
技术摘要:
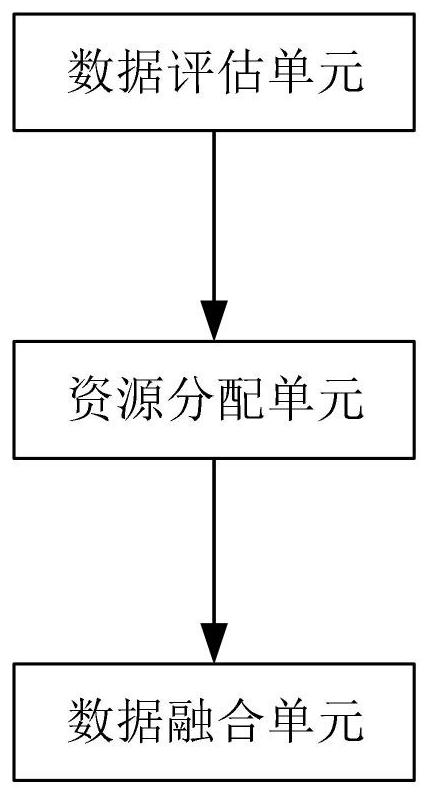
本发明计算机技术领域,具体涉及基于数据融合的计算机数据处理系统及方法。所述系统包括:数据评估单元,用于评估待处理的数据,获取待处理数据的数据信息;所述数据信息至少包括:数据规模大小,数据类型和数据结构;资源分配单元,根据预设的资源分配模型,基于所述 全部
背景技术:
数据(Data)是对事实、概念或指令的一种表达形式,可由人工或自动 化装置进行 处理。数据经过解释并赋予一定的意义之后,便成为信息。数据 处理(dataprocessing)是 对数据的采集、存储、检索、加工、变换和传输。 数据处理的基本目的是从大量的、可能是杂乱无章的、难以理解的数据 中抽取并 推导出对于某些特定的人们来说是有价值、有意义的数据。 数据处理是系统工程和自动控制的基本环节。数据处理贯穿于社会生产 和社会 生活的各个领域。数据处理技术的发展及其应用的广度和深度,极大 地影响了人类社会发 展的进程。 数据融合技术,包括对各种信息源给出的有用信息的采集、传输、综合、 过滤、相 关及合成,以便辅助人们进行态势/环境判定、规划、探测、验证、 诊断。这对战场上及时准 确地获取各种有用的信息,对战场情况和威胁及其 重要程度进行适时的完整评价,实施战 术、战略辅助决策与对作战部队的指 挥控制,是极其重要的。未来战场瞬息万变,且影响决 策的因素更多更复杂, 要求指挥员在最短的时间内,对战场态势作出最准确的判断,对作 战部队实 施最有效的指挥控制。而这一系列“最”的实现,必须有最先进的数据处理 技术 做基本保证。否则再高明的军事领导人和指挥官也会被浩如烟海的数据 所淹没,或导致判 断失误,或延误决策丧失战机而造成灾难性后果。 系统资源是用来跟踪应用程序的运行而不是用来运行应用程序的,就像 公路上 车多车少,并不是车稍微多点就没有办法开车了。因此可以肯定地说, 影响计算机系统性 能的是计算机系统其他的因素,而绝不会是可用系统资源 的大小。当用户计算机系统性能 明显降低时,应该从别的方面去查找原因, 而不要马上怀疑到系统资源身上。 从硬件方面来看,内存太小导致系统不得不频繁使用虚拟内存是影响系 统性能 的主要原因之一; 从软件方面来看,因为Windows是一个多任务的操作系统,大家都习 惯同时运行 多个应用程序而不管当时是否实际需要。而编写和调试这些应用 程序的程序员一般只考 虑其在单任务环境下的运行,而没有过多的精力从多 任务环境来考虑和调试,因此许多应 用程序间往往不能很好地协同工作,同 时运行多个这样的应用程序会因它们彼此之间发 生冲突而导致系统性能下 降。当然,Windows9X多任务管理机制的不完善也是造成这个问 题的主要 原因之一。 专利号为CN201410047608.XA的专利,公开了一种多平台点云数据融 合方法,涉 及测绘、工程测量领域,包括如下步骤:数据采集:通过移动平 台搭载的数据采集设备、固 定式地面激光扫描设备获取目标区域内地物、地 貌的原始数据;数据预处理:将采集到的 5 CN 111597399 A 说 明 书 2/11 页 原始数据分别进行工程化组织管理 及滤波去噪等预处理工作;数据融合:对滤波去噪后的 点云数据进行精度分 析,以精度最高的点云数据为依据,对其余数据进行精度纠正,此外, 还可 基于移动平台获取的点云数据实现固定式地面激光扫描设备获取的数据坐 标转换, 实现无外业控制点坐标转换。其虽然能够实现多种领域,多种结构 的数据融合,且对数据 进行降噪处理,但数据处理的过程复杂度较高,且占 用的系统资源较多,在进行某些低量 级的数据融合时,造成了较多的资源浪 费。 