
技术摘要:
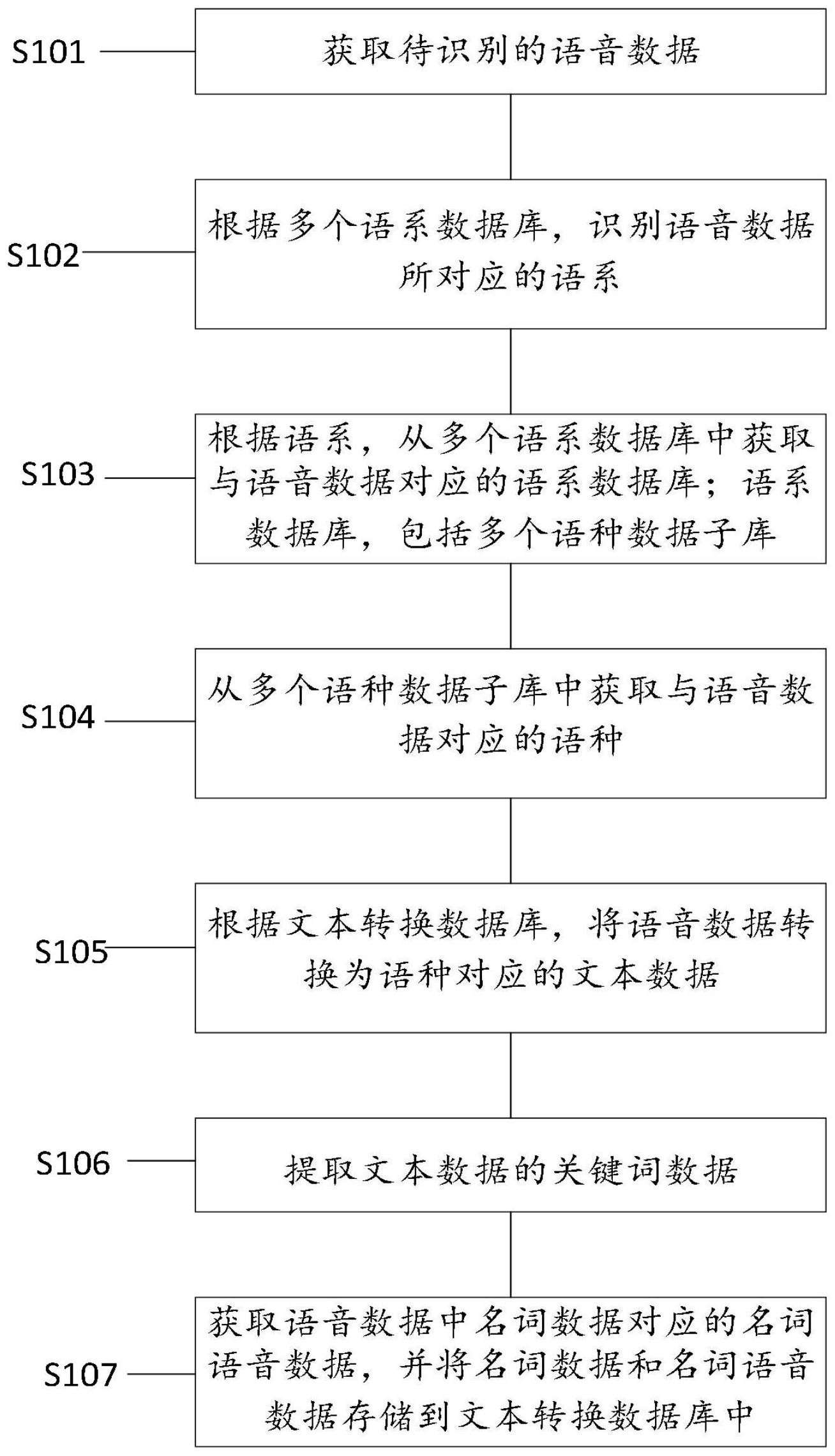
本发明提供了一种语音识别转化方法及系统,所述方法包括如下步骤:获取待识别的语音数据;根据多个语系数据库,识别所述语音数据所对应的语系;根据所述语系,从多个语系数据库中获取与所述语音数据对应的所述语系数据库;所述语系数据库,包括多个语种数据子库;从多 全部
背景技术:
随着科学技术的不断发展,语音识别技术已经融入到了人们生活的方方面面。例 如,人们在不方便手动输入文字时,通过将语音数据输入电子设备,电子设备对语音数据进 行自动转换为文本数据。 但目前,传统的语音识别技术需要人工设置语音转换的语种,并不能够实现将语 音数据转化为与语音数据具有相同语种的文本数据。因此,急需一种语音识别转化方法及 系统。
技术实现要素:
为解决上述技术问题,本发明提供一种语音识别转化方法及系统,用以实现对语 音数据的语种的自动识别,转化为与语音数据具有相同语种的文本数据。 本发明实施例中提供了一种语音识别转化方法,所述方法包括如下步骤: S101、获取待识别的语音数据; S102、根据多个语系数据库,识别所述语音数据所对应的语系; S103、根据所述语系,从多个语系数据库中获取与所述语音数据对应的所述语系 数据库;所述语系数据库,包括多个语种数据子库; S104、从多个所述语种数据子库中获取与所述语音数据对应的语种; S105、根据文本转换数据库,将所述语音数据转换为所述语种对应的文本数据; S106、提取所述文本数据的关键词数据; S107、获取所述语音数据中所述关键词数据对应的关键词语音数据,并将所述关 键词数据和关键词语音数据存储到所述文本转换数据库中。 在一个实施例中,多个所述语系数据库,包括印欧语系数据库,闪含语系数据库, 阿尔泰语系数据库,乌拉尔语系数据库,高加索语系数据库,汉藏语系数据库和德拉维达语 系数据库。 在一个实施例中,所述步骤S101、获取待识别的语音数据之后,所述方法包括:用 于对所述语音数据进行预处理;具体步骤包括: 检测获取所述语音数据中的静音区间; 根据所述静音区间,对所述语音数据进行过滤处理,获取过滤处理后的语音数据。 在一个实施例中,所述步骤S102、根据多个语系数据库,识别所述语音数据所对应 的语系;具体步骤包括: 获取所述语音数据的语系数据;具体包括: 将所述语音数据根据语音时长均等的分为两段子语音数据,并分别提取所述两段 子语音数据的音频特征,形成两个语音频特征矩阵;并通过以下公式(1),获取语系数据: 6 CN 111583905 A 说 明 书 2/9 页 其中F为语系数据,(Y1Y2…Yn)为第一段语音音频特征矩阵,(y1y2…yn)为第二段语 音音频特征矩阵; 并将所述语系数据与多个所述语系数据库内预设的语系阈值数据进行比对,获取 