
技术摘要:
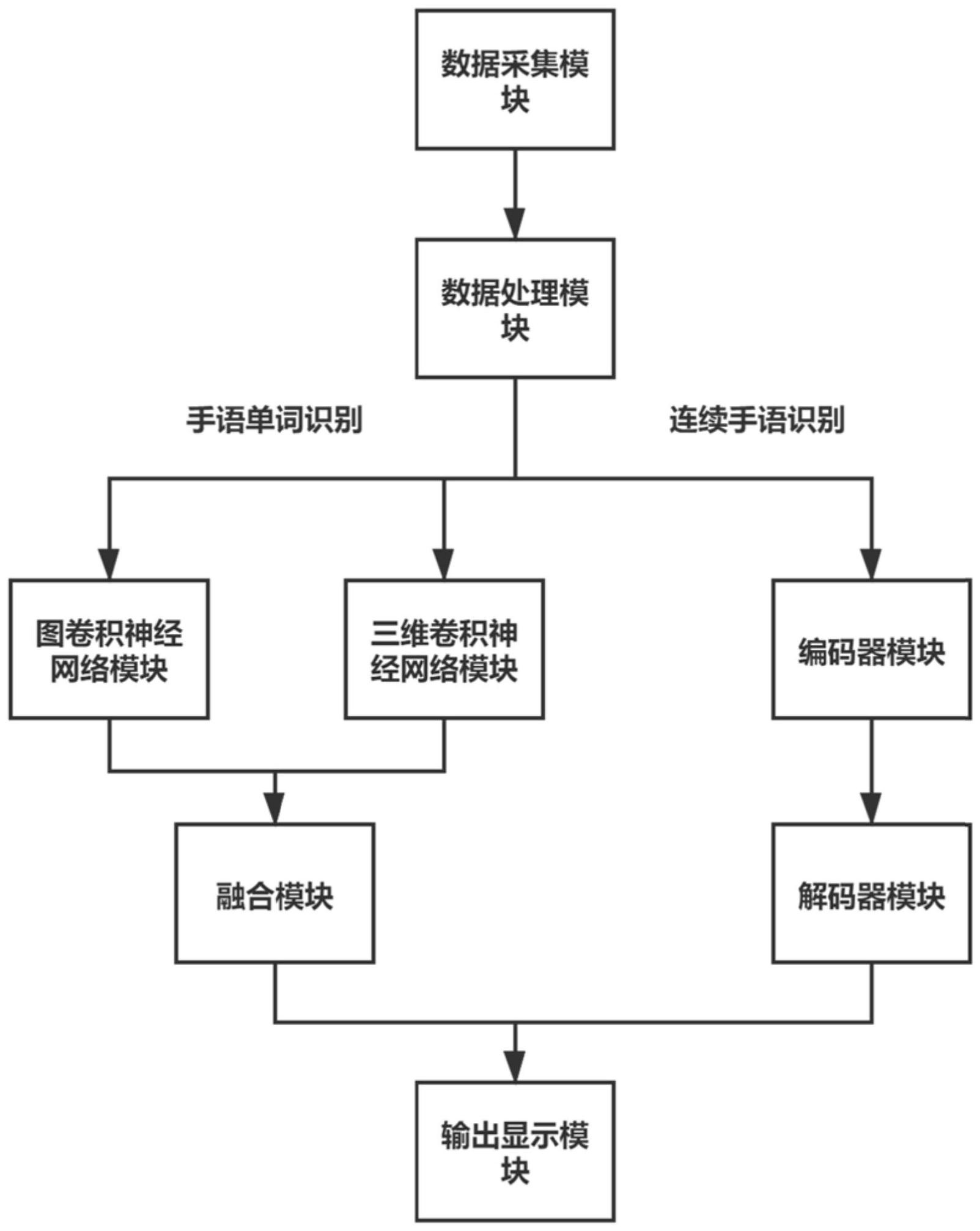
本发明公开了一种基于深度学习的中文手语识别系统。该手语识别系统设为手语单词识别和连续手语识别两个模式,分别用于对手语动作表达的单词和句子进行识别。整个系统由数据采集模块、数据处理模块、识别模块和输出显示模块组成,其中手语单词识别模块由图卷积神经网络 全部
背景技术:
手语是一种不使用语音,通过手势、肢体动作和面部表情等方式表达的一种语言。 它是听力障碍人士之间进行沟通交流的主要方式,普通人如果没有专门的学习,很难与听 力障碍人士进行沟通。手语识别旨在将手语转换为语音或文本,促进听力障碍人士与普通 人之间的交流。手语识别任务具有广泛的社会需求。根据世界卫生组织的统计,全球大约有 4.66亿人患有残疾性听力损失,超过世界人口5%。听力损失给这些人口带来了难以想象的 不便,听力障碍人士很难与普通人交流,面临巨大的社会压力。因此,设计一套通用的手语 识别系统解决这些问题是十分必要的。 手语识别任务可以分为手语单词识别和连续手语识别。手语单词识别对一个单词 进行识别,连续手语识别对一个完整句子进行识别。输入的数据来源包括视频、骨架信息 等。传统的方法使用数据手套采集数据,将手语的手势、肢体动作等转换为手工设计的特 征,然后利用这些特征通过机器学习的方法对手语进行分类,完成识别的任务。由于手工特 征的表示能力有限和数据手套使用不够便利,这些方法不具有足够的鲁棒性和实用性。
技术实现要素:
针对手语识别任务的社会需求和存在的问题,本发明提供了一种基于深度学习的 中文手语识别系统,实用性强、鲁棒性高、使用方便、成本低,便于推广使用。本发明能够对 500类中文手语单词和100类中文手语句子进行识别,并实时显示识别结果,克服听力障碍 人士和普通人之间的沟通障碍。 本发明所采用的具体技术方案是: 一种基于深度学习的中文手语识别系统,其包含: 数据采集模块,用于采集人体作出手语动作时RGB图像和人体关节数据; 数据处理模块,用于对所述数据采集模块采集的RGB图像进行大小调整,并对像素 值进行归一化; 手语单词识别模块,由图卷积神经网络模块、三维卷积神经网络模块和融合模块 组成,用于对手语动作表达的手语单词进行识别; 所述图卷积神经网络模块基于所述数据采集模块采集的人体关节数据构建一张 关节图,并对所有相邻节点进行图卷积,进而输出手语单词类别的概率分布,其中相邻节点 同时包括空间维度的相邻节点和时间维度的相邻节点; 所述三维卷积神经网络模块利用包含空间维度和时间维度的三维卷积核对所述 数据处理模块处理后的RGB图像进行卷积,提取RGB图像的空间时间特征,进而输出手语单 词类别的概率分布; 5 CN 111723779 A 说 明 书 2/8 页 所述融合模块用于通过加权平均对图卷积神经网络模块和三维卷积神经网络模 块的输出结果进行融合,得到最终的手语单词预测结果; 连续手语识别模块,由编码器模块和解码器模块组成,用于对连续手语动作表达 的完整句子进行识别; 所述编码器模块包括卷积神经网络和循环神经网络,用于分别提取连续手语的空 间特征和时间特征,并生成连续手语动作的全局语义信息; 所述解码器模块采用循环神经网络,利用编码器编码的全局语义信息、上一时刻 的输出和循环神经网络的隐藏层状态,预测下一时刻的输出。 