专利号为CN201610191767.6A的专利,公开了一种多数据来源的数据 融合、智能 搜索的处理方法,一种多数据来源的数据融合、智能搜索的处理 方法及应用,传感器布局 采用平面布局,传感器处于同一个平面上组成传感 网,数据融合包含多个同种传感器的数 据融合和不同种传感器的数据融合, 传感器的数据特征及数据类型采用轮询的方式进行 数据采集,采集节点在进 行采集时要对数据进行冗余处理,采取基于分批估计的自适应算 法。本方法 通过动态采集各传感器数据,延长系统对传感器数据的识别时间,提高了数 据 精度,增大数据的准确率。其数据融合针对传感器系统,且进行数据融合 时,没有针对数据 的分析过程,进行数据融合的效率较低,占用资源率也较 高。
技术实现要素:
有鉴于此,本发明的主要目的在于提供基于数据融合的计算机数据处理 系统及 方法,其基于数据评估的基础上,进行系统资源分配和数据融合,具 有处理效率高和资源 利用率高的优点。 为达到上述目的,本发明的技术方案是这样实现的: 基于数据融合的计算机数据处理系统,所述系统包括:数据评估单元, 用于评估 待处理的数据,获取待处理数据的数据信息;所述数据信息至少包 括:数据规模大小,数据 类型和数据结构;资源分配单元,根据预设的资源 分配模型,基于所述数据评估单元获取 的数据信息,分配计算机的计算资源 用于数据处理;数据融合单元,调用资源分配单元分 配的计算资源,基于所 述数据评估单元获取的数据信息,对待处理的数据进行数据融合, 将融合后 的数据进行存储。 进一步的,所述数据评估单元包括:若干个数据识别子单元;所述数据 识别子单 元分别基于多个维度和多个特征空间进行训练;训练后的数据识别 子单元在对应的维度 和特征空间下,能够对待处理数据进行分析,得出分析 结果;所述数据评估单元还包括:分 析整合单元,综合所有数据识别子单元 的分析结果,得出待处理数据的数据规模大小,数 据类型和数据结构。 进一步的,所述维度定义为:数据的特征,即数据规模大小、数据类型 和数据结 构;所述训练过程具体包括:所述数据识别子单元分别在数据规模 大小维度、数据类型维 度或数据结构维度下,基于预先采集到的训练数据样 本,提取数据特征,使用如下公式,统 计数据特征符合每一个特征空间的次 数: 其中,N为符合 特征空 间的次数,S为数据个数,λi为第i个训练样本的权重,M为每一个 特征空间中的特征个数, 6 CN 111597399 A 说 明 书 3/11 页 coun tj第i个训练样本的数据特征个数;根据统计 到的训练样本符合每一个特征空间中 的次数,按照从多到少,设置对应训练 样本的特征空间从高到低的优先级,完成数据特征 空间训练;在评估待处理 数据时,数据识别子单元对待处理数据分别进行对应维度下的特 征空间映射, 统计特征空间映射结果,将频次最高的映射而结果,作为识别结果。 进一步的,所述资源分配单元,根据预设的资源分配模型,基于所述数 据评估单 元获取的数据信息,分配计算机的计算资源用于数据处理的方法执 行以下步骤:建立资源 分配模型,所述资源分配模型通过如下公示表示: 其中:F(x)为分配资源百分比,下为数据信息:数据规模大小,数据类型和 数据结 构的加权平均值,α为常数,α>3, 为标准平均值,为设定的常数; 根据建立的资源分配模 型,首先通过如下公式,计算数据信息的加权平均值: 数据规模大小*A 数据类型对应的权 值*B 数据结构对应的权值*C;其中数 据类型对应的权值含义为:针对不同的数据类型,预 设不同的数值作为其权 值;数据结构对应的权值定义为:针对不同的数据结构,预设不同 的数值作 为其权值;然后使用资源分配模型计算应该分配的计算机资源百分比,将该 计 算结果发送至数据融合单元。 