具有相同宽高比例的一系列图像块,然后 将这些图像块调整至与目标图像块一样的大小,再次与上一帧目标图像块进行对比,并将 相似度值最大的图像块做为当前帧图像的目标真实状态; 5 CN 111598928 A 说 明 书 2/7 页 步骤四:将步骤三输出的最优候选图像块作为当前帧的目标图像块及下一帧的目 标状态参数,返回步骤二进行下一帧图像的跟踪; 步骤五:重复步骤二…步骤四,直至达到最后一帧图像,输出每一帧图像的最优候 选图像块,实现运动目标的跟踪。 所述步骤一中初始化目标图像块的状态参数的方法为:读取第一帧图像的数据信 息,确定目标图像块在第一帧图像内的状态参数[x,y,w,h],其中,x、y为目标图像块在每帧 图像左上角像素点的坐标值,w为目标图像块的宽度,h为目标图像块的高度。 所述步骤二中根据目标语义信息判断目标类别筛选的方法是:根据计算目标在上 一时刻与候选区域建议的重叠率(IOU): 其中其中i为候选建议的类别,j为第i类的第j个候选建议,pa为目标在前一帧中 的位置信息,pb(i ,j)为上一帧中第类的第个候选区域边界框位置信息,则可得到最大重叠 率: IOU(t,j')=max{IOU(1,1) ,...IOU(2,1) ,...IOU(20,j)} 其中t是在当前帧图像中跟踪的目标的类别;因此当前帧的候选区与建议经过筛 选后为: pt={p(t,1) ,p(t,2) ,...p(t,n)} 其中pt是经过语义评估后生成的对象级候选区域建议。 所述的候选目标建议输出的阈值设置为0.1。 所述步骤二中使用上下文空间位置信息获取候选图像块的方法是:由目标在上一 帧的空间位置信息在当前帧的对象级区域候选建议截取图像块,建立一个以目标检测框左 上角为原点的坐标系,目标位置由中心点坐标表示;目标在检测框中的相对位置表示为: 其中a1和b1分别为上一帧目标检测框的宽度和高度,a0和b0为目标检测框中的目 标位置;xk和yk是目标在上一帧的空间位置信息;同样的方法在当前帧建立目标检测框的坐 标系;候选图像块由xk和yk确定;其位置估计为: 其中x和y为图像块的中心位置,c1和d1为当前帧目标检测框的宽度和高度;由此在 当前帧中得到图像块对目标进行视觉跟踪定位。 所述步骤三中的混合跟踪算法为:分别将目标区域候选图像块和当前图片上一帧 目标位置的图像块学习训练的滤波器进行对比;将于目标图像块的相似度值最大的候选目 标图像块做为当前帧的最后候选图像块的位置。 所述步骤三中的目标尺度估计为: 6 CN 111598928 A 说 明 书 3/7 页 采用尺度搜索策略在目标周围构造一个目标金字塔,并学习一个单独的一维尺度 估计滤波器来估计目标尺度,训练样本设置为大小如下的矩形框: f={anM×anN},n∈{-16,-15,...,15,16} 其中a=1.02为尺度因子,原图像块大小为M×N,即上一帧目标图像块宽度和高 度;n为以尺度因子为步长,原图像块所放缩的倍数,放缩后的图像块大小为anM×anN;s为尺 度样本的个数;即n从-16取到16,一共放缩了33次,共33个样本;最终得到目标在当前帧的 预测位置[xbest,ybest,wbest,hbest]。 所述步骤三中相似度值的计算方法为:将候选目标块进行循环矩阵移位,构造出 复杂的样本,然后利用循环矩阵移位得到丰富的训练集进行训练,对应的标签是根据距离 的不同来进行赋值的;利用岭回归进行分类器训练,并且目标函数即为损失函数及正则化 项之和: 其中,xi和yi为分类器训练的样本和样本对应的标签,i表示第i个样本和样本标 签,w是表示权重系数的列向量,λ为控制复杂性的参数;然后提取图像块的HOG特征,将它们 作为随机变量,计算目标图像与候选图像之间的相似度: 其中,ai为列向量,k为核函数;首先得到密集采样候选图像块与目标图像的响应, 并找出其最大响应值Rkmax和位置(xkbest,y ),wTkbest 为w的转置,z为候选图像块,xi为分类器 第i个训练样本i∈N ; 然后计算区域建议候选图像块与目标图像块的最大响应和对应的位置: Rmax={R1max,R2max,R3max,...,Rnmax} P={(xi,yi)|i=1,2,....,n} 对比密集采样图像块最大响应Rkmax与区域建议图像块Rmax值得大小,当Rmax≥Rkmax 时: Rkmax←Rimax (xkbest,ykbest)←(xi,yi) 判断当i=n时,将最后得到的(xkbest,ykbest)作为目标在当前帧的位置。 本发明的有益效果:采用区域建议网络进行全局的运动状态建议,并在此基础上, 采用语义评估和上下文空间位置信息来进一步的对候选建议进行筛选,最终获得少量的高 质量的包含目标真实运动状态候选区域建议使得能够在全局内去找到与目标最相似的图 像块区域,从而适应突变运动下的目标跟踪问题,后续对跟踪目标的识别、理解和分析具有 重要意义。 附图说明 为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例或现 7 CN 111598928 A 说 明 书 4/7 页 有技术描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本 发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以 根据这些附图获得其他的附图。 图1为本发明的流程图; 图2为根据上下文空间信息在建议区域截取图像块操作示意图; 图3为本发明与其他算法的距离精度比较示意图; 图4为本发明与其他算法的重叠率比较示意图; 图5为本发明与其他算法的跟踪效果示意图。











