 技术摘要:
技术摘要: 本发明提供了一种包含两个单体的多肽二聚体蛋白,每个单体包含IgE Fc受体的α亚基的胞外域(FcεRIa‑ECD)。与包含抗IgE抗体的常规治疗剂相比,本发明的二聚体蛋白显示出具有对IgE优异结合能力的优点,并且由于其缺乏ADCC和CDC功能而表现出较少的其他副作用。因此,该二 全部
背景技术:
在工业化和西方化的现代社会中过敏性鼻炎、特应性皮炎和食物过敏(包括哮喘)
等过敏性疾病正在迅速蔓延,过敏性休克是一种严重的过敏性疾病,其发病人数也在增加。
这些慢性免疫疾病严重损害了人们的生活质量,社会的经济成本也随之飙升。因此,迫切需
要治疗这些疾病的方法。
大多数过敏性疾病是由免疫球蛋白E(IgE)的过度免疫反应引起的。IgE是一种抗
体,在正常条件下其以非常低的浓度存在于血清中。IgE通常也可由无害的抗原产生。在某
些情况下,在没有任何特定的刺激下IgE的数量会增加。这种情况可能会导致过敏性疾病。
数量异常增加的IgE可以与肥大细胞、嗜碱性粒细胞等表面表达的高亲和力的IgE Fc受体
(FcεRI)结合。这种结合导致了肥大细胞或嗜碱性粒细胞释放例如组胺、白三烯、前列腺素、
缓激肽和血小板活化因子等化学介质。这些化学介质的释放导致了过敏症状。特别是由于
IgE和FcεRI之间的结合,过敏性疾病的症状可能会加重。已知在过敏患者中,表达了FcεRI
的细胞有所增加。
目前治疗过敏性疾病的多种方法已被提出,例如避免过敏原、施用抗过敏药、调节
体内IgE的合成以及开发抗IgE抗体。然而,迄今为止已知的治疗方法具有众多缺点,例如无
法治愈过敏的根本原因、药物功效不足以及所发生的严重副作用。
此外,已经研究出能够以高亲和力结合IgE和FcεRIIb并抑制表达IgE的细胞的免
疫球蛋白组合物(KR10-1783272B1)。据报道这种组合物可用于治疗IgE介导的疾病,包括过
敏症和哮喘。另外,已经开发出靶向IgE抗体的Fc部分的奥马珠单抗(omalizumab,商品名:
Xolair),并将其用作顽固性重度哮喘和顽固性荨麻疹的治疗剂。
然而,大剂量的奥马珠单抗的给药以维持治疗效果会导致高成本负担,以及诸如
血管性水肿和过敏反应等副作用(The Journal of Clinical Investigation Volume 99,
Number 5,March 1997,915-925)。此外,从上市后的结果来看,有发生变应性肉芽肿性血管
炎和特发性严重血小板减少症的报道。因此,急需开发能够有效治疗过敏性疾病而没有副
作用的治疗剂。
技术问题
本发明的目的是提供用于治疗IgE介导的过敏性疾病的多肽二聚体蛋白。本发明
的另一个目的是提供编码该蛋白质的核酸分子、包含该核酸分子的表达载体和包含该表达
