
技术摘要:
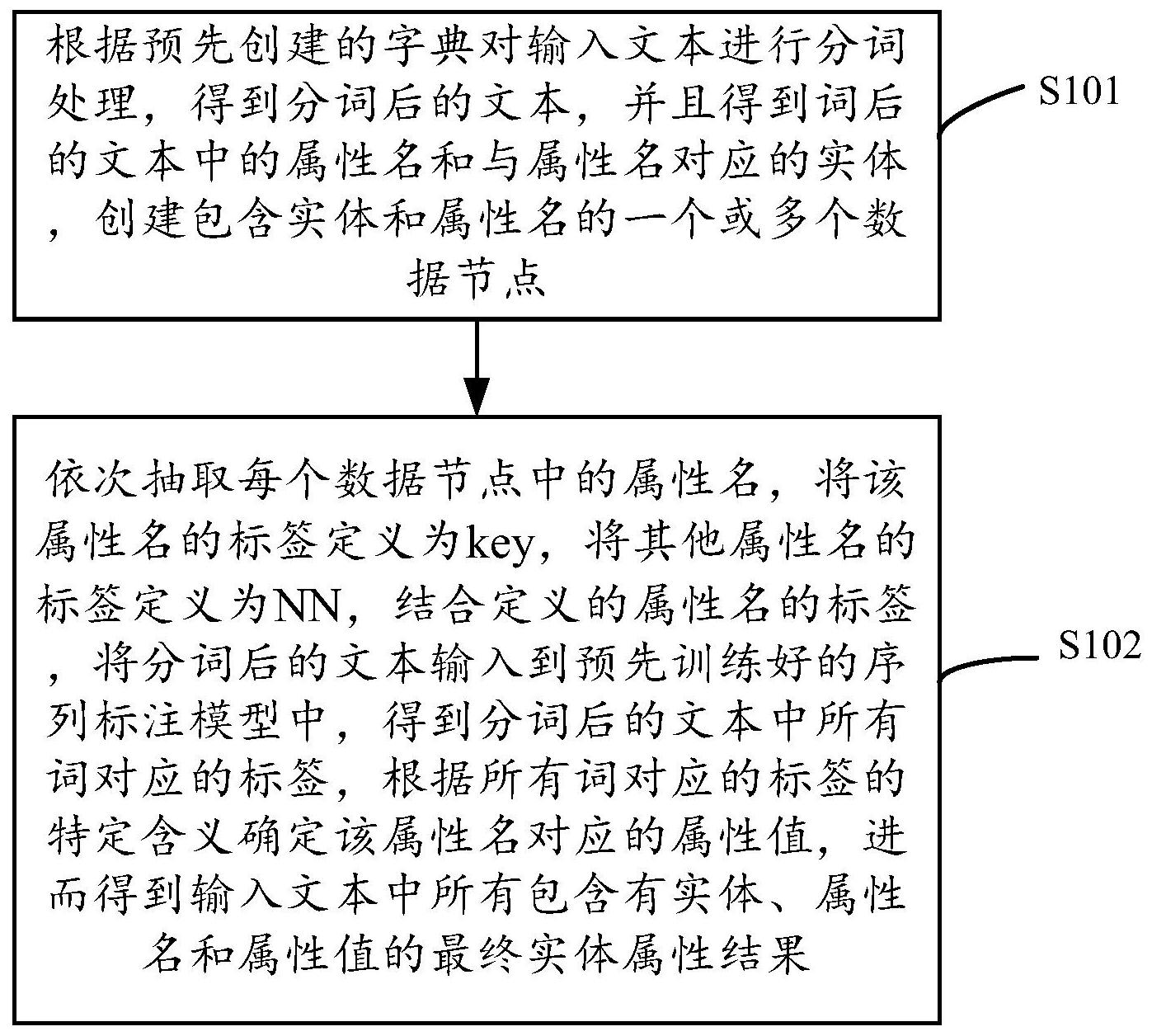
本发明公开了一种基于字典和序列标注模型的实体属性抽取方法、系统及设备,所述方法包括:根据预先创建的字典对输入文本进行分词处理,得到分词后的文本,并且得到分词后的文本中的属性名和与属性名对应的实体,创建包含实体和属性名的一个或多个数据节点;依次抽取每 全部
背景技术:
在现有技术中,实体通常是文本中描述的对象,例如人名、地名、机构名等,属性是 指实体中属性或者组成成分,例如:性别、姓名、年龄等。实体属性抽取是指从文本中抽取出 <实体,属性名,属性值>信息对。目前常用的方法有三种。 方法一:基于模板的抽取,首先规定需要抽取的实体属性信息,建立模板文件;然 后建立抽取的规则。这种方法可移植性差,只适用于半结构化的文本,如内容随时改变,但 结构往往是固定的网页; 方法二:基于字典匹配的抽取,基于人为整理的实体字典、属性名到实体字典、属 性值到属性名字典这三种先验知识,匹配得到文本中实体属性信息。这种方法不适用于属 性值不能穷举的情况,例如,数值性的属性值。 方法三:基于统计的序列标注模型的抽取,将实体属性的抽取简化为命名实体标 注,利用序列标注模型捕获输入文本的上下文语义以及输出标签的前后关系。该方法不适 用于文本中出现多个实体或属性的情况。 在工业领域的问答或搜索中实体属性抽取方法,一般采用后两种方法或其混合方 法。由于中文表达形式丰富多样,对于以下形式的表述采用这两种方法是不适用的: (1)、若文本中包含多个实体属性,如“井深为100米、井型为水平井的井有哪些?” 文本中对于实体“井”有两个属性<井深,100米>、<井型,水平井>,因属性名“井深”的对应的 属性值包含数字,是不可穷举,所以不能用基于字典的匹配来抽取属性值。若采用基于统计 的序列标注模型进行抽取,例如,条件随机场(Conditional Random Fields简称为CRF) ,为 了得到属性名和属性值的一一对应关系,需要对不同的<属性名,属性值>打上不同含义的 标签,如:“井深”:key_1,“100米”:value_1,“井型”:key_2,“水平井”:value_2。以便后续根 据标签的含义,找到属性名和属性值对应关系。采用统计的序列标注模型,需要提前定义好 标签的含义、种类以及数量,但是文本中包含属性对的数量是不可控,且不同的属性值一般 出现的上下文语境是相似的,若对其打上不同类型的标签,不利于序列标注模型在训练时 特征的抽取,从而最终影响属性抽取的效果。 (2)、多个属性名对应一个属性值时,如“产水量和产液量都是100顿的井有哪些?” 问题中实体“井”有两个属性<产水量,100顿>、<产液量,100顿>,因为两个属性值均不可穷 举,所以也不能基于字典的匹配来抽取属性值。两个属性值均是“100顿”,且该词在问句中 只出现过一次,而统计的序列标注模型目前不能将文本中同一个词或字打上不同的标签, 从而不能将属性值“100顿”对应到两个属性名上。 综上所述,现有技术中的实体属性抽取存在以下问题需要解决:1、属性值多样性 问题;2、因文本中属性个数的不确定导致标签种类和数目难以确定的问题;3、多个属性名 5 CN 111611799 A 说 明 书 2/12 页 对应一个属性值引起的属性名和属性值难以对应的问题。目前亟须一种技术方案来解决上 述技术问题。
