
技术摘要:
本发明提供的一种基于极限学习机的密度聚类离群点检测方法,充分结合了机器学习方法的优势与聚类算法的优势,利用极限学习机来给出聚类算法中关键的阈值,可以拓宽密度聚类算法的应用范围和提高密度聚类算法的准确度。包括以下步骤:1选取一段日志类型为3的历史数据, 全部
背景技术:
近年来,随着全球能源问题的日益严重,世界各国都开始大力推进智能电网的发 展,智能电网建设的目标是形成一个覆盖整个电力系统成产过程的安全、绿色、节能的实时 系统。而支持智能电网安全、节能、实时运行的基础是电网信息的实时采集、存储、传输以及 海量多源数据的快速分析。为了实现这一目的,各种智能设备分别应用于电网信息的采集、 监测、通讯等各个方面。智能电表为代表的计量自动化系统就是智能设备应用于电网的核 心部分之一,通过电网中计量自动化终端,实现对发电厂、变电站、变压器和用户这些角色 的“发电、供电、配电、售电”整个过程的数据采集与监控功能,在提高供电质量、改善管理、 减轻运维人员负担、提高经济效益与系统稳定性方面发挥着重要的作用。但是智能计量设 备在给电网运维带来便利的同时,不可避免会出现终端通讯故障、传输的报文数据异常等 问题,只有能够快速、准确的发现并处理这些问题才能保证智能电网的稳定运行。智能采集 终端掉线是最为普遍的一种故障状态,能够准确、有效的判断采集终端得掉线与否对保证 采集数据的稳定和可靠有着重要的作用。 目前,报文掉线的实时分析的方法主要是借鉴离群点检测的方法和机器学习的方 法。离群点检测的方法有:统计学方法,基于距离的方法,基于密度的方法等,但是离群点检 测方法都需要人为设定一个阈值,阈值的设定对检测的准确度有较大的影响,并且算法的 适应性和广泛性较差;机器学习的方法有:BP神经网络,宽度学习,极限学习机等,但是机器 学习的方法在面对海量数据时,有神经网络过于复杂、训练时间太长和容易陷入局部最优 值等缺点。因此,开发一种适应性强,运算速度快且准确率高的海量报文掉线分析系统,对 于提高电网工作效率、经济效益具有重要的意义。
技术实现要素:
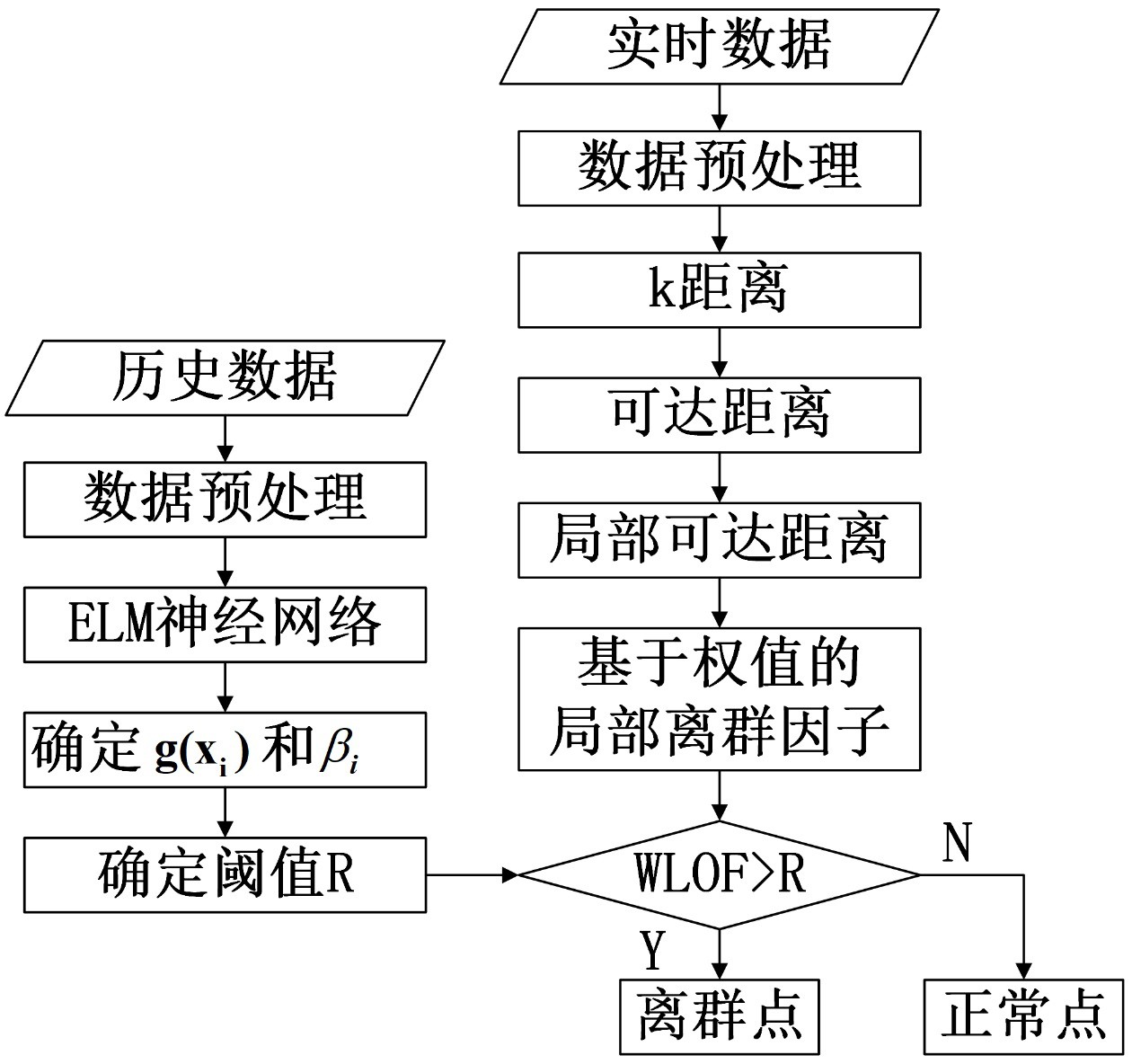
为解决上述问题,本发明结合了机器学习方法的优势与聚类算法的优势,利用极 限学习机来给出聚类算法中关键的阈值,可以拓宽聚类算法的应用范围和提高密度聚类算 法的准确度。 具体来说,本发明提供了一种基于极限学习机的密度聚类离群点检测方法,该方 法包括: 步骤1,选取一段日志类型为3的历史数据,包含正常数据和掉线数据; 步骤2,对报文数据进行预处理; 步骤3,将预处理之后的且带有标签的数据导入极限学习机中; 步骤4,通过极限学习机得出基于权值的局部离群因子的阈值; 步骤5,设定密度聚类的阈值; 3 CN 111598165 A 说 明 书 2/6 页 步骤6,导入实时数据; 步骤7,计算实时数据的基于权值的局部离群因子; 步骤8,判断出掉线数据。 其中,步骤2中的报文数据预处理是把报文数据中的时间差与时间标签截取出来, 然后把时间差与时间标签进行归一化处理。 将所有日志类型为3的时间数据转换为以秒为单位的数值数据,如12:19:23 转换 为44363,把时间的数值数据记为时间标签。 