输出显示模块,用于供用户选择手语单词识别模式或连续手语识别模式,并根据 用户的选择显示手语单词识别模块或连续手语识别模块的输出结果。 作为优选,所述的数据采集模块使用Kinect深度相机,能同时采集人体作出手语 动作时的RGB图像和25个人体关节数据。 作为优选,所述的数据处理模块将数据采集模块采集的RGB图像大小调整为224* 224的图像,并对像素值进行归一化,使其满足均值和标准差都是0.5的高斯分布。 作为优选,所述的图卷积神经网络模块中,具体过程如下: 11)首先基于数据采集模块采集的人体关节数据构建一张关节图,关节图的节点 对应人体关节点的坐标信息,关节图的边对应关节点之间的连接,并在时间维度上将相同 的节点连接起来; 12)然后对关节图进行图卷积运算;运算过程中,根据给定的K×K大小的卷积核, 以及通道数为c的输入特征fin,单个通道在空间位置x的输出fout(x)为: 其中:fin(v)表示输入特征fin中v节点的特征值,w(v)表示v节点的权重;B(vti)为 需要遍历的节点集合,其中: B(vti)={vqj|d(vti,vqj)≤D,|q-t|≤T} 式中:d(vti,vqj)表示节点vti和节点vqj之间的距离,vti是t时刻在位置x的节点,vqj 是指q时刻在卷积核范围内位置x附近的节点;D为空间维度上的距离阈值,T为时间维度上 的距离阈值; 所有通道的输出经过加权求和,得到单张关节图的特征; 13)通过全连接层将单张关节图中提取的特征映射为手语单词类别的概率分布, 并通过归一化函数进行归一化。 作为优选,所述的三维卷积神经网络模块使用多层的三维深度残差网络,其中每 层残差网络中的具体过程如下: 21)残差网络的输入I大小为C×T×H×W,其中C是通道数量,T是时间维度上的长 度,H和W分别是图像的长和宽,网络通过三维的卷积核w对图像进行卷积操作: 其中:F(x,y,t)表示卷积结果,x和y代表图像中的像素坐标,t代表图像序列中的 6 CN 111723779 A 说 明 书 3/8 页 位置,c代表图像的通道c,δx、δy和δt分别表示图像长度、宽度和时间维度上的偏移量,b代 表偏置; 在网络的基础上添加恒等映射,将网络转换为学习一个残差函数H(I)=F(I) I, 其中F(I)是网络输入I的卷积结果,H(I)是当前层残差网络的输出,同时作为下一层残差网 络的输入; 22)三维深度残差网络提取RGB图像的空间时间特征后,通过一层全连接层将特征 映射为手语单词类别的概率分布,并归一化。 作为优选,所述的融合模块中,具体融合过程如下: 获取图卷积神经网络模块输出的手语单词类别的概率分布向量与三维卷积神经 网络输出的手语单词类别的概率分布向量,概率分布向量中的数值均在0~1之间,代表的 是每一类手语单词的概率大小;将两个向量中的概率值一一对应进行加权平均计算,得到 最终输出的概率分布向量。 