技术实现要素:
本发明的目的在于提供一种基于字典和序列标注模型的实体属性抽取方法、系统 及设备,旨在解决现有技术中的上述问题。 本发明提供一种基于字典和序列标注模型的实体属性抽取方法,包括: 根据预先创建的字典对输入文本进行分词处理,得到分词后的文本,并且得到分 词后的文本中的属性名和与属性名对应的实体,创建包含实体和属性名的一个或多个数据 节点; 依次抽取每个数据节点中的属性名,将该属性名的标签定义为key,将其他属性名 的标签定义为NN,结合定义的属性名的标签,将分词后的文本输入到预先训练好的序列标 注模型中,得到分词后的文本中所有词对应的标签,根据所有词对应的标签的特定含义确 定该属性名对应的属性值,进而得到输入文本中所有包含有实体、属性名和属性值的最终 实体属性结果。 本发明提供一种基于字典和序列标注模型的实体属性抽取系统,包括: 数据层,用于对序列标注模型训练所需的数据以及语义加工中所需的字典进行管 理; 模型层,用于进行序列标注模型的训练和优化,并保存训练好的序列标注模型; 应用层,用于接收输入文本,并展示最终实体属性结果; 语义加工层,用于根据预先创建的字典对输入文本进行分词处理,得到分词后的 文本,并且得到分词后的文本中的属性名和与属性名对应的实体,创建包含实体和属性名 的一个或多个数据节点;依次抽取每个数据节点中的属性名,将该属性名的标签定义为 key,将其他属性名的标签定义为NN,结合定义的属性名的标签,将分词后的文本输入到预 先训练好的序列标注模型中,得到分词后的文本中所有词对应的标签,根据所有词对应的 标签的特定含义确定该属性名对应的属性值,进而得到输入文本中所有包含有实体、属性 名和属性值的最终实体属性结果。 本发明实施例还提供一种基于字典和序列标注模型的实体属性抽取设备,包括: 存储器、处理器及存储在所述存储器上并可在所述处理器上运行的计算机程序,所述计算 机程序被所述处理器执行时实现上述基于字典和序列标注模型的实体属性抽取方法的步 骤。 本发明实施例还提供一种计算机可读存储介质,所述计算机可读存储介质上存储 有信息传递的实现程序,所述程序被处理器执行时实现上述基于字典和序列标注模型的实 体属性抽取方法的步骤。 采用本发明实施例,在快速灵活的进行实体属性的抽取的同时提升计算速度,实 现工业领域中问答或搜索等短文本的信息抽取。 上述说明仅是本发明技术方案的概述,为了能够更清楚了解本发明的技术手段, 而可依照说明书的内容予以实施,并且为了让本发明的上述和其它目的、特征和优点能够 更明显易懂,以下特举本发明的