进一步的,所述数据融合单元,调用资源分配单元分配的计算资源,基 于所述数 据评估单元获取的数据信息,对待处理的数据进行数据融合,将融 合后的数据进行存储的 方法执行以下步骤:根据计算得到的计算机资源百分 比,调用计算机资源,提取待处理的 数据的数据空间,根据待处理数据的数 据空间,并将待处理数据进行归类划分为不同的目 标异构数据库;对目标异 构数据库进行归一化处理得到分类目标异构数据矩阵;使用如下 公式,将分 类目标异构数据矩阵分别与每一个定向数据空间群进行映射匹配: 其中,sim(d j,d k)为映射匹配结果, 为产品目标异构数据矩阵,wji为矩阵行值,|dj|为对应的矩阵行 列式的值; 为定向数据空间群,wki为矩阵行值,|dk||为对应的矩 阵行列式的值;根据 最终映射匹配的结果,将匹配映射结果sim(dj,dk)最小 的值对应的定向数据空间群作为对 应产品信息的数据空间,完成数据空间构 建;根据构建的数据空间,进行混沌模糊匹配,完 成不同异构数据之间的整 合。 7 CN 111597399 A 说 明 书 4/11 页 基于数据融合的计算机数据处理方法,所述方法执行以下步骤:数据评 估单元, 评估待处理的数据,获取待处理数据的数据信息;所述数据信息至 少包括:数据规模大小, 数据类型和数据结构;资源分配单元,根据预设的 资源分配模型,基于所述数据评估单元 获取的数据信息,分配计算机的计算 资源用于数据处理;数据融合单元,调用资源分配单 元分配的计算资源,基 于所述数据评估单元获取的数据信息,对待处理的数据进行数据融 合,将融 合后的数据进行存储。 进一步的,所述数据评估单元包括:若干个数据识别子单元;所述数据 识别子单 元分别基于多个维度和多个特征空间进行训练;训练后的数据识别 子单元在对应的维度 和特征空间下,能够对待处理数据进行分析,得出分析 结果;所述数据评估单元还包括:分 析整合单元,综合所有数据识别子单元 的分析结果,得出待处理数据的数据规模大小,数 据类型和数据结构。 进一步的,所述维度定义为:数据的特征,即数据规模大小、数据类型 和数据结 构;所述训练过程具体包括:所述数据识别子单元分别在数据规模 大小维度、数据类型维 度或数据结构维度下,基于预先采集到的训练数据样 本,提取数据特征,使用如下公式,统 计数据特征符合每一个特征空间的次 数: 其中,N为符合 特征空 间的次数,S为数据个数,λi为第i个训练样本的权重,M为每一个 特征空间中的特征个数, coun tj第i个训练样本的数据特征个数;根据统计 到的训练样本符合每一个特征空间中 的次数,按照从多到少,设置对应训练 样本的特征空间从高到低的优先级,完成数据特征 空间训练;在评估待处理 数据时,数据识别子单元对待处理数据分别进行对应维度下的特 征空间映射, 统计特征空间映射结果,将频次最高的映射而结果,作为识别结果。 