
技术摘要:
本公开提供了一种一种分布式数据处理系统、分布式计算任务部署系统及方法。所述分布式数据处理系统,用于在所述多个计算设备上对数据进行并行处理,每个计算设备包含前向数据处理组件和后向数据处理组件,其中至少一个计算设备含有其他计算设备不具有的一个模型参数组 全部
背景技术:
随着机器学习的发展以及人工神经网络的研究的逐步深入,深度学习的概念得到 广泛的关注和应用。深度学习是一种特殊的机器学习,它采用网状层级结构来表达所学习 的对象,通过简单概念来组合成抽象概念,通过简单概念计算来实现抽象的概念表达。目 前,深度学习在图像识别、语音识别以及自然语言处理领域有了长足的进展。深度学习涉及 的模型参数多,导致计算量巨大,而且训练数据的规模大,因此需要消耗较多的计算资源等 特点。 当前,无论是通用处理器GPU还是专用芯片TPU 相对于CPU 都强大了许多倍,但现 实应用对计算力的渴求是无止境的,从业者需要以更快的速度,以更大规模的模型处理更 大规模的数据,这单靠一个硬件设备无法满足。硬件的发展要受限于制造工艺(芯片面积, 功耗,时钟信号传播范围)的限制,不可能无限制的提高一颗芯片的处理能力。因此,人们常 常通过高速互联技术把多个高通量的设备连接在一起,协同完成大规模任务。一种常见的 GPU 集群架构,同一个节点(服务器)内部的GPU 通过NVLink或者PCIe 通信,多个节点通过 高速以太网或者无限带宽(Infiniband)互联。Google 内部 TPU Cloud的硬件部署中每个 服务器管理若干个TPU,多个服务器通过高速互联技术连成大规模集群。 为此,本领域技术人员提出了数据并行。这样把数据分成多份,每个设备处理一 份,这样每个设备只需要处理整体数据的一小部分即可,系统运行时间从一个设备处理所 有数据需要的时间降低到一个设备处理一小部分数据需要的时间,从而得到加速,这是大 数据场景最常见的并行方式。数据并行特别适合卷积神经网络这种场景,卷积神经网络的 模型由很多小的卷积核构成,模型体积小,从而设备间同步模型梯度时通信量较小。当前, 所有框架都能很好的支持这种并行模式。 但是,现有的数据并行处理在进行分布式深度学习训练时,在将一个批次的数据 分割放置在各个计算设备上进行计算,即每个计算设备使用不同的输入数据执行相同的计 算流程时,还需要将模型参数镜像的放置在各个计算设备上,并将每个设备计算出的梯度 进行聚合,更新参数。目前最主流的梯度聚合方式是AllReduce,即将每个计算设备上产生 的梯度Reduce到一起再Broadcast到每个计算设备上去,每个计算设备得到相同的聚合后 的梯度,再进行参数更新。注意这种情况下,每个计算设备上面执行的参数更新计算将是完 全相同的,所以更新后每个计算设备上面的参数也将继续保存一致。与维护模型参数对应, 还需要维护更新组件(Optimizer)的参数用于模型参数更新,比如Adam Optimizer需要维 护数据量和模型参数相同的两个参数m与v,加上梯度,Adam进行参数更新时一共会涉及到4 倍于模型参数大小的内存(模型参数,梯度,梯度的一阶矩(m),梯度的一阶矩(v)),这种情 况下假如使用N个计算设备进行数据并行训练,那么参数更新部分的计算将重复N次,同时 5 CN 111597055 A 说 明 书 2/10 页 将需要 N×4×模型大小的设备内存完成参数更新。训练深度学习模型时,一个设备上的前 向和后向计算可以独立开展,但每个模型上获得模型的更新梯度后需要在设备间同步,聚 合成完整的一个批次数据的梯度之后再做模型参数更新。 