
技术摘要:
本发明公开了一种基于RGBD相机的多人三维姿态估计方法,该方法首先在真实人体数据集上,训练得到一个支持人体位置检测和语义分割的深度卷积网络;然后构建一个虚拟合成的人体深度图‑三维特征点数据集,通过该数据集训练得到能够从深度图中估计人体关节点的深度卷积网 全部
背景技术:
人体姿态估计的目的是从输入图像中得到人体关节点的坐标,从而可以分析出人 体关节方向、旋转等信息。人们还可以进一步地考虑时间序列的信息,观察一段时间内人体 关节点的位置变化情况,进行更抽象层次的语义理解,从而实现动作识别、跟踪、预测等复 杂的任务。人体姿态估计应用十分广泛,它常常被运用于游戏、娱乐、安防、医疗康复等领 域。利用人体姿态估计的结果,人们不需要任何体感设备便可以感受体感游戏和人机交互 的乐趣;电影厂商不需要额外辅助设备便可以驱动动画模型,完成便捷的动作序列生成;儿 女也不再需要担心家中的老年人摔倒,却因信息通知不及时而错过送医救治的宝贵时间的 意外情况。 人们对于人体姿态估计的问题已经有了很久的研究历史。早期的方法大多数都是 在几何先验的基础上,识别人体的各个部分来进行匹配,从而计算出人体姿态。近年来,随 着深度学习的迅速发展,卷积神经网络在计算机视觉方向的很多领域,如物体分类、物体检 测、语义分割等任务上都取得了突破性的进展。同样人们利用深度学习的方法,在人体姿态 估计的领域也获得了巨大的突破。很多基于卷积神经网络的人体姿态估计的方法都被提 出,如DeepPose,Stacked Hourglass Networks,OpenPose等。相比于传统的视觉方法,这些 方法通常是由大量数据训练的,可以利用数据中蕴含的丰富的先验信息,所以在精度上和 稳定性上有了很大的提升。 由于目前大部分公开的数据集的输入都是彩色的RGB图像,所以目前大部分对于 姿态估计的研究仅仅局限在二维的关节点的估计。不过,二维的关节点在应用领域上存在 较大的局限性。比如二维关节点很难计算人体各个关节的平移、旋转信息,无法胜任很多涉 及三维相关的场景。所以,人们其实对于三维人体姿态估计的研究有着相当迫切的需求。 要从传统的RGB图像中得到三维关节点的估计是一件非常困难的事情。深度相机 的诞生,却给了人们提供了解决该问题的新思路,深度相机可以获得物体的深度值,从而对 物体的距离信息有了感知。2009年,第一个大众普及的深度相机Kinect由微软推出,它具有 人体姿态动态捕捉等功能。Kinect辅助了相应的Xbox360游戏平台,进一步拓展了游戏的操 作模式,充分展现出了人机互动的概念。2017年,随着首个配备深度相机的手机IPhone X发 布,深度相机集成到移动手机上也将慢慢成为一个趋势。因此基于RGBD相机的人体姿态估 计方法将具有更佳的便捷性和普及性。
技术实现要素:
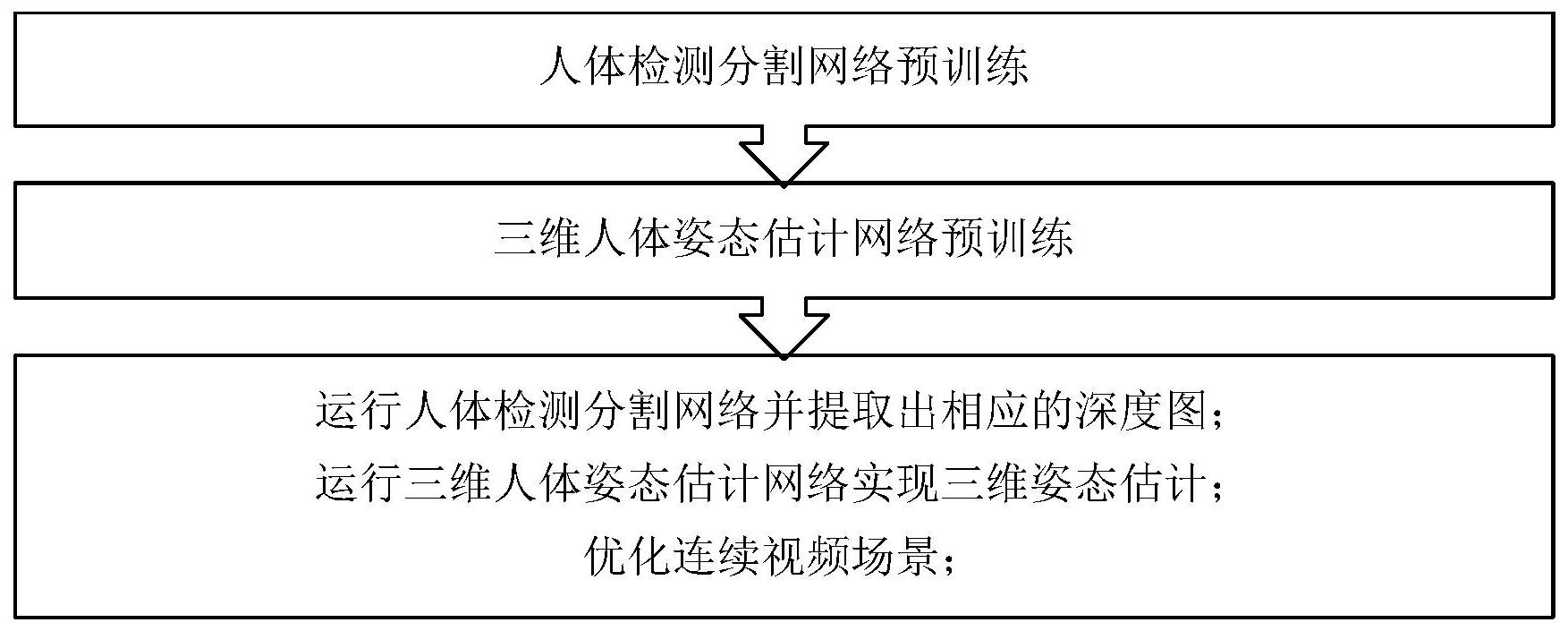
本发明的目的在于针对现有技术的不足,提供一种基于RGBD相机的多人三维姿态 估计方法。本发明用于解决用户从RGBD图片输入中自动获得人体关节点坐标的问题。 4 CN 111597976 A 说 明 书 2/8 页 本发明的目的是通过以下技术方案来实现的:一种基于RGBD相机的多人三维姿态 估计方法,包括以下步骤: (1)人体检测分割网络预训练:根据真实人体RGB图片数据集以及对应的标注信 息,训练得到支持人体位置检测和语义分割的深度卷积网络; (2)三维人体姿态估计网络预训练:通过构建一个合成的人体深度图-三维特征点 数据集,然后通过该数据集训练得到能够从深度图中估计人体关节点的深度卷积网络三维 人体姿态估计网络; (3)用户实际使用过程:当输入待处理RGBD图片时,运行步骤(1)训练得到的人体 检测分割网络并提取出相应的深度图,运行步骤(2)训练得到的三维人体姿态估计网络对 人体进行三维关节点的估计,得到所有人体三维关节点的世界坐标;当输入连续视频场景 时,利用多帧图像信息的关联,使用贝叶斯方法和指数平滑的方式改善人体的三维关节点 的世界坐标的预测结果。 