
技术摘要:
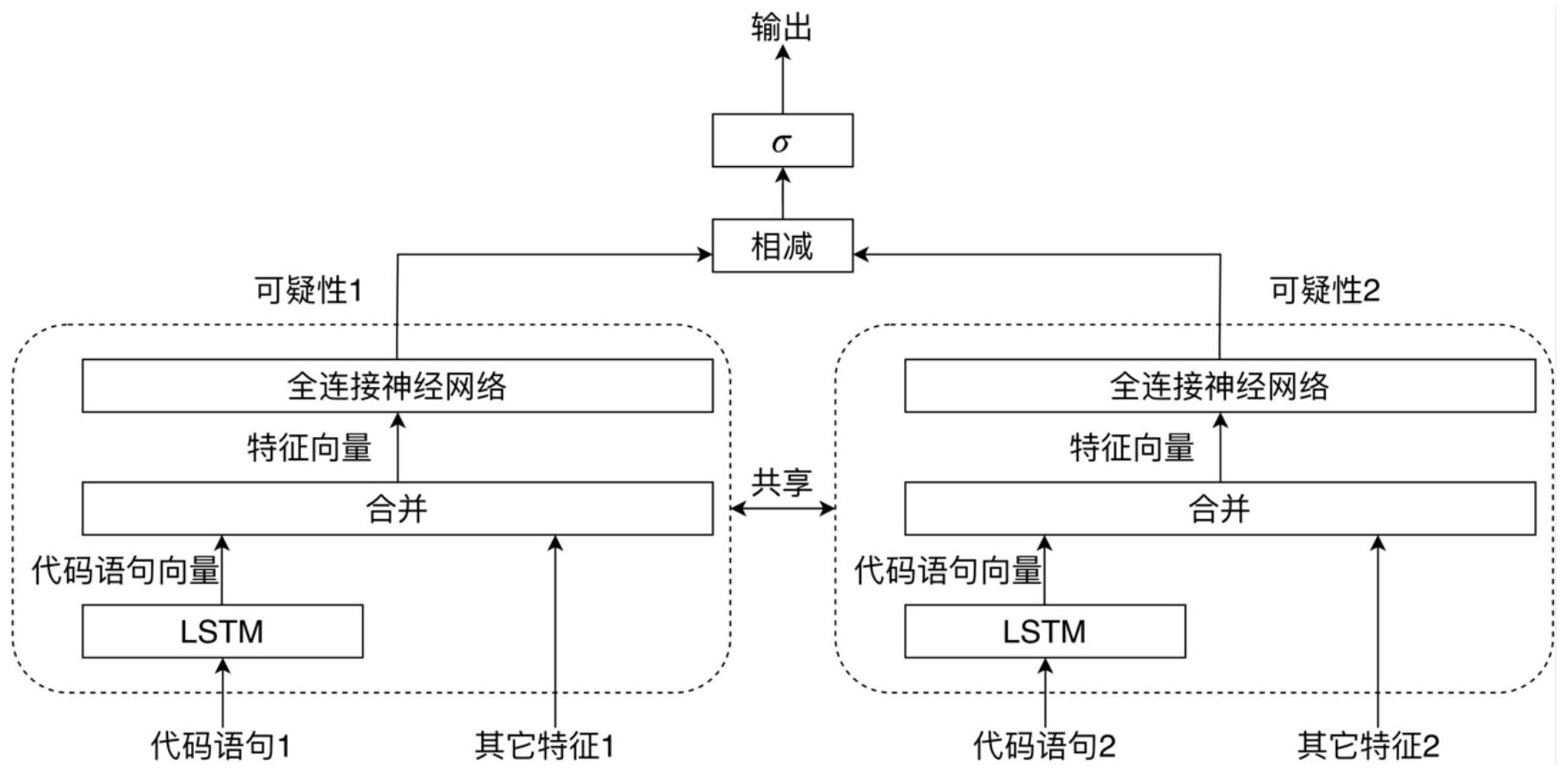
本发明提供一种基于RankNet的混合软件错误定位方法及系统,该方法包括:S1.RankNet排序模型的训练:所述RankNet排序模型自动提取代码语句的文本特征,再将所述文本特征与代码语句的数值特征结合并输入RankNet排序模型进行排序学习;S2.利用训练好的RankNet排序模型进行 全部
背景技术:
随着计算机硬件的不断发展与普及,计算机软件也变得更庞大和更消耗资源。正 如安迪比尔定律指出,硬件提高的性能,很快被软件消耗掉了。企业或者科研机构在开发软 件过程中,通常使用测试驱动开发(Test-Driven Development,TDD)方法,即在编写功能代 码之前先编写测试代码,再编写使测试用例通过的功能代码,通过测试来驱动整个开发的 进行。TDD的方法可以编写出简洁高效的代码,并加速开发过程。在TDD的过程中,每当执行 测试用例失败,即软件出现了故障,则需要开发人员对软件进行调试、错误定位和修复。当 软件功能代码简单,代码量少时,开发者可以根据软件在执行测试用例期间的行为表现和 输出,快速定位到错误所在并解决错误。可是在庞大复杂的软件代码面前,手动定位软件错 误犹如大海捞针,费时费力。如果可以在调试的过程中能够根据软件的相关信息来自动定 位软件的错误,那么开发者只需要专注于软件错误的修复,可以大大减少开发人员的调试 时间,节约软件的开发成本。因此如何能够根据软件运行时的信息和行为表现,快速精确地 定位到软件的错误,具有重要的经济价值和意义。 为了保证软件开发的质量,工业界在软件测试阶段投入了大量的人力物力。据统 计,软件错误的定位和修复占据整个开发和更新过程开销的50%到80%,美国国家标准技 术研究所(National Institute of Standards and Technology,NIST)在2002年的一份报 告中指出,软件错误每年给美国经济造成595亿美元的损失(占美国GDP的0.6%)。到目前为 止,软件错误带来的损失无疑是增加了。此外,对于医疗、航空和交通等安全至关重要的大 型软件,其中的错误会导致非常严重的后果。例如20世纪80年代控制Threac-25放射治疗仪 的代码中的错误直接导致了患者的死亡;1996年机载指导计算机中的错误导致了Ariane 5 火箭发射不到一分钟后就被摧毁等等。 手动进行软件错误定位非常依赖于软件开发人员的直觉与经验,他们根据软件的 行为表现分析和判断哪些代码更有可能导致了软件出错,然后再对错误软件进行修复。随 着软件规模和复杂性的增加,软件更加容易出现错误,并且错误带来的损失也更加巨大。 