而深度学习常用的计算设备通常有CPU、GPU、FPGA以及ASIC(专用集成电路)等,可 以将GPU、FPGA以及ASIC统称为数据加速处理设备,数据加速处理设备往往具有更快的计算 速度和更高的内存带宽,但是其内存容量往往存在内存有限、单价高昂、不易扩展等问题, 如果一味地增加数据加速处理设备的内存容量来满足大规模模型的训练,将为企业带来高 企的成本。很显然,现有的数据并行中重复的计算和内存来源于分布式的训练中参数和 Optimizer也是分布式的(Distributed)放置于各个计算设备上面的,这一方面无疑会提高 计算设备内存资源的占用,另一方面也必然导致设备间参数同步的传输开销。对于目前计 算设备尤其是内存资源昂贵的GPU这种计算设备而言,是一个巨大浪费。 因此,人们期望获得一种用于分布式数据处理系统或一种分布式计算任务的部署 系统,其能够降低在数据并行处理过程中计算设备内存与计算资源的浪费。
技术实现要素:
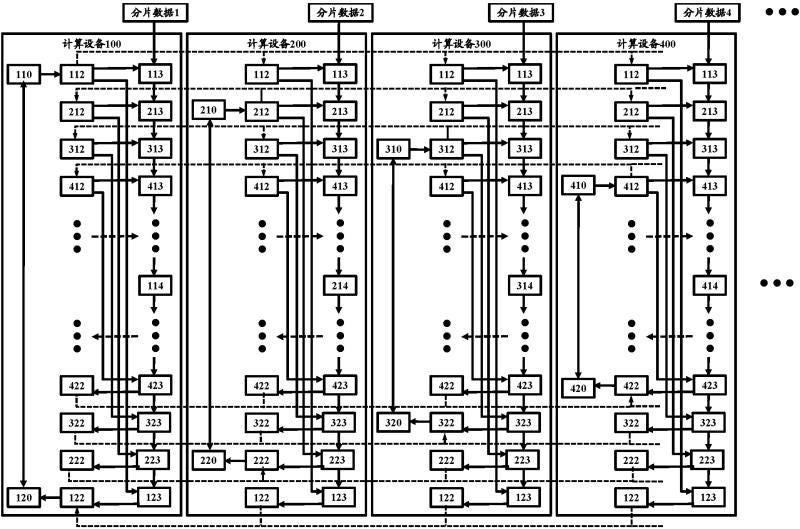
为此,本发明的目的是解决至少上述问题之一。根据本公开的一个方面,提供了一 种分布式数据处理系统,用于在多个计算设备上对数据进行并行处理,每个计算设备包含 前向数据处理组件和后向数据处理组件,其中至少一个计算设备含有其他计算设备不具有 的一个模型参数组件以及与一个所述模型参数组件对应的模型参数更新组件,所述模型参 数组件通过与其对应的广播组件将所述模型参数组件含有的一组将被并行处理的数据所 使用的模型参数输入到其他计算设备的广播组件,以及所述模型参数更新组件从与所述模 型参数更新组件对应的梯度汇聚组件获取对应的全局梯度值进行更新处理。 根据本公开的分布式数据处理系统,其中每个计算设备的广播组件将模型参数输 入到对应的前向数据处理组件执行前向数据处理和输入到后向数据处理组件执行后向数 据处理。 根据本公开的分布式数据处理系统,其还包括:一个或多个串联在所述模型参数 组件和其对应的广播组件之间的多个运算任务组件,所述多个运算任务组件中每一个运算 任务组件为单输入与单输出的运算任务组件;以及一个或多个串联在所述模型参数更新组 件和其对应的梯度汇聚组件之间的多个运算任务组件,所述多个运算任务组件中每一个运 算任务组件为单输入与单输出的运算任务组件。 根据本公开的分布式数据处理系统,其中与所述模型参数组件相连的所述广播组 件将模型参数组件中的模型参数输入到所述模型参数组件所在计算设备上的与所述模型 参数组件对应的前向运算组件和后向运算组件,并且还输入到其他并行计算设备上的并行 广播组件,以便该并行广播组件将所接收到的模型参数输入到并行的前向运算组件和后向 运算组件。 根据本公开的另一个方面,提供了一种分布式数据处理方法,包括:将待处理数据 按照分布式数据处理架构的计算设备的数量分片成多个分片数据发送到各个计算设备,执 行前向数据处理和后向数据处理,将模型参数集合划分成多个子集,将一个子集分布到一 个计算设备上的模型参数组件;一个模型参数组件将自身维护的参数通过与其相连的一个 6 CN 111597055 A 说 明 书 3/10 页 广播组件发送到各个并行处理分片数据的其他计算设备的对应一个广播组件,以便各个其 他计算设备上的前向数据处理组件和后向数据处理组件基于所接收模型参数对分片数据 进行处理。 根据本公开的分布式数据处理方法,还包括:连接到所述模型参数组件的广播组 件所对应的一个梯度汇聚组件获取其他计算设备上对应的梯度汇聚组件发送来的梯度值, 从而获取全局梯度值,并传输到与该模型参数组件对应的一个模型参数更新组件,以便模 型参数更新组件进行模型参数更新处理。 