载体的宿主细胞。本发明的又一个目的是提供一种制备该多肽二聚体的方法。
解决问题
为了实现上述目的,本发明提供了一种多肽二聚体,其包含两个单体,每个单体包
含IgE Fc受体的α亚基的胞外域。所述单体包含经修饰的Fc区,并且经修饰的Fc区和IgE Fc
4
CN 111587251 A 说 明 书 2/17 页
受体的α亚基的胞外域通过IgD抗体的铰链连接。在另一方面,本发明提供了用于治疗或预
防过敏性疾病的药物组合物,其包含多肽二聚体作为活性成分。
发明的有益效果
与常规使用的抗IgE抗体相比,本发明的多肽二聚蛋白不仅在体内具有优异的安
全性和持久性,而且与IgE的结合也非常强,其与IgE的结合能力较常规使用的抗IgE抗体奥
马珠单抗(omalizumab)高出70倍,因此可以延长给药周期。另外,本发明的多肽二聚体蛋白
是通过采用经修饰的Fc获得的产物,所述经修饰的Fc仅具有IgE作为单个靶标并且不与Fc
单受体结合,使得本发明的多肽二聚体蛋白缺乏抗体依赖性细胞毒性(ADCC)和补体依赖性
细胞毒性(CDC)功能。因此,与包含IgG1 Fc区的常规抗IgE抗体不同,该多肽二聚体蛋白不
与Fc不受体结合,从而可以抑制由于与肥大细胞表面的Fc抑受体结合而导致的介体释放,
使得例如由于IgG1与肥大细胞上Fc大受体III之间的结合而导致的过敏性休克等严重的副
作用最小化。因此,本发明的多肽二聚体蛋白可以用作新的药物组合物,其可以代替含有常
规抗IgE抗体的治疗剂。
附图说明
图1显示了在每个细胞系中产生的蛋白质的SDS-PAGE和凝胶等电聚焦(IEF)的结
果。可以看出,在还原条件和非还原条件下均未产生截短的形式,并且引入唾液酸转移酶基
因之后会导致唾液酸含量的增加,从而导致酸性蛋白质的含量增加。
图2说明了本发明的一个实施方案中非还原形式和还原形式的多肽二聚体蛋白质
的SDS-PAGE结果。特别地,可以看出即使在对应于输入的培养上清液中,多肽二聚体也具有
高纯度。
图3显示了奥马珠单抗与IgE的结合能力的图。该图显示了通过固定奥马珠单抗并
根据所处理的IgE浓度分析其结合能力而获得的结果。
图4显示了本发明的一个实施方案中多肽二聚体蛋白对IgE的结合能力的图。该图
显示了通过固定二聚体蛋白并根据所处理的IgE浓度分析其结合能力而获得的结果。
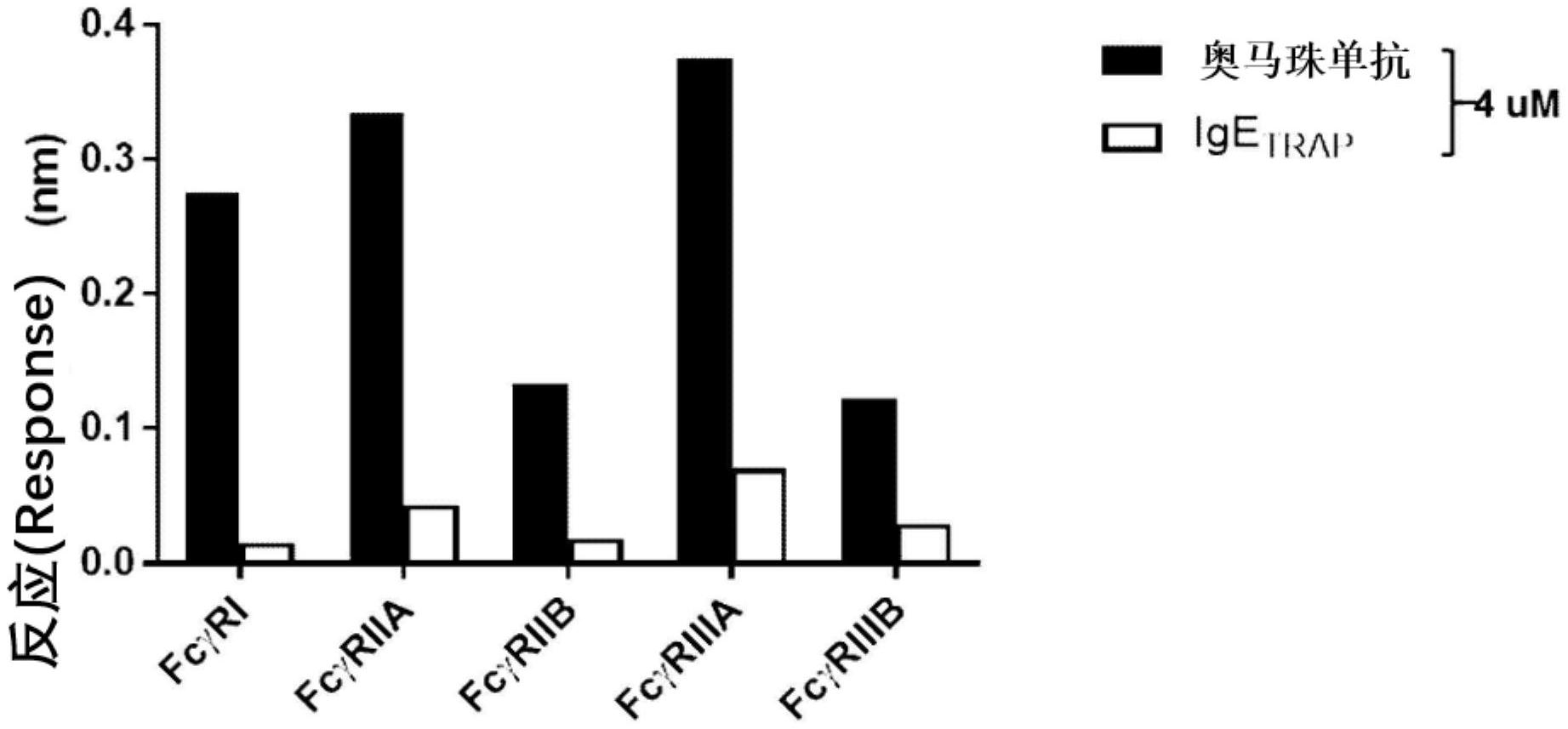
图5显示了通过生物层干涉法(BLI)测定本发明的一个实施方案中多肽二聚体蛋
白(IgETRAP)和奥马珠单抗与IgG受体FcγRI(图5A)、FcγRIIA(图5B)、FcγRIIB(图5C)、Fc
γRIIIA(图5D)和FcγRIIIB(图5E)的相互作用。
图6显示了通过量化IgETRAP和IgG受体之间以及奥马珠单抗和IgG受体之间的结合