所述语音数据的所对应的语系; 所述语系阈值数据,包括所述印欧语系数据库对应的印欧语系阈值数据、所述闪 含语系数据库对应的闪含语系阈值数据、所述阿尔泰语系数据库对应的阿尔泰语系阈值数 据、所述乌拉尔语系数据库对应的乌拉尔语系阈值数据、所述高加索语系数据库对应的高 加索语系阈值数据、所述汉藏语系数据库对应的汉藏语系阈值数据和所述德拉维达语系数 据库对应的德拉维达语系阈值数据。 在一个实施例中,所述步骤S102之后,所述方法还包括: 判断对所述语音数据的语系识别是否成功; 若识别成功,执行所述步骤S103; 若识别失败,则根据所述语系数据和所述语系阈值数据,计算所述语音数据的与 所述语系阈值数据的语系类间距离数据; 获取所述语系类间距离中的最小值数据,并将所述最小值数据对应的语系作为所 述语音数据的语系; 所述语系类间距离,包括所述语系数据与所述印欧语系阈值数据之间的印欧语系 类间距离数据、所述语系数据与所述闪含语系阈值数据之间的闪含语系类间数据、所述语 系数据与所述阿尔泰语系阈值数据之间的阿尔泰语系类间数据、所述语系数据与所述乌拉 尔语系阈值数据之间的乌拉尔语系类间数据、所述语系数据与所述高加索语系阈值数据之 间的高加索语系类间数据、所述语系数据与所述汉藏语系阈值数据之间的汉藏语系类间数 据和所述语系数据与所述德拉维达语系阈值数据之间的德拉维达语系类间距离。 在一个实施例中,所述S106、提取所述文本数据的关键词数据;具体步骤包括: 对所述文本数据进行分词处理,获取多个词组;具体包括如下步骤: 建立分词模型;其具体步骤如下所示S201-S203: S201将所述文本数据中的第一个字标注为B, S202提取所述文本数据中标注为B的后一个字,并标注为C,同时提取所述文本数 据中中C所对应的字的所有前一个字去重后组成集合D,利用公式(2)判断所述标注为B的字 是否是词语的结束字段; 7 CN 111583905 A 说 明 书 3/9 页 其中,P1,P2为中间函数,length(D)为集合D中间的字的个数,P(B)为出现标注为B 所对应的字的概率,P(C)为出现标注为C所对应的字的概率,length(all)为文本总长度,P (BC)为标注为B所对应字和标注为C所对应的字同时出现的概率,若最终B=B则,标注B不 变,若B=E则将所述标注为B改为标注为E; S203判断所述C是否为最后一个字,若是,则将所述标注C改为标注E,分词结束;若 不是,则将所述标注为C改为标注为B,重复步骤S202和S203; 对所述文本数据分词的步骤为: 将文本数据的开始阶段和所有标注为E的字段后面增加切割线,则任意两个切割 线之间为一个词组,提取所有词组,形成词组向量F1,对所述词组向量F1去除重复值,形成 