根据本公开的另一个方面,提供了一种分布式计算任务部署系统,包括:作业描述 组件,基于作业类型描述作业神经网络模型以及获取将要处理作业的计算资源,所述计算 资源包括多个可执行并行计算的计算设备,并为将要进行并行运算的作业数据的分片数据 所属的前向运算任务节点、广播节点、后向运算任务节点以及梯度汇聚节点给出所属计算 设备的位置标签;模型参数节点配置组件,基于作业神经网络模型的描述,获取处理作业的 模型参数,计算所有模型参数的总量,并负载均衡地将所有模型参数划分到几个模型参数 节点,其中一个模型参数节点只被配置到一个计算设备上,并经由广播节点置于所述神经 网络模型中该模型参数节点的后继前向运算任务节点之前;以及模型参数更新节点配置组 件,与每个模型参数节点相对应,配置一个更新组件节点,其中一个模型参数更新节点只被 配置在一个计算设备上,并连接到与该模型参数节点的对应广播节点对应的梯度汇聚节点 之后,而所述梯度汇聚节点布置在与该模型参数节点的对应运算任务节点相对应的后向运 算任务节点之后。 根据本公开的分布式计算任务的部署系统,还包括:单一后继运算任务节点配置 组件,遍历所述模型参数节点的每个后继前向运算任务节点,为仅消费所述模型参数节点 输出并仅具有单一输出的单一后继前向运算任务节点配置与所述模型参数节点相同的位 置标签,并在所述模型参数节点和对应的广播节点之间串联前向运算任务节点,以及在与 所述模型参数节点对应的模型参数更新节点和与广播节点相对应梯度汇聚节点之间配置 与所述单一后继前向运算任务节点对应的后向运算任务节点。 根据本公开的又一个方面,还提供了一种分布式计算任务部署方法,包括:基于作 业类型描述作业神经网络模型以及获取将要处理作业的计算资源,所述计算资源包括多个 可执行并行计算的计算设备,并为将要进行并行运算的作业数据的分片数据所属的前向运 算任务节点、广播节点、后向运算任务节点以及梯度汇聚节点赋予所属计算设备的位置标 签;基于作业的神经网络模型,获取处理作业的模型参数,计算所有模型参数的总量,并负 载均衡地将所有模型参数划分成多个部分,配置对应数量的模型参数节点,并为一个模型 参数节点配置一个计算设备的位置标签;在每个模型参数节点及其后继前向运算任务节点 之间插入广播节点,并配置相同的位置标签;为与一个模型参数节点相对应的一个模型参 数更新节点赋予与该模型参数节点相同的计算设备的位置标签;以及在所述模型参数更新 节点与对应的后向运算任务节点之间插入与所插入的广播节点对应的梯度汇聚节点,并配 置相同的位置标签。 根据本公开的分布式计算任务的部署方法,还包括:遍历所述模型参数节点的每 个后继前向运算任务节点,将仅消费所述模型参数节点输出并仅具有单一输出的单一后继 前向运算任务节点配置的位置标签修改为与所述模型参数节点相同的位置标签,并将修改 7 CN 111597055 A 说 明 书 4/10 页 了位置标签的前向运算任务节点串联在所述模型参数节点与其对应的广播节点之间;以及 修改与所述单一后继前向运算任务节点对应的后向运算任务节点的位置标签为与所述模 型参数节点相同的位置标签,并将修改了位置标签的后向运算任务节点串联到所述模型参 数更新节点和梯度汇聚节点之间。 