
技术摘要:
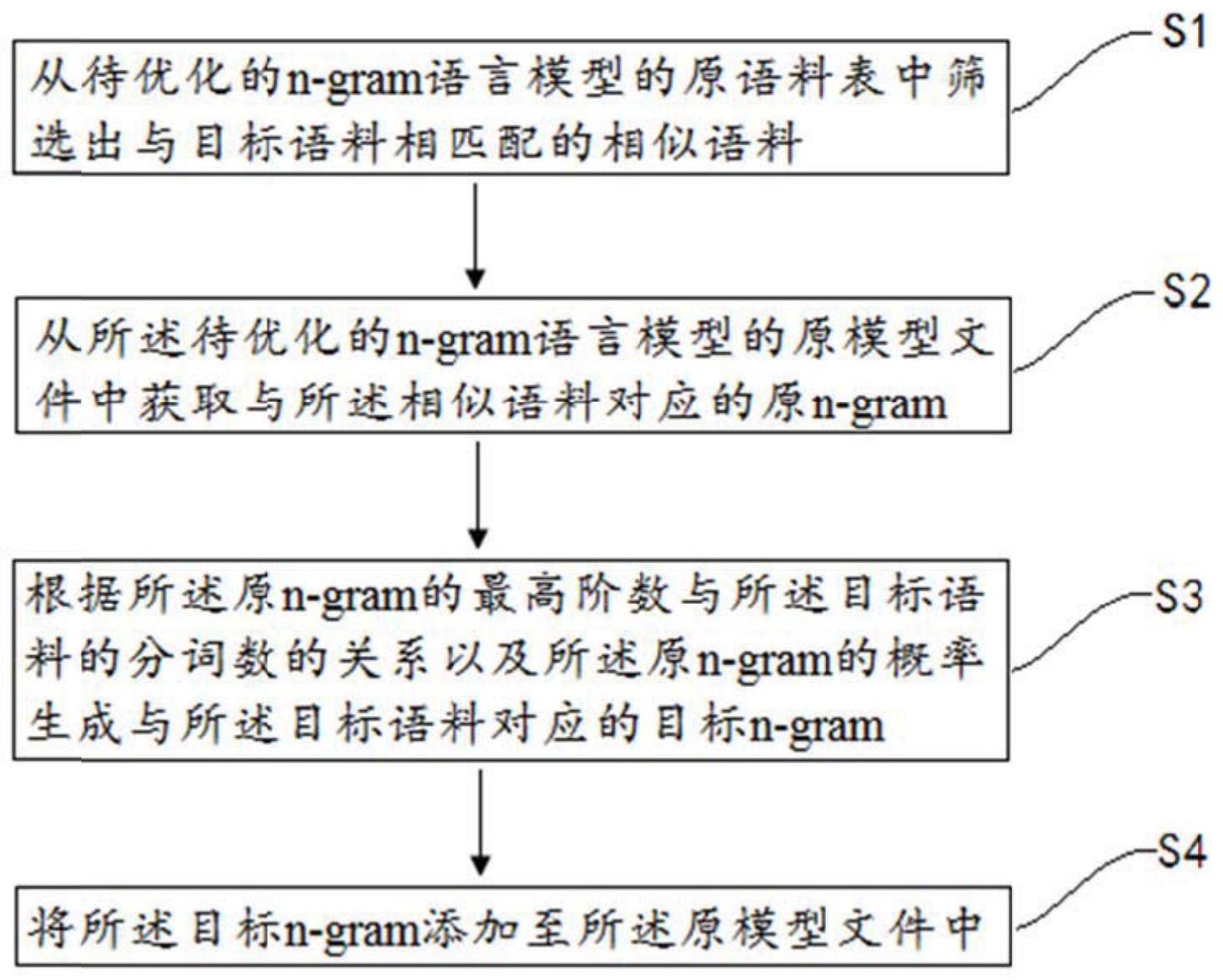
本发明公开了一种n‑gram语言模型的优化方法、装置、计算机设备及存储介质,该方法包括:从待优化的n‑gram语言模型的原语料表中筛选出与目标语料相匹配的相似语料;从待优化的n‑gram语言模型的原模型文件中获取与相似语料对应的原n‑gram;根据原n‑gram的最高阶数与 全部
背景技术:
在语音识别任务中,有两个重要的模型:声学模型和语言模型。语音解码的基本原 理为:通过声学模型给声学特征进行打分,并输出音素串的概率,通过语言模型给对应的文 本串进行打分。最后,结合两者的分数,给出概率最高的文本串作为识别结果。常见的公式 如下: 由此可见,语言模型对最终的解码结果起到非常重要的作用。目前使用最多的语 言模型是基于统计的n-gram语言模型。n-Gram是大词汇连续语音识别中常用的一种语言模 型实现的是音素到词的转化,词可以是中文词,也可以是英文。通常声学模型给出音素序列 的概率,语言模型通过统计词之间的概率,在音素序列上使用语言模型概率进行scale,使 得更符合语言习惯的词序列得以输出。 想要训练出较好的针对特定场景的语言模型通常需要大量的相关语料,然而现实 情况是,我们能够使用的训练语料大多是通用语料,要想找到大量的与场景相关的自然语 料是非常困难的。并且在一些场景中,往往有许多专有名词难以识别,虽然可以通过修改分 词词典及发音词典的方式来进行改善,但在训练语言模型的同时,声学模型也时需要进行 迭代才能实现较好的效果。但是,不断的修改词典,会导致词典越来越大,甚至有可能会影 响其他词的识别。 因此,如何提高n-gram语言模型对特定词汇的识别效果是目前需要解决的问题。
技术实现要素:
为了解决现有技术的问题,本发明实施例提供了一种n-gram语言模型的优化方 法、装置、计算机设备和存储介质,以克服现有技术中存在的特定场景中的一些特殊词汇难 以识别等问题。 为解决上述一个或多个技术问题,本发明采用的技术方案是: 第一方面,提供了一种n-gram语言模型的优化方法,该方法包括如下步骤: 从待优化的n-gram语言模型的原语料表中筛选出与目标语料相匹配的相似语料; 从所述待优化的n-gram语言模型的原模型文件中获取与所述相似语料对应的原 n-gram; 根据所述原n-gram的最高阶数与所述目标语料的分词数的关系以及所述原n- gram的概率生成与所述目标语料对应的目标n-gram; 4 CN 111583915 A 说 明 书 2/13 页 将所述目标n-gram添加至所述原模型文件中。 进一步的,所述从待优化的n-gram语言模型的原语料表中筛选出与目标语料相匹 配的相似语料包括: 利用预先训练的词向量模型分别对待优化的n-gram语言模型的原语料表中每条 语料以及目标语料进行向量化,获取所述原语料表中每条语料的词向量以及所述目标语料 的词向量; 根据所述原语料表中每条语料的词向量以及所述目标语料的词向量分别计算所 述目标语料与所述原语料表中每条语料的相似度; 从所述相似度中筛选出满足预设阈值的目标相似度,将所述原语料表中与所述目 标相似度对应的语料作为与所述目标语料相匹配的相似语料。 