进一步的,所述的融合模块中,进行加权平均计算时,图卷积神经网络模块和三维 卷积神经网络的输出向量的权值分别优选为0.4和0.6。 作为优选,所述的编码器模块中,卷积神经网络是多层的深度残差网络,循环神经 网络是长短期记忆网络;所述编码器接收可变长度的图像序列作为输入,首先使用深度残 差网络对每一帧图像的空间特征进行提取,然后通过长短期记忆网络完成对连续手语视频 的语义编码;长短期记忆网络以卷积神经网络提取的空间特征作为输入,不断地更新隐藏 层状态,隐藏层状态包含时间维度的特征;对所有时间步的隐藏层状态进行平均,得到编码 后的语义向量c,作为解码器的输入: 其中T′是输入的序列长度,ht是循环神经网络在t时刻的隐藏层状态。 作为优选,所述的解码器模块中,解码器由一个长短期记忆网络、一个词嵌入层和 一个全连接层组成,长短期记忆网络使用编码器最后一个时刻的隐藏层状态进行初始化; 词嵌入层对上一时刻输出的单词提取语义向量,然后将其与编码器编码的特征进行连接, 作为长短期记忆网络的输入;长短期记忆网络更新后,全连接层将当前时刻的隐藏层状态 作为输入,生成当前输出的单词的概率分布,最终选择概率最高的单词作为输出。 作为优选,所述的编码器模块和解码器模块中,长短期记忆网络均采用双向长短 期记忆网络。 作为优选,所述的输出显示模块中,能够选择手语识别模式,并实时输出概率最高 的前五个候选结果。 相对于现有技术而言,本发明具有以下有益效果如下: 1)本发明中,图卷积神经网络能够有效地对关节数据进行处理。关节数据实际上 是一张拓扑图,而非网格数据形式,这导致它难以使用卷积神经网络进行特征提取。通过图 卷积的方式,能够充分地利用关节数据的拓扑结构,提取关节点之间的内在联系。 2)本发明中,三维卷积神经网络能够同时对空间维度和时间维度进行卷积操作, 直接提取手语动作的空间时间特征。深度为18的三维深度残差兼顾了识别准确率和运行速 7 CN 111723779 A 说 明 书 4/8 页 度,既保持了一定的识别准确率,也提高了运行时的速度。 3)本发明中,使用多模态的数据作为输入,并对关节数据和RGB图像的识别结果进 行融合,提高了手语识别系统的鲁棒性、稳定性。 4)本发明中,编码器-解码器结构能够更充分地利用手语动作的全局特征,并学习 连续手语的语言模型,能够有效地解决连续手语识别这一序列到序列问题,学习手语视频 和它表达的句子之间的映射关系。 附图说明 图1是本发明的系统框架图。 图2是本发明的数据处理模块程序框架图。 图3是本发明的图卷积神经网络模块的算法流程图。 图4是本发明的三维卷积神经网络模块的算法流程图。 图5为本发明的编码器-解码器模块的网络结构图。 图6为本发明的输出显示模块的“主页”界面示意图。 图7为本发明的输出显示模块的“手语单词识别”界面示意图。 图8为本发明的输出显示模块的“连续手语识别”界面示意图。











