
技术摘要:
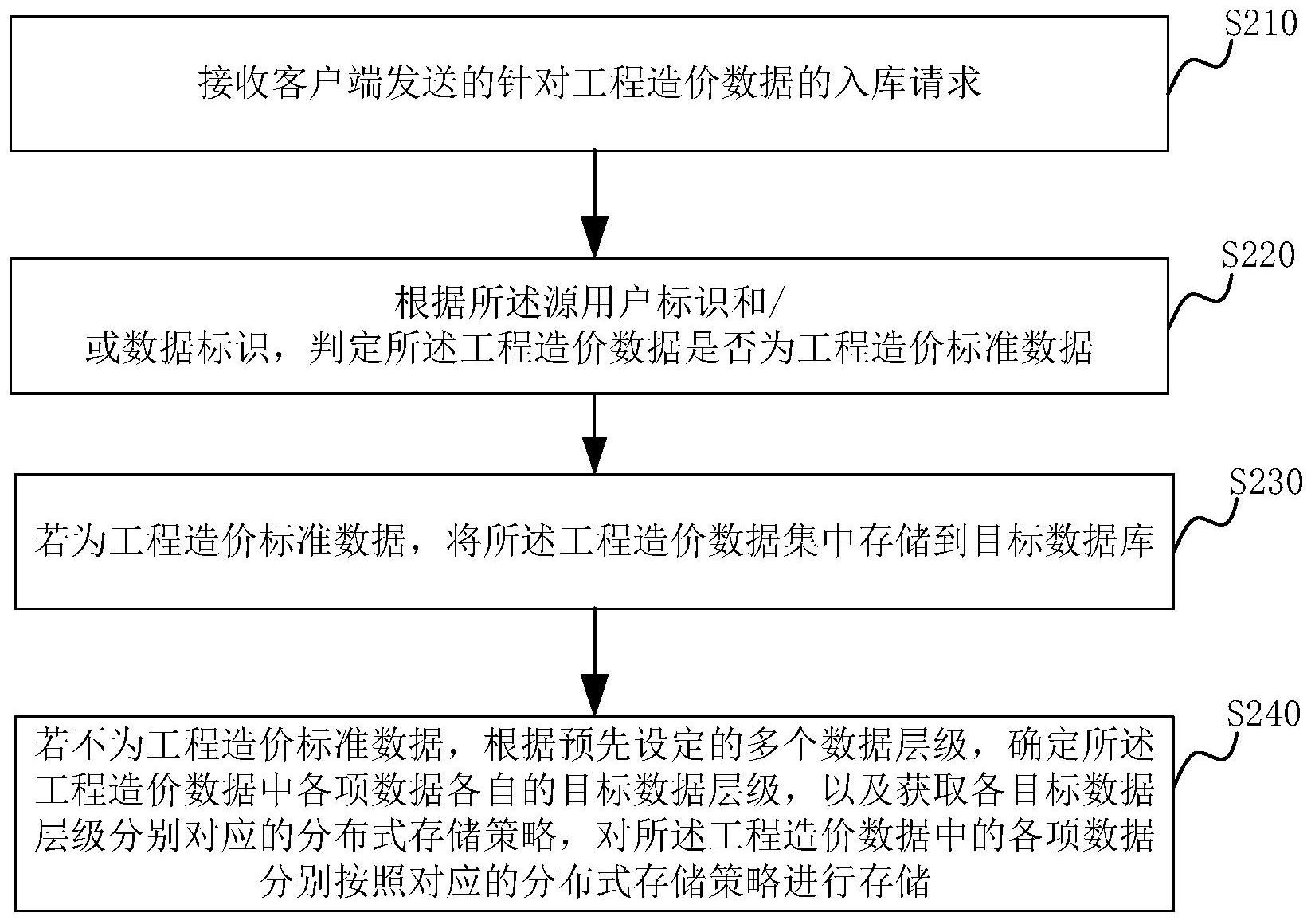
本申请涉及一种工程造价数据的存储方法、装置、计算机设备和存储介质。所述方法包括:接收客户端发送的针对工程造价数据的入库请求;判定所述工程造价数据是否为工程造价标准数据;若为工程造价标准数据,将所述工程造价数据集中存储到目标数据库;若不为工程造价标准 全部
背景技术:
由于工程造价行业的特殊性,工程造价数据的数据量通常比较大,且数据明细繁 多,不同工程造价项目,涵盖的工程造价数据内容也不尽相同。而现有对工程造价数据的存 储方式是,基于工程造价编制软件填写工程造价数据,由此得到编制文件,然后基于编制文 件实现工程造价数据的归集,需要大量的人工对数据进行手工归集,然后整体导入归集后 的数据到预先建立的数据库中存储。 然而,由于工程造价数据包含大量的细节数据,因此采用对归集后的数据整体导 入到数据库存储的方式,对于数据库存储资源的要求较高。
技术实现要素:
基于此,有必要针对上述技术问题,提供一种能够降低数据库存储资源要求的工 程造价数据的存储方法、装置、数据服务器和存储介质。 一方面提供一种工程造价数据的存储方法,应用于数据服务器,所述方法包括: 接收客户端发送的针对工程造价数据的入库请求;所述入库请求中携带有所述工 程造价数据的源用户标识和/或数据标识,所述源用户为提供所述工程造价数据的用户; 根据所述源用户标识和/或数据标识,判定所述工程造价数据是否为工程造价标 准数据; 若为工程造价标准数据,将所述工程造价数据集中存储到目标数据库;所述目标 数据库设置于所述数据服务器或者所述数据服务器信任的服务器中; 若不为工程造价标准数据,根据预先设定的多个数据层级,确定所述工程造价数 据中各项数据各自的目标数据层级,以及获取各目标数据层级分别对应的分布式存储策 略,对所述工程造价数据中的各项数据分别按照对应的分布式存储策略进行存储。 在其中一个实施例中,所述根据所述源用户标识,识别所述工程造价数据是否为 工程造价标准数据,包括: 获取所述工程造价数据所属的造价结构属性; 获取所述造价结构属性对应的标准用户标识和/或标准数据标识; 将所述源用户标识、数据标识分别与所述标准用户标识、标准数据标识进行匹配, 若其中至少一项匹配,则判定所述工程造价数据为工程造价标准数据;否则,判定所述工程 造价数据不为工程造价标准数据。 在其中一个实施例中,所述获取所述工程造价数据所属的造价结构属性,包括: 调用预设的结构识别模型,将所述工程造价数据输入所述结构识别模型,根据所 述结构识别模型的输出结果,得到所述工程造价数据对应的造价结构属性; 5 CN 111597272 A 说 明 书 2/12 页 所述结构识别模型预先设置于所述数据服务器,用于识别输入数据与预设的多个 造价结构属性的匹配度、并输出所述输入数据对应的造价结构属性。 