能力而获得的图。
图7显示了本发明的一个实施方案中多肽二聚体蛋白(IgETRAP)在不同浓度下对小
鼠来源的肥大细胞的活性的抑制能力的图。
图8显示了本发明的一个实施方案中多肽二聚体蛋白(IgETRAP)和Xolair(奥马珠
单抗)对表达人FcεRI的小鼠源性肥大细胞的活性的抑制能力的比较的图。
图9示显示了本发明的一个实施方案中多肽二聚体蛋白在食物过敏模型中施用的
效果图。
发明详述
本发明涉及一种多肽二聚体,其包含两个单体,每个单体包含IgE Fc受体的α亚基
的胞外域(FcεRIa-ECD),其中所述单体包含经修饰的Fc区,并且该经修饰的Fc区和该Fcε
5
CN 111587251 A 说 明 书 3/17 页
RIa-ECD通过IgD抗体的铰链连接。
如本发明所用,术语“IgE”是指称为免疫球蛋白E的抗体蛋白。IgE对肥大细胞、嗜
血嗜碱性粒细胞等具有亲和力。另外,IgE抗体和与其对应的抗原(变应原)之间的反应会引
起炎症反应。另外,已知IgE是引起过敏性休克(anaphylaxis)的抗体,通常由于肥大细胞或
嗜碱性粒细胞的突然分泌而发生过敏性休克。
如本发明所用,术语“IgE Fc受体”也称为Fcε受体,并与IgE的Fc部分结合。该受体
有两种类型。对IgE Fc具有高亲和力的受体称为Fcε受体I(Fc RI)。对IgE Fc具有低亲和力
的受体称为Fcε受体II(FcεRII)。FcεRI在肥大细胞和嗜碱性粒细胞中表达。在与FcεRI结合
的IgE抗体被多价抗原交联的情况下,肥大细胞或嗜碱性粒细胞中发生脱粒,从而释放出包
括组胺在内的各种化学递质。这种释放导致立即发生的过敏反应。
FcεRI是由二硫键连接的一条α链、一条β链和两条γ链组成的膜蛋白。在这些链
中,与IgE结合的部分是α链(FcεRIα)。FcεRIα的大小约为60kDa,并且由存在于细胞膜内的
疏水域和存在于细胞膜外的亲水域组成。特别地,IgE结合至α链的胞外域。
具体地,IgE Fc受体的α亚基可以具有如NP_001992.1中所示的氨基酸序列。此外,
IgE Fc受体的α亚基的胞外域(FcεRIa-ECD)可以具有如SEQ ID NO:1所示的氨基酸序列。在
本说明书中,IgE Fc受体的α亚基的胞外域可以是IgE Fc受体的α亚基的胞外域的片段或变
体,只要该片段或变体能够结合IgE即可。
可以通过在野生型FcεRIa-ECD(胞外域)中取代、缺失或插入一种或多种蛋白质的
方法来制备变体,只要该方法不改变FcεRI的α链的功能即可。此类的多种蛋白质或肽可以
与SEQ ID NO:1的氨基酸序列具有90%、91%、92%、93%、94%、95%、96%、97%、98%、
99%或更高的同源性。此外,如SEQ ID NO:1所示的FcεRIa-ECD可以由具有如SEQ ID NO:5