进一步的,所述资源分配单元,根据预设的资源分配模型,基于所述数 据评估单 元获取的数据信息,分配计算机的计算资源用于数据处理的方法执 行以下步骤:建立资源 分配模型,所述资源分配模型通过如下公示表示: 其中:F(x)为分配资源百分比,下为数据信息:数据规模大小,数据类型和 数据结 构的加权平均值,α为常数,α>3, 为标准平均值,为设定的常数; 根据建立的资源分配模 型,首先通过如下公式,计算数据信息的加权平均值: 数据规模大小*A 数据类型对应的权 值*B 数据结构对应的权值*C;其中数 据类型对应的权值含义为:针对不同的数据类型,预 设不同的数值作为其权 值;数据结构对应的权值定义为:针对不同的数据结构,预设不同 8 CN 111597399 A 说 明 书 5/11 页 的数值作 为其权值;然后使用资源分配模型计算应该分配的计算机资源百分比,将该 计 算结果发送至数据融合单元。 进一步的,所述数据融合单元,调用资源分配单元分配的计算资源,基 于所述数 据评估单元获取的数据信息,对待处理的数据进行数据融合,将融 合后的数据进行存储的 方法执行以下步骤:根据计算得到的计算机资源百分 比,调用计算机资源,提取待处理的 数据的数据空间,根据待处理数据的数 据空间,并将待处理数据进行归类划分为不同的目 标异构数据库;对目标异 构数据库进行归一化处理得到分类目标异构数据矩阵;使用如下 公式,将分 类目标异构数据矩阵分别与每一个定向数据空间群进行映射匹配: 其中,sim(d j,d k)为映射匹配结果, 为产品目标异构数据矩阵,wji为矩阵行值,|dj|为对应的矩阵行 列式的值; 为定向数据空间群,wki为矩阵行值,|dk||为对应的矩 阵行列式的值;根据最 终映射匹配的结果,将匹配映射结果sim(dj,dk)最小 的值对应的定向数据空间群作为对应 产品信息的数据空间,完成数据空间构 建;根据构建的数据空间,进行混沌模糊匹配,完成 不同异构数据之间的整 合。 本发明的基于数据融合的计算机数据处理系统及方法,具有如下有益效 果:本发 明在基于数据评估的基础上,进行系统资源分配和数据融合,具有 处理效率高和资源利用 率高的优点。实现上述有益效果的过程主要体现在两 个方面:1.对待处理数据进行数据规 模大小,数据类型和数据结构的评估, 这样可以从整体上获悉待处理数据的基本情况。以 便于后续的数据融合以及 资源分配。由于在实际情况中,数据类型、数据结构和数据规模 大小往往不 是规定的,获取这些信息后,可以针对当前待处理数据的情况,更加合理的 分 配系统资源,在处理数据类型较为复杂,如浮点型数据,数据结构较为多 变和复杂,数据规 模较大的数据时,分配较多的系统资源,可以更加快速的 得到结果,在处理数据结构简单, 数据规模较小的数据时,可以分配较小的 资源,避免资源的浪费。2.在进行数据融合过程 中,通过建立异构数据矩阵 分别与每一个定向数据空间群进行映射匹配完成,这样的好处 在于,可以针 对同一待处理数据源,但数据结构不同的数据进行一次性融合,且融合准确 率更高,融合效率更高。在占用相同系统资源的情况下,本发明的计算机数 据处理系统,处 理数据更加方便和准确。 附图说明 图1为本发明实施例提供的基于数据融合的计算机数据处理系统的系统 结构示 意图; 图2为本发明实施例提供的基于数据融合的计算机数据处理方法的方法 流程示 意图; 图3为本发明实施例提供的基于数据融合的计算机数据处理系统及方法 的数据 9 CN 111597399 A 说 明 书 6/11 页 融合单元的进行数据融合的流程示意图; 图4为本发明实施例提供的基于数据融合的计算机数据处理系统及方法 的数据 融合效率的实验曲线示意图与现有技术的对比实验效果示意图; 图5为本发明实施例提供的基于数据融合的计算机数据处理系统及方法 的资源 利用率的实验曲线示意图与现有技术的对比实验效果示意图。 1-本发明的实验曲线,2-现有技术的实验曲线。