在其中一个实施例中,所述多个数据层级至少包括工程概况层级、单体项目层级 以及项目分部层级; 所述获取各个目标数据层级分别对应的分布式存储策略,对所述工程造价数据中 对应不同目标数据层级的数据,分别按照各自对应的分布式存储策略进行存储,包括: 若所述目标数据层级中包含工程概况层级,则获取第一分布式存储策略;所述第 一分布式存储策略下,根据所述工程造价数据所属的造价结构属性与分布式数据库地址的 映射关系,确定目的存储地址; 若所述目标数据层级中包含单体项目层级,则获取第二分布式存储策略;所述第 二分布式存储策略下,根据所述单体项目层级对应的工程概况层级的数据的存储地址确定 第一候选分布式数据库,并根据源用户标识与分布式数据库地址的映射关系,从所述第一 候选分布式数据库中确定目的数据库,将所述目的数据库地址作为目的存储地址; 若所述目标数据层级中包含项目分部层级,则获取第三分布式存储策略;所述第 三分布式存储策略下,根据所述项目分部层级对应的单体项目层级的工程造价数据的存储 地址确定第二候选分布式数据库,根据各个第二候选分布式数据库的剩余存储空间大小确 定目的数据库,将所述目的数据库地址作为目的存储地址; 对所述工程造价数据中的各项数据,分别按照其目标数据层级对应的第一分布式 存储策略、第二分布式存储策略或第三分布式存储策略确定目的存储地址以进行分布式存 储。 在其中一个实施例中,所述将所述工程造价数据集中存储到目标数据库的步骤, 包括:将所述工程造价数据以二进制文件格式集中存储到目标数据库; 所述对所述工程造价数据中的各项数据分别按照对应的分布式存储策略进行存 储的步骤,包括:对所述工程造价数据中各项数据,分别按照各自对应的分布式存储策略以 二进制文件格式进行存储。 在其中一个实施例中,所述对所述工程造价数据中的各项数据分别按照对应的分 布式存储策略进行存储的步骤之后,还包括: 获取所述工程造价数据中与各目标数据层级对应的各项数据的存储地址; 基于所述多个数据层级之间的预设级联关系,获取所述目标数据层级之间的级联 关系; 将所述目标数据层级之间的级联关系以及各目标数据层级对应的各项数据的存 储地址进行关联,将关联结果信息存储至所述目标数据库。 在其中一个实施例中,所述方法还包括: 接收客户端的造价指标统计请求,所述造价指标统计请求中携带有待统计指标项 信息; 访问标准函数库以调用其中与所述待统计指标项信息对应的统计函数,获取所述 统计函数关联的工程造价数据,作为待查询数据; 确定出所述待查询数据对应造价结构属性和最高数据层级; 根据所述造价结构属性和最高数据层级访问所述关联结果信息,确定所述最高数 6 CN 111597272 A 说 明 书 3/12 页 据层级级联的下级数据层级,以及获取所述造价结构属性对应的根据分别与所述最高数据 层级、所述下级数据层级对应待查询数据的存储地址; 根据分别与所述最高数据层级、所述下级数据层级对应待查询数据的存储地址, 获取各待查询数据对应的目标数据; 根据各待查询数据对应的目标数据以及所述统计函数,得到所述待统计指标项的 统计结果; 向所述客户端发送所述统计结果。 