数据归一化的范围为[0,1],是为了极限学习机确定的阈值更加准确,以及在聚类 算法应用中有更好的效果。 将数据按终端进行分类,将相同终端的报文分成一组,进行差分计算得到时间差 数据,令x轴为时间标签,y轴为时间差,计算WLOF值。 其中,步骤4选取的极限学习机有输入层,隐含层和输出层三部分,训练前根据训 练集确定好隐含层节点数,在整个训练过程中只需要为输入权值和隐含层偏置随机赋值, 训练过程不需要迭代,且得到最优解,大大减少了训练时间。 若给定极限学习机N个训练样本 其中xi=[xi1,xi2,xi3,…, xin]T ∈Rn作为训练集的输入数据;yi=[ti1,ti2,ti3,…,tim]T∈Rm作为训练集的输出数据。具 有L个隐含层神经元且激活函数为g(xi)的标准单隐含层神经网络的表达式如下所示: 其中wi=[wi1,wi2,wi3,…,win]T为输入层节点与第i个隐含层节点之间的连接 权值向量;βi=[βi1,βi2,βi3,…,βin]T则是输出层节点与第i个隐含层节点的偏置;yi= [yi1,yi2,yi3,…,yim]T值是ELM网络是实际输出值。 具有L个隐含层节点的单隐含层前馈神经网络能够零误差的逼近任意N个样本, 即: 此时有 可将 简写成: Hβ=T 其中H是ELM的隐含层输出矩阵: 输出层权值为: 4 CN 111598165 A 说 明 书 3/6 页 根据上述要求得出密度聚类的阈值需要对极限学习机进行改进: 首先,把预处理好的数据作为训练集;然后,通过极限机来得出正常数据与掉线数 据的输出值;最后,根据正常数据与掉线数据的输出值来确定聚类算法的阈值。 其中,步骤7选取聚类算法是密度聚类的原因是,密度聚类中涉及局部离群因子 LOF,可以更好的检测出掉线数据; k距离:对于数据集X={x1,x2,…,xn}中的任意点xi,xi与其最近的第k 个点xj之 间的距离被称为点xi的k距离,采用马氏距离来定义数据点之间的距离(相似度),记作 k-distance(xi)=(x -x )TΣ-1i j (xi-xj) 式中协方差矩阵 k距离领域:对于数据集中的任意点xi,把所有距离xi不大于 k-distance(xi)的 数据对象所形成的领域称之为k距离领域; 可达距离:设xi、xj为数据集中的任意两个数据点,那么数据点xi到数据点xj之间 的可达距离为点xi的k距离k-distance(xi)与xi、xj之间距离较大的一个,记为 reachdis(xi-xj)=max{d(xi-xj),k-distance(xi)} 局部可达密度:数据点xi的局部可达密度是指xi点到其领域内的最大的前 k个距 离平均值的倒数,这是对xi点局部密度的度量,记为 其中lrdk(xi)值较大表明xi点在k个点的分布比较稠密,因此为正常点;反之当 lrdk(xi)值较小时,表明数据点xi在k个点的分布比较稀疏,则该数据点可能为离群点。 局部离群因子LOF:局部离群因子表征了数据点的离群程度,也是衡量一个数据点 离群的可能性大小的指标,记为 为了让LOF值满足报文的时间差越大其LOF值越大的趋势条件,在计算局部离群因 子时,加入权值fi,本文的权值可以设定为归一化之后的时间差。