根据本公开的又一个方面,还提供了一种分布式计算任务部署方法,包括:基于作 业类型描述作业神经网络模型以及获取将要处理作业的计算资源,所述计算资源包括多个 可执行并行计算的计算设备,并为将要进行并行运算的作业数据的分片数据所属的前向运 算任务节点赋予所属计算设备的位置标签;基于作业的神经网络模型的前向部分,获取处 理作业的模型参数,计算所有模型参数的总量,并负载均衡地将所有模型参数划分成多个 部分,配置对应数量的模型参数节点,并为一个模型参数节点配置一个计算设备的位置标 签;在每个模型参数节点及其后继前向运算任务节点之间插入广播节点,并配置相同的位 置标签;基于已经配置的神经网络模型的前向部分,对应配置神经网络模型的后向部分,包 括配置与一个模型参数节点相对应的一个模型参数更新节点使其具有与该模型参数节点 相同的位置标签,配置与一个广播节点对应的梯度汇聚节点并使其具有与该广播节点相同 的位置标签,以及配置与一个前向运算任务节点对应的后向运算任务节点使其具有与该前 向运算任务节点相同的位置标签。 根据本公开的分布式计算任务的部署方法,还包括:遍历所述模型参数节点的每 个后继前向运算任务节点,将仅消费所述模型参数节点输出并仅具有单一输出的单一后继 前向运算任务节点配置的位置标签修改为与所述模型参数节点相同的位置标签,并将修改 了位置标签的前向运算任务节点串联在所述模型参数节点与其对应的广播节点之间;以及 修改与所述单一后继前向运算任务节点对应的后向运算任务节点的位置标签为与所述模 型参数节点相同的位置标签,并将修改了位置标签的后向运算任务节点串联到所述模型参 数更新节点和梯度汇聚节点之间。 采用上述分布式计算任务的部署系统和方法以及分布式数据处理系统和方法,将 用于数据并行处理的模型参数和更新组件参数部署在多个执行数据并行处理的多个计算 设备其中之一上,模型参数组件中的模型参数通过广播组件输入到每一个其他并行计算设 备上去供后继的前向数据处理组件和后向数据处理组件使用,这就减少了在其他并行计算 设备上部署同样模型参数的需要,从而减少了计算设备在模型参数部署方面的内存空间需 求。而且对应地,在部署模型参数的计算设备上对应地部署更新组件参数,通过梯度汇聚组 件进行集合通信获得对应其他计算设备上后继后向数据处理组件产生的梯度从而获得全 局梯度,从而可以通过模型参数更新组件对模型参数进行更新操作。这样同样减少了在其 他并行计算设备上部署同时更新组件参数的需要,从而减少了计算设备在模型参数更新方 面的内存空间需求。因此,相比于现有技术采用的全局梯度聚合(ALLREDUCE)的数据并行方 式,更新组件部分的计算资源和内存的使用都将有效降低。同时,因为全局梯度聚合代价近 似的等价于本公开的梯度聚合与广播,因此,本公开的通信效率和现有技术的全局梯度聚 合方式的通信效率是一致的。如上所述,除了模型参数,本公开还会把仅有模型参数参与的 运算节点(例如模型的类型转换或者归一化处理)与模型参数节点部署同一计算设备上并 位于模型参数节点或组件对应的广播节点之前,因此能够进一步降低了这些仅有模型参数 参与的运算节点在其他计算设备上的并行部署,也进一步节省了其他计算设备上内存和计 8 CN 111597055 A 说 明 书 5/10 页 算资源的使用。 本发明的其它优点、目标和特征将部分通过下面的说明体现,部分还将通过对本 发明的研究和实践而为本领域的技术人员所理解。 附图说明 图1所示的是根据本公开的第一实施例的一种分布式数据处理系统原理结构示意 图。 图2所示的是根据本公开的第二实施例的一种分布式数据处理系统原理结构示意 图。 图3所示的是根据本公开的分布式数据处理方法的流程示意图。 图4所示的是根据本公开的一个实施例的分布式计算任务的部署系统的原理示意 图。