又一方面提供一种工程造价数据的存储装置,应用于数据服务器,所述装置包括: 请求接收模块,用于接收客户端发送的针对工程造价数据的入库请求;所述入库 请求中携带有所述工程造价数据的源用户标识和/或数据标识,所述源用户为提供所述工 程造价数据的用户; 标准数据识别模块,用于根据所述源用户标识和/或数据标识,判定所述工程造价 数据是否为工程造价标准数据; 标准数据存储模块,用于若为工程造价标准数据,将所述工程造价数据集中存储 到目标数据库;所述目标数据库设置于所述数据服务器或者所述数据服务器信任的服务器 中; 非标准数据存储模块,用于若不为工程造价标准数据,根据预先设定的多个数据 层级,确定所述工程造价数据中各项数据各自的目标数据层级,以及获取各目标数据层级 分别对应的分布式存储策略,对所述工程造价数据中的各项数据分别按照对应的分布式存 储策略进行存储。 又一方面提供一种数据服务器,包括存储器和处理器,所述存储器存储有计算机 程序,其特征在于,所述处理器执行所述计算机程序时实现上述工程造价数据的存储方法 的步骤。 又一方面提供一种计算机可读存储介质,其上存储有计算机程序,所述计算机程 序被处理器执行时实现上述工程造价数据的存储方法的步骤。 上述工程造价数据的存储方法、装置、计算机设备和存储介质,数据服务器在接收 到客户端发送的针对工程造价数据的入库请求之后,首先判定所述工程造价数据是否为工 程造价标准数据;若为工程造价标准数据,则对所述工程造价数据进行集中存储,且存储地 址为目标数据库;若不为工程造价标准数据,则确定所述工程造价数据中各项数据各自的 目标数据层级,以及获取各目标数据层级分别对应的分布式存储策略,对所述工程造价数 据中的各项数据分别按照对应的分布式存储策略进行存储。本申请对于工程造价标准数据 集中存储,保证标准数据的可靠性,对于非工程造价标准数据,基于各自的数据层级进行分 布式存储,有利于减轻对于数据库存储资源的要求。 在其他实施例中,在对非工程造价标准数据进行分布式存储的同时,还对所述工 程造价数据所属的造价结构属性、不同数据层级的级联关系以及数据存储地址进行集中存 储,便于后续对不同造价结构属性对应的工程造价数据的跟踪管理,以及提高后续对与分 布式存储的工程造价数据的查询和应用效率。 7 CN 111597272 A 说 明 书 4/12 页 附图说明 图1为一个实施例中工程造价数据的存储方法的应用环境图; 图2为一个实施例中工程造价数据的存储方法的流程示意图; 图3A为一个实施例中项目造价概况数据的示意图; 图3B为一个实施例中单体项目造价数据的示意图; 图3C为一个实施例中单体项目造价数据下的分部造价数据的示意图; 图3D为一个实施例中工程造价标准数据的示意图; 图4为另一个实施例中工程造价数据的存储方法的流程示意图; 图5为一个实施例中工程造价数据的存储装置的结构框图; 图6为一个实施例中数据服务器的内部结构图。