基于权值的局部离群因子 记为WLOFk(xi),其表达式为: WLOFk(xi)=fi·LOFk(xi) 本发明通过结合机器学习和聚类算法的优点,提出了一种基于极限学习机和密度 聚类的海量报文掉线状态分析系统,通过极限学习机来确定密度聚类的阈值,来提高聚类 的准确度和聚类应用的广泛性。在面对海量报文数据时,聚类相对于神经网络有较块的响 应速度,更适合应用于像报文这类需要较快知道是否掉线的问题。 5 CN 111598165 A 说 明 书 4/6 页 附图说明 图1是本发明的一种基于极限学习机的密度聚类离群点检测方法的流程图。 图2是局部离群因子与基于权值的局部离群因子对比图。 图3是一次基于极限学习机的密度聚类离群点检测结果图。 具体实施方法 为使本发明的目的、技术方案和优点更清楚的表达出来,下面结合附图及具体实 例对本发明进一步的详细说明。 本发明提供了一种基于极限学习机的密度聚类离群点检测方法,如图1所示,该方 法具体步骤如下: 步骤1,选取一段日志类型为3的历史数据,包含正常数据和掉线数据; 步骤2,对报文数据进行预处理; 步骤3,将预处理之后的且带有标签的数据导入极限学习机中; 步骤4,通过极限学习机得出基于权值的局部离群因子的阈值; 步骤5,设定密度聚类的阈值; 步骤6,导入实时数据; 步骤7,计算实时数据的基于权值的局部离群因子; 步骤8,判断出掉线数据。 在具体的应用中,主要通过某电力公司提供的报文数据来验证系统的有效性。智 能电表的报文信息模型为:sjsj=2018-05-11 12:19:23;zdljdz=99887766; logtype= 03;ip=127 .0 .0 .1:50910:T。其中,sjsj为上传报文的时间;zdljdz 为终端逻辑地址; logtype为日志类型;ip为ip端口。sjsj为报文掉线检测主要部分。具体的步骤如下: 步骤1,要在该公司的数据库中筛选出logtype=03的数据,这类数据表示为最近 通讯时间的数据,只有logtype=03的数据才有判定智能电表是否掉线的必要和意义; 步骤2中的报文数据预处理是把选取好的2n个报文数据中的时间差与时间标签截 取出来,将所有日志类型为3的时间数据转换为以秒为单位的数值数据,如12:19:23转换为 44363,把时间的数值数据记为时间标签。 然后,把时间差与时间标签进行归一化处理,使其值域在[0,1]。时间差预处理方 法为:首先选取报文数据最小的时间单位秒,然后筛选出最大的时间差Δtmax和最小的时间 差Δtmin,归一化公式为: 时间标签的预处理方法为:首先把数据按时间顺序排列,然后把第一数据的时间 标签设为t1=1,然后下一个数据为t2=1 Δt,其中Δt为第一个数据与第二个数据的时间 差(s),归一化公式为: 其中,步骤4把归一化之后的报文数据记为矩阵(xi,yi),极限学习机对应的连续 的目标函数为f(xi),给定所构造的网络L个单隐含层节点和隐含层节点的激励函数g(xi), 由于存在βi、wi和bi,可以使得SLFNs以0误差逼近 n个样本,ELM的模型的数学表达为: 6 CN 111598165 A 说 明 书 5/6 页 其中wi=[wi1,wi2,wi3,…,win]T为输入层节点与第i个隐含层节点之间的连接 权值向量;βi=[βi1,βi2,βi3,…,βin]T则是输出层节点与第i个隐含层节点的偏置;yi= [yi1,yi2,yi3,…,yim]T值是ELM网络是实际输出值。 具有L个隐含层节点的单隐含层前馈神经网络能够零误差的逼近任意N个样本, 即: 此时有 可将 简写成: Hβ=T 其中H是ELM的隐含层输出矩阵: 输出层权值为: 其中,步骤5密度聚类的阈值设定方法为:分别对输出层H1,H2进行统计分析,选取 一个能最大程度区分正常数据与掉线数据的值设定为阈值R。 其中,步骤6导入实时数据前,需要对实时数据按照步骤2的方法对数据进行预处 理,预处理之后的数据可以使得密度聚类有更好的效果。 其中,步骤7的基于权值的局部离群因子的算法为: 设实时数据预处理之后为矩阵A=[a1,a2,…,am]T,其中ai=(xi,yi),然后,计算 ai与其最近的k个点之间的马氏距离k-distance(ai)。 k-distance(ai)=(ai-aj)TΣ-1(ai-aj) 式中协方差矩阵 对于矩阵A中的任意点ai,把所有距离ai不大于k-distance(ai)的数据对象所形 成的领域称之为kA距离领域; 计算可达距离:设ai、aj为数据集中的任意两个数据点,那么数据点ai 到数据点 aj之间的可达距离为点ai的k距离k-distance(ai)与ai、aj之间距离较大的一个,记为 reachdis(ai-aj)=max{d(ai-aj),k-distance(ai)} 计算局部可达密度:数据点ai的局部可达密度是指ai点到其领域内的最大的前k 个距离平均值的倒数,这是对ai点局部密度的度量,记为 7 CN 111598165 A 说 明 书 6/6 页 其中lrdk(ai)值较大表明ai点在k个点的分布比较稠密,因此为正常点;反之当 lrdk(ai)值较小时,表明数据点ai在k个点的分布比较稀疏,则该数据点可能为离群点。 计算局部离群因子LOF:局部离群因子表征了数据点的离群程度,也是衡量一个数 据点离群的可能性大小的指标,记为 为了让LOF值满足报文的时间差越大其LOF值越大的趋势条件,在计算局部离群因 子时,加入权值fi,本文的权值可以设定为归一化之后的时间差。基于权值的局部离群因子 记为WLOFk(xi),其表达式为: WLOFk(xi)=fi·LOFk(xi) 对同一组数据进行局部离群因子计算与基于权值的局部离群因子计算,其对比情 况如图2所示,左边的为局部离群因子,右边的为基于权值的局部离群因子。 最后,若WLOFk(ai)>R,则ai为掉线数据,若WLOFk(ai)≤R,则ai为正常数据。 其中,步骤8挑选出掉线数据,如图3所示,“*”为掉线数据,“·”为正常数据。 当然,本发明还可以有其它数据的实例,在不背离本发明精神及其实质的情况下, 熟悉领域的技术人员可根据本发明作出各种相应的改变或变形,但这些相应的改变或变形 都应属于本发明所附的权利要求的保护范围。 8 CN 111598165 A 说 明 书 附 图 1/2 页 图1 图2 9 CN 111598165 A 说 明 书 附 图 2/2 页 图3 10