进一步的,所述根据所述原n-gram的最高阶数与所述目标语料的分词数的关系以 及所述原n-gram的概率生成与所述目标语料对应的目标n-gram包括: 对所述目标语料进行分词处理,获取分词结果,并获取所述目标语料的分词数; 判断所述目标语料的分词数是否大于所述原n-gram的最高阶数; 若是,则将所述分词结果拆分为分词数与所述原n-gram的最高阶数相同的目标分 词结果,否则,直接将所述分词结果作为目标分词结果; 将所述原n-gram中的词组替换成所述目标分词结果,生成目标n-gram,并根据所 述原n-gram的概率确定所述目标n-gram的概率。 进一步的,所述根据所述原n-gram的概率确定所述目标n-gram的概率包括: 获取与所述目标n-gram同阶的原n-gram的概率作为所述目标n-gram的概率。 进一步的,所述根据所述原n-gram的概率确定所述目标n-gram的概率还包括: 获取与所述目标n-gram同阶的原n-gram的概率,并根据相应的目标相似度确定所 述目标n-gram的权重值,根据所述原n-gram的概率以及所述目标n-gram的权重值计算得到 所述目标n-gram的概率。 进一步的,在将所述目标n-gram添加至所述原模型文件中前,所述方法还包括: 判断所述原模型文件中是否存在所述目标n-gram; 若存在,则获取所述原模型文件中与目标n-gram对应的n-gram的概率,否则,直接 将所述目标n-gram添加至所述原模型文件中; 判断所述目标n-gram的概率是否大于所述原模型文件中与目标n-gram对应的n- gram的概率,若是,则使用所述目标n-gram替换所述原模型文件中与所述目标n-gram对应 的n-gram。 第二方面,提供了一种n-gram语言模型的优化装置,所述装置包括: 语料匹配模块,用于从待优化的n-gram语言模型的原语料表中筛选出与目标语料 相匹配的相似语料; n-gram获取模块,用于从所述待优化的n-gram语言模型的原模型文件中获取与所 述相似语料对应的原n-gram; n-gram生成模块,用于根据所述原n-gram的最高阶数与所述目标语料的分词数的 关系以及所述原n-gram的概率生成与所述目标语料对应的目标n-gram; 文件添加模块,用于将所述目标n-gram添加至所述原模型文件中。 5 CN 111583915 A 说 明 书 3/13 页 进一步的,所述语料匹配模块包括: 向量生成单元,用于利用预先训练的词向量模型分别对待优化的n-gram语言模型 的原语料表中每条语料以及目标语料进行向量化,获取所述原语料表中每条语料的词向量 以及所述目标语料的词向量; 相似度计算单元,用于根据所述原语料表中每条语料的词向量以及所述目标语料 的词向量分别计算所述目标语料与所述原语料表中每条语料的相似度; 语料筛选单元,用于从所述相似度中筛选出满足预设阈值的目标相似度,将所述 原语料表中与所述目标相似度对应的语料作为与所述目标语料相匹配的相似语料。 第三方面,提供了一种计算机设备,包括存储器、处理器及存储在存储器上并可在 处理器上运行的计算机程序,所述处理器执行所述计算机程序时实现如下步骤: 从待优化的n-gram语言模型的原语料表中筛选出与目标语料相匹配的相似语料; 从所述待优化的n-gram语言模型的原模型文件中获取与所述相似语料对应的原 n-gram; 根据所述原n-gram的最高阶数与所述目标语料的分词数的关系以及所述原n- gram的概率生成与所述目标语料对应的目标n-gram; 将所述目标n-gram添加至所述原模型文件中。 