如果可以自动化软件的错误定位,直接列出导致运行测试用例失败的代码,那么 开发人员就只需要把注意力集中于错误的修复,可以很大程度上降低调试的开销。目前自 动化软件错误定位的相关研究还不够成熟,根据分析过程中使用的信息类型,主要分为动 态软件错误定位和静态软件错误定位。研究者提出的软件错误定位方案多数基于手动提取 软件的静态或者动态信息的特征,结合基于频谱的软件错误定位技术的风险评估公式计算 的程序元素可疑性,或者使用学习排序的方法进行错误定位。 专利CN103995780A公开了一种基于语句频度统计的程序错误定位方法,该方法对 已有的Tarantula错误定位方法进行分析与改进,在原来的方法基础上考虑了语句的具体 4 CN 111581086 A 说 明 书 2/6 页 执行频度,然后将频度映射为0~1之间的数,提出了基于语句频度的错误定位方法。本发明 充分考虑了语句的具体执行频度而不是统计语句在每次执行时的覆盖情况。只要某两条语 句对应的测试用例语句频度不同,那么它们的可疑度值就会不同。该方法也是属于基于程 序频谱的软件错误定位方法,需要将语句频度映射为0~1之间的数,作为可疑度值得权值, 但是映射函数需要人工选择,执行频度与覆盖情况之间的比较需要衡量,并且不同场景的 错误定位可能需要不同的映射函数。由于同一个基本块中的代码具有相同的频谱,最终通 过该方法还是会得到相同的可疑性,因此很难在代码语句的级别对软件进行错误定位。 专利CN106886490A公开了一种基于失效轨迹的程序错误定位方法。本发明通过挑 选一个合适的失效测试用例的执行谱即失效轨迹,再根据已有的基于频谱的软件错误定位 方法的特定模型计算出语句可疑度序列在失效轨迹中的投影,按照语句可疑度大小从大到 小一次排查错误语句。本发明通过失效轨迹中选取函数值最小的失效轨迹作为关键失效轨 迹,将传统错误定位报告中的语句可疑度排序序列投影到关键失效轨迹上,最终提高错误 定位的效果。该方法也是基于程序频谱的软件错误定位方法,没有解决相同基本块中代码 具有相同可疑性的问题,并且已有研究表明,没有任何一种基于软件频谱的错误定位方法 是可以适用于所有的错误定位场景。 专利CN106951372A公开了一种基于变量切片和关联规则的软件错误定位方法。本 发明针对软件测试中错误定位效率低的问题,首先将JAVA程序语句进行变量切片,将所有 变量切片信号信息作为事物数据库,然后利用关联分析得到关联规则集合,根据置信度和 支持度由高到低的排列顺序,生成检查语句优先级次序;最后根据语句优先级次序越靠前 越优先这检查的原则定位错误出现的具体位置。该方法使用了代码内容的信息,结合静态 程序切片对软件进行错误定位,但是对大型软件生成静态程序切片,会带来一定时间上的 开销。而且本发明使用的评测数据集的错误类型为植入错误,与真实的软件错误之间存在 一定的差异性。 