
技术摘要:
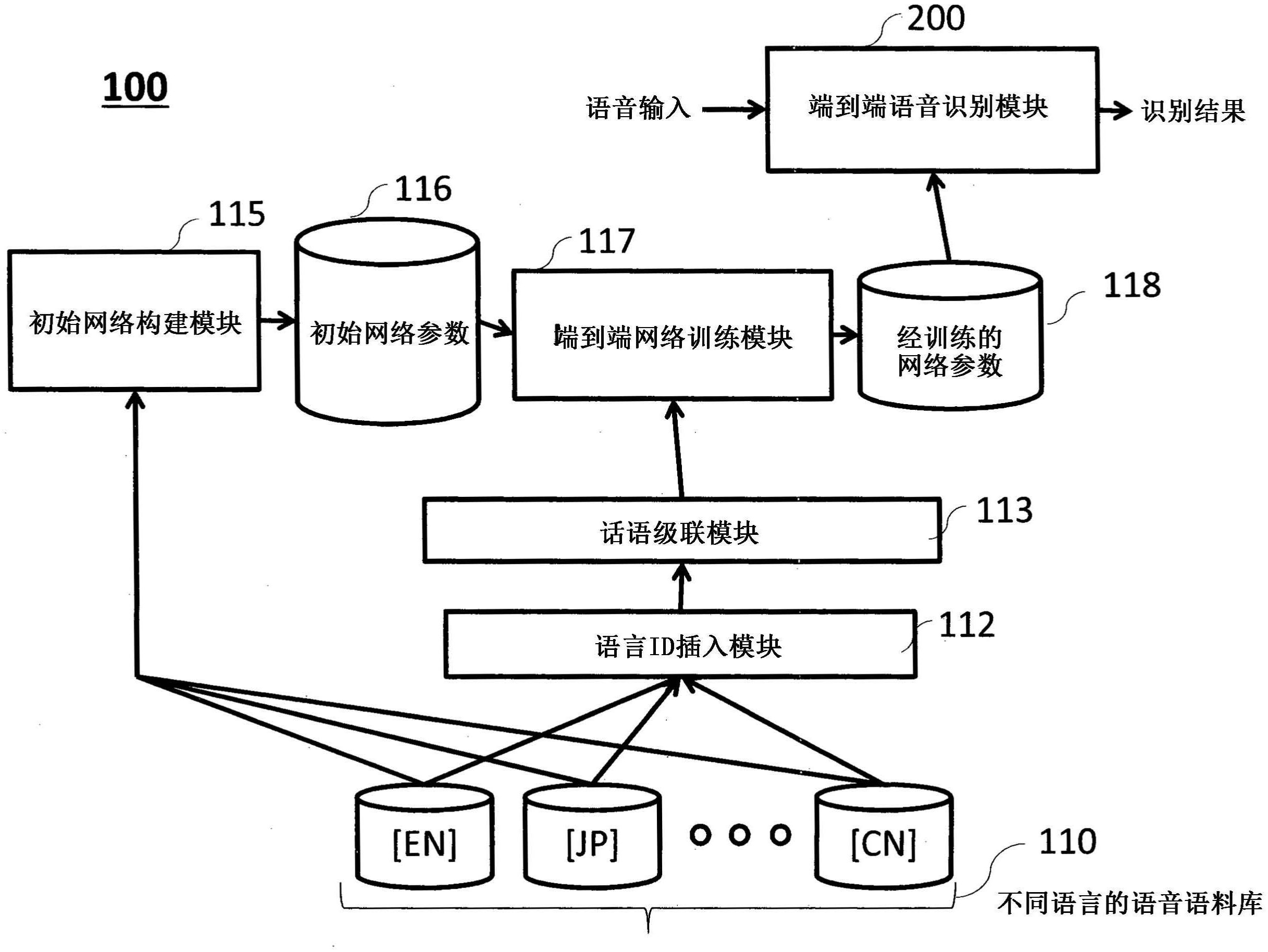
一种用于训练多语言语音识别网络的方法包括:提供与预定语言相对应的话语数据集;在话语数据集中插入语言标识(ID)标签,其中,话语数据集中的每一个由语言ID标签中的每一个来加标签;将加标签的话语数据集级联;从话语数据集生成初始网络参数;根据预定序列选择初始网 全部
背景技术:
端到端自动语音识别(ASR)最近通过达到传统混合ASR系统获得的最先进性能,同 时在易于开发性方面也超过了它们,从而证明了其有效性。传统ASR系统需要诸如发音词典 和单词分段之类的语言依存资源,这些资源被并入以音素作为中间表示的模型中。这些资 源是手工开发的,因此存在两个缺点:首先,它们可能易于出错,或者在其它方面是次优的; 其次,它们极大地增加了开发ASR系统(特别是针对新语言)所需的工作量。因此,语言依存 资源的使用使得多语言识别系统的开发尤其复杂。相反,端到端ASR系统在没有诸如音素或 单词之类的表示语音/语言结构的任何明确中间表示的情况下,将输入语音特征序列直接 转换为输出标签序列(在本发明的实施方式中,主要是由n-gram字符组成的字符或标识的 序列)。它们的主要优点在于避免了对手工制作的语言依存资源的需求。 关于多语言/语言独立ASR已有一些在先研究。在基于深度神经网络(DNN)的多语 言系统的上下文中,使用DNN计算语言独立瓶颈特征。因此,有必要准备语言依存的后端系 统,例如发音词典和语言模型。另外,有必要预测说出的语言以将语言独立模块和语言依存 模块级联。
技术实现要素:
在本发明中,公开了一种具有语言独立神经网络架构的系统和方法,该系统和方 法能够在多种不同语言中联合地识别语音并标识语言。例如,本发明使我们能够自动识别 英语、日语、汉语普通话、德语、西班牙语、法语、意大利语、荷兰语、葡萄牙语和俄语的话语, 并联合标识每句话语的语言。 根据本发明的实施方式,网络跨语言共享包括softmax层的所有参数。 例如,由于网络通过级联多种语言的字素集来共享包括softmax层的所有参数,因 此本发明的语言独立神经网络架构能够在诸如英语、日语、汉语普通话、德语、西班牙语、法 语、意大利语、荷兰语、葡萄牙语、俄语等的不同语言中联合地识别语音并且标识语言。 本发明的语言独立神经网络能够通过以下步骤进行多语言端到端语音识别:(1) 制作作为来自多种语言的字素集和语言ID的并集的通用标签集,并基于此构建初始网络, (2)将语言ID标签插入到多个不同语言语料库的每句话语的转录中,(3)通过从多个不同语 言语料库中选择一句或多句话语并将它们以任意顺序级联来生成话语,其中,相应的转录 也以相同的顺序级联,(4)用生成的话语和转录来训练初始网络,以及(5)用经训练的网络 识别语音。 这种用于多语言语音识别的整体式端到端ASR系统具有3个优点:首先,整体式架 4 CN 111557029 A 说 明 书 2/18 页 构去除了语言依存ASR模块和外部语言标识模块;其次,端到端架构使得无需准备手工制作 的发音词典;以及第三,共享网络,使得即使对于资源匮乏的语言,也能够学习更好的特征 表示。 因为训练数据被增广为包括语言切换,所以本发明还使得即使在语音信号中存在 语言切换,端到端ASR系统也可以正确地工作。 