相应的词组集合F2,则所述集合F2中的词组则为分词处理后获取的词组,F2中含有词组个 数为N个; 提取所述词组中的关键词数据;具体步骤包括: 首先利用公式(3)计算集合F2中每个词组的关键得分; 其中,Qi为F2中第i个词组的得分,e为自然常数,lenght(F2i)为F2中第i个词组的 长度,P(F2i)为F2中第i个词组的长度在向量F1中出现的次数,i=1、2、3……n; 利用公式(4)确定关键词数据; gjc=find(max(Q1,Q2,Q3……QN)) (4) 其中,gjc为最终得到的关键词,find(A)为寻找出A的值所对应的关键词,max( )求 取最大值;则gjc所对应的词则为确定的关键词数据。 一种语音识别转换系统,包括获取模块、语系识别模块、数据库选择模块、语种识 别模块、文本转换模块、关键词提取模块和所述数据库更新模块;其中,所述获取模块,用于 获取待识别的语音数据; 所述语系识别模块,用于根据多个语系数据库,识别与所述语音数据所对应的语 系; 所述数据库选择模块,用于根据所述语系,从多个语系数据库中获取与所述语音 数据对应的所述语系数据库;所述语系数据库,包括多个语种数据子库; 8 CN 111583905 A 说 明 书 4/9 页 所述语种识别模块,用于从多个所述语种数据子库中获取与所述语音数据对应的 语种; 所述文本转换模块,用于根据文本转换数据库,将所述语音数据转换为所述语种 对应的文本数据; 所述关键词提取模块,用于提取所述文本数据的关键词数据; 所述数据库更新模块,用于获取所述语音数据中所述关键词数据对应的关键词语 音数据,并将所述关键词数据和关键词语音数据存储到所述文本转换数据库中。 在一个实施例中,所述文本转换数据库,包括信息类别识别单元、第一存储区和第 二存储区; 所述信息类别识别单元,用于将所述关键词语音数据向所述第一存储区传输,还 用于将所述关键词数据向所述第二存储区传输;所述第一存储区,用于对所述关键词语音 数据通过第一加密算法运算后进行存储;所述第二存储区,用于对所述关键词数据通过第 二加密算法运算后进行存储;所述第一存储区中还存储有所述关键词语音数据对应的所述 关键词数据的存储地址; 所述第一加密算法或者所述第二加密算法,包括等值加密算法、对称加密算法中 的一种或多种。 本发明的其它特征和优点将在随后的说明书中阐述,并且,部分地从说明书中变 得显而易见,或者通过实施本发明而了解。本发明的目的和其他优点可通过在所写的说明 书、权利要求书、以及附图中所特别指出的结构来实现和获得。 下面通过附图和实施例,对本发明的技术方案做进一步的详细描述。 附图说明 图1为本发明所提供一种语音识别转化方法的结构示意图; 图2为本发明所提供一种语音识别转化系统的结构示意图。