所示序列的多核苷酸编码。
另外,如本发明所用,术语“经修饰的Fc区”是指抗体的Fc部分的其中一部分已被
修饰的区域。其中,术语“Fc区”是指包含免疫球蛋白的重链恒定区2(CH2)和重链恒定区3
(CH3)、并且不包含免疫球蛋白的重链和轻链可变区以及轻链恒定区1(CH1)的蛋白质。特别
地,经修饰的Fc区是指通过在Fc区中进行一些氨基酸取代或通过组合不同类型的Fc区而获
得的区域。具体地,经修饰的Fc区可以具有如SEQ ID NO:2所示的氨基酸序列。此外,如SEQ
ID NO:2所示的经修饰的Fc区可以由具有如SEQ ID NO:6所示序列的多核苷酸编码。
另外,本发明中的“经修饰的Fc区”可以是具有天然形式的糖链、相对于天然形式
有增加的糖链或相对于天然形式有较少的糖链的形式,或者可以是被去除糖链的形式。可
以通过例如化学方法、酶促方法和使用微生物的基因工程方法等常规方法来修饰免疫球蛋
白Fc的糖链。
其中,本发明中的“经修饰的Fc区”可以是由于没有与FcγR或C1q的结合位点而缺
乏抗体依赖性细胞毒性(ADCC)和补体依赖性细胞毒性(CDC)功能的区域。另外,经修饰的Fc
区和FcεRIα-ECD可以通过IgD抗体的铰链连接。IgD抗体的铰链由64个氨基酸组成,并且可
以选择性地包含20-60个连续的氨基酸、25-50个连续的氨基酸或30-40个氨基酸。在一个实
施方案中,IgD抗体的铰链可以由30个或49个氨基酸组成,如下所示。另外,IgD抗体的铰链
可以是通过修饰铰链区域而获得的铰链变体,其中铰链可以包含至少一个半胱氨酸。此处,
铰链的变体可以通过修饰IgD抗体的铰链序列中的一些氨基酸而获得,以使得在蛋白生产
6
CN 111587251 A 说 明 书 4/17 页
过程中最小化截短形式的产生。
在一个实施方案中,所述铰链可以包含以下序列:
Arg Asn Thr Gly Arg Gly Gly Glu Glu Lys Lys Xaa1 Xaa2 Lys Glu Lys Glu
Glu Gln Glu Glu Arg Glu Thr Lys Thr Pro Glu Cys Pro(SEQ ID NO:17),其中Xaa1可
以是Lys或Gly,Xaa2可以是Glu、Gly或Ser。具体地,所述铰链可具有如SEQ ID NO:3或SEQ
ID NO:19所示的氨基酸序列,从而使蛋白质在生产过程中产生的截短形式最小化。
在另一个实施方案中,所述铰链可以包含以下序列:
Ala Gln Pro Gln Ala Glu Gly Ser Leu Ala Lys Ala Thr Thr Ala Pro Ala
Thr Thr Arg Asn Thr Gly Arg Gly Gly Glu Glu Lys Lys Xaa3 Xaa4 Lys Glu Lys Glu