根据本发明的一些实施方式,一种用于训练多语言语音识别网络的方法包括:提 供与预定语言相对应的话语数据集;在话语数据集中插入语言标识(ID)标签,其中,话语数 据集中的每一个由语言ID标签中的每一个来加标签;将加标签的话语数据集级联;从话语 数据集生成初始网络参数;以及用一系列的初始网络参数和级联的加标签的话语数据集迭 代地训练端到端网络,直到训练结果达到阈值。 此外,根据本发明的实施方式,一种用于执行多语言语音识别的语音识别系统包 括:接收讲话声音的接口;一个或更多个处理器;以及一个或更多个储存装置,该一个或更 多个储存装置存储通过由用于训练多语言语音识别网络的方法所获得的经训练的网络参 数已经训练的端到端语音识别网络模块,其中,端到端语音网络识别模块包括指令,当执行 该指令时使一个或更多个处理器执行包括以下操作:使用声学特征提取模块,从由讲话声 音转换的音频波形数据中提取声学特征序列;使用具有编码器网络参数的编码器网络将声 学特征序列编码为隐藏向量序列;通过将隐藏向量序列馈送到具有解码器网络参数的解码 器网络来预测第一输出标签序列概率;由联接主义时序分类(CTC)模块使用CTC网络参数和 来自编码器网络的隐藏向量序列,预测第二输出标签序列概率;以及使用标签序列搜索模 块,通过组合从解码器网络和CTC模块提供的第一输出标签序列概率和第二输出标签序列 概率,搜索具有最高序列概率的输出标签序列。 更进一步地,根据本发明的实施方式,一种用于生成用于多语言语音识别的经训 练的网络参数的多语言语音识别系统包括:一个或更多个处理器;以及一个或更多个储存 装置,该一个或更多个储存装置存储参数和包括一个或更多个处理器能执行的指令的程序 模块,当执行指令时使得一个或更多个处理器执行包括以下操作:提供与预定语言相对应 的话语数据集;在话语数据集中插入语言标识(ID)标签,其中,话语数据集中的每一个由语 言ID标签中的每一个来加标签;将加标签的话语数据集级联;从话语数据集生成初始网络 参数;以及根据预定序列选择初始网络参数;以及用一系列所选择的初始网络参数和级联 的加标签的话语数据集迭代地训练端到端网络,直到训练结果达到阈值。 将参照附图进一步解释当前公开的实施方式。所示出的附图不一定按比例绘制, 而是通常将重点放在示例当前公开的实施方式的原理上。 附图说明 [图1] 图1是例示了根据本发明的实施方式的用于多语言语音识别的方法的框图。 [图2] 图2是例示了根据本发明的实施方式的使用多语言端到端网络的语音识别模块的 框图。 [图3] 5 CN 111557029 A 说 明 书 3/18 页 图3是例示了根据本发明的实施方式的多语言语音识别模块中的神经网络的示意 图。 [图4] 图4是例示了根据本发明的实施方式的多语言语音识别系统的框图。 [图5] 图5是例示了根据本发明的实施方式的多语言语音识别模块中的神经网络的示意 图。 [图6] 图6是根据本发明的实施方式的训练多语言语音识别模块的数据准备过程。 [图7] 图7是根据本发明的实施方式的、根据多语言语音识别的指示作为话语中的语言 数量的函数的字符错误率的评估结果。 [图8] 图8例示出了根据本发明的实施方式的多语言语音识别的示例输出。