第四方面,提供了一种计算机可读存储介质,其上存储有计算机程序,所述计算机 程序被处理器执行时,实现如下步骤: 从待优化的n-gram语言模型的原语料表中筛选出与目标语料相匹配的相似语料; 从所述待优化的n-gram语言模型的原模型文件中获取与所述相似语料对应的原 n-gram; 根据所述原n-gram的最高阶数与所述目标语料的分词数的关系以及所述原n- gram的概率生成与所述目标语料对应的目标n-gram; 将所述目标n-gram添加至所述原模型文件中。 本发明实施例提供的技术方案带来的有益效果是: 1、本发明实施例提供的n-gram语言模型的优化方法、装置、计算机设备和存储介 质,通过从待优化的n-gram语言模型的原语料表中筛选出与目标语料相匹配的相似语料, 然后从所述待优化的n-gram语言模型的原模型文件中获取与所述相似语料对应的原n- gram,再根据所述原n-gram的最高阶数与所述目标语料的分词数的关系以及所述原n-gram 的概率生成与所述目标语料对应的目标n-gram,最后将所述目标n-gram添加至所述原模型 文件中,实现在不改变声学模型及发音词典的基础上,快速优化了原有n-gram语言模型对 目标语料的识别效果; 2、本发明实施例提供的n-gram语言模型的优化方法、装置、计算机设备和存储介 质,通过根据所述原语料表中每条语料的词向量以及所述目标语料的词向量分别计算所述 目标语料与所述原语料表中每条语料的相似度,提高了计算原语料表中的语料与目标语料 的相似度的效率以及准确率; 3、本发明实施例提供的n-gram语言模型的优化方法、装置、计算机设备和存储介 质,通过获取与所述目标n-gram同阶的原n-gram的概率,并根据相应的目标相似度确定所 述目标n-gram的权重值,根据所述原n-gram的概率以及所述目标n-gram的权重值计算得到 6 CN 111583915 A 说 明 书 4/13 页 所述目标n-gram的概率,从而使得不同的相似语料的权重不同,保证了n-gram语言模型的 区分性。 附图说明 为了更清楚地说明本发明实施例中的技术方案,下面将对实施例描述中所需要使 用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于 本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他 的附图。 图1是根据一示例性实施例示出的n-gram语言模型的优化方法的流程图; 图2是根据一示例性实施例示出的从待优化的n-gram语言模型的原语料表中筛选 出与目标语料相匹配的相似语料的流程图; 图3是根据一示例性实施例示出的根据原n-gram的最高阶数与目标语料的分词数 的关系以及原n-gram的概率生成与所述目标语料对应的目标n-gram的流程图; 图4是根据一示例性实施例示出的n-gram语言模型的优化装置的结构示意图; 图5是根据一示例性实施例示出的计算机设备的内部结构示意图。