进一步地,所述步骤(1)具体为:根据输入图片以及对应的标注信息,训练支持人 体位置检测和语义分割的深度卷积网络,其输入为RGB图片,输出为人体所在位置的包围盒 和人体区域掩膜。 进一步地,所述多任务深度卷积网络由三个子网络构成,具体为:第一个子网络为 特征金字塔网络,通过输入RGB图片,进行多层次多尺度的卷积相关操作,提取出图片的抽 象特征;第二个子网络为区域候选网络,输入为第一个子网络输出的抽象特征,通过卷积相 关操作,生成人体位置的候选框;第三个子网络为全卷积神经网络,输入为第二个子网络输 出的人体位置候选框内的抽象特征,通过卷积相关操作,生成人体区域掩模。 进一步地,所述步骤(2)包括以下子步骤: (2.1)构建一个合成的人体深度图-三维特征点数据集具体为:自动合成若干三维 人体模型,并将三维人体模型和人体动作骨骼数据绑定,通过蒙皮操作获得具有不同人体 不同动作的三维人体模型,最后通过对所有三维人体模型进行深度图的绘制,获得人体深 度图-三维特征点数据集; (2.2)通过人体深度图-三维特征点数据集训练得到能够从深度图中估计人体关 节点的深度卷积网络具体为:根据人体深度图-三维特征点数据集的标注信息,训练一个三 维人体姿态估计网络,其输入为单通道的深度图片,输出包括人体三维关节点的xy热图和z 距离响应图;三维人体姿态估计网络的基本结构是堆叠沙漏型网络,通过多次下采样和上 采样的操作,利用卷积模块反复提取特征,最后输出两种输出图。 进一步地,所述步骤(3)包括两种情况: (3.1)当输入待处理RGBD图片时,运行步骤(1)训练得到的人体检测分割网络并提 取出相应的深度图,然后运行步骤(2)训练得到的三维人体姿态估计网络对人体进行三维 关节点的估计,得到所有人体三维关节点的坐标,具体为:用户输入单幅RGBD图像,首先提 取其中的RGB图片,运行所述人体检测分割网络得到人体所在位置和人体分割掩模;利用提 取出的单人深度图像,估计出每个人相应的三维关节点局部坐标,根据相机参数以及各个 局部坐标之间的关联,获得图像中人体的三维关节点的世界坐标; (3 .2)当输入连续视频场景时,根据步骤(3.1)得到前一帧中人体三维关节点坐 标,然后根据前一帧的人体三维关节点坐标构造当前帧该人体三维关节点坐标的先验概率 5 CN 111597976 A 说 明 书 3/8 页 分布,再利用贝叶斯公式优化当前帧该人体三维关节点的xy热图,利用指数平滑优化当前 帧该人体三维关节点的z距离响应图,最后获得当前帧优化后的人体三维关节点坐标。 本发明的有益效果是:本发明给出了从单个RGBD相机恢复多人三维姿态的鲁棒算 法;在网络预训练阶段,只需要预标注好的RGB图片(公开数据集中可以非常容易得到)即 可,而对于深度图可以使用虚拟合成的方法自动得到,因此预训练对数据标注的需求度很 小;在实际运行阶段,同时考虑单帧姿态估计和多帧姿态估计,可以输出精确同时稳定的多 人三维姿态。 附图说明 图1是基于RGBD相机的多人三维姿态估计方法的流程示意图; 图2是虚拟合成的带有不同动作的三维人体模型示意图; 图3是堆叠沙漏型网络结构示意图; 图4是四阶沙漏模块结构示意图; 图5是姿态估计网络输出示意图;其中,(a)为深度输入图,(b)为xy热图,(c)为z距 离响应图; 图6是从输入RGBD图片到输出三维姿态的运行流程可视化图; 图7是本发明的具体实施例结果图;其中,(a)为输入RGB图像示意图及人体包围 盒,(b)为输入深度图像叠加二维姿态估计结果示意图,(c)为输出的三维姿态骨骼结果示 意图。