Glu Gln Glu Glu Arg Glu Thr Lys Thr Pro Glu Cys Pro(SEQ ID NO:18),其中Xaa3可
以是Lys或Gly,Xaa4可以是Glu、Gly或Ser。具体地,所述铰链可具有如SEQ ID NO:4所示的
氨基酸序列,从而使蛋白质在生产过程中最小化截短形式的产生。
特别地,在具有如SEQ ID NO:4所示序列的铰链中,至少一个Thr可以被糖基化。具
体而言,在如SEQ ID NO:18所示的氨基酸中,第13、14、18或19个Thr可以被糖基化。优选地,
所有四个氨基酸都可以被糖基化。其中,所述的糖基化可以是O-糖基化。
另外,如上所述,本发明提供的多肽二聚体可以是以下形式:其中两个单体彼此结
合,并且每个单体通过IgE Fc受体的α亚基的胞外域与修饰的Fc区结合而得。多肽二聚体可
以是相同的两个单体通过位于铰链位点的半胱氨酸彼此结合的形式。此外,多肽二聚体可
以是两种不同单体彼此结合的形式。例如,在两种单体彼此不同的情况下,多肽二聚体可以
是其中一种单体包含IgE Fc受体的α亚基的胞外域,而另一种单体包含IgE Fc受体的α亚基
的胞外域的片段的形式。其中,一个实施方案中单体可以具有如SEQ ID NO:20、SEQ ID NO:
21或SEQ ID NO:22所示的氨基酸序列。
另外,本发明提供的多肽二聚体表现出与IgE的结合能力,其结合能力比抗IgE抗
体奥马珠单抗高出10-100倍、20-90倍、20-70倍、30-70倍或40-70倍,并且可优选地表现出
比奥马珠单抗高70倍的对IgE的结合能力。
在本发明的另一个方面提供了一种编码单体的多核苷酸,该单体包含与经修饰的
Fc区结合的IgE Fc受体的α亚基的胞外域。
同时,多核苷酸可以额外包含信号序列或前导序列。如本发明所用,术语“信号序
列”是指编码指导靶蛋白分泌的信号肽的核酸。信号肽被翻译后会在宿主细胞中裂解。具体
地,本发明的信号序列是编码启动跨内质网(ER)膜的蛋白质易位的氨基酸序列的核苷酸。
在本发明中有用的信号序列包括抗体轻链信号序列,例如抗体14.18(Gillies et al .,
J.Immunol.Meth 1989.125:191-202),抗体重链信号序列,例如MOPC141抗体重链信号序列
(Sakano et al.,Nature,1980.286:676-683),以及本领域已知的其他信号序列(参见例如
Watson et al.,Nucleic Acid Research,1984.12:5145-5164)。
信号序列的性质在本领域中是众所周知的。信号序列通常包含16-30个氨基酸残
基,并且可以包含更多或更少的氨基酸残基。典型的信