专利CN109857675A公开了一种利用语句类型的程序错误定位方法,根据每一个程 序语句进行语句类型系数计算,并且结合基于频谱的软件错误定位方法计算每条程序语句 的可疑度,对每条语句的可疑度从大到小排序,获取错误语句的可疑排名。该方法结合了代 码本身的内容,可以在一定程度上提高错误定位的准确度,但是系数的计算依据存在一定 的局限性,只考虑了分支条件或循环条件语句,其它语句类型则都归结于其它类型语句,因 此对错误定位准确度的提高有限。 总而言之,现有的关于混合错误定位方法主要是手动提取代码语句的特征,再利 用该提取的特征计算代码语句可疑性的权重系数,然后用权重系数与可疑性进行组合,计 算最终的可疑性。由于手动提取的特征存在一定的局限性,而且计算的权重系数很难在静 态特征和动态特征之间衡量,但是依然存在错误定位的准确度较低等问题。
技术实现要素:
为解决上述问题,本发明提出一种基于RankNet的混合软件错误定位方法及系统, 其能快速精确地自动定位到软件的错误,大大增强了错误定位方法的自适应性,而且减少 了由人为设定参数带来的局限性和不确定性。 本发明提出一种基于RankNet的混合软件错误定位方法,包括:S1.RankNet排序模 5 CN 111581086 A 说 明 书 3/6 页 型的训练:所述RankNet排序模型自动提取代码语句的文本特征,再将所述文本特征与代码 语句的数值特征结合并输入RankNet排序模型进行排序学习;S2.利用训练好的RankNet排 序模型进行代码语句排序,得到可疑代码语句列表来进行软件错误定位。 本发明还提供一种基于RankNet的混合软件错误定位系统,包括:包括存储器、处 理器及存储在所述存储器上并可在所述处理器上运行的计算机程序,所述计算机程序被所 述处理器执行时实现如上所述的基于RankNet的混合软件错误定位方法。 本发明的有益效果:利用RankNet排序模型自动提取代码语句的文本特征(即:静 态特征),再和数值特征进行结合,使用学习排序算法自动对这些特征进行学习排序,计算 代码语句最终的可疑性,大大增强了软件错误定位方法的自适应性,降低了软件开发人员 调试的时间,为科研机构或者企业节省了开发成本,而且减少了由人为设定参数带来的局 限性和不确定性。RankNet排序模型为同一个基本块中的文本信息分别计算一个不同的可 疑性,解决了同一个基本块之间代码语句可疑性相同的问题,提高了软件错误定位的准确 度。 附图说明 图1为本发明实施例中基于RankNet的混合软件错误定位系统结构图。 图2为本发明实施例中子网络结构图。 图3为本发明实施例中代码语句的统计特征。 图4为本发明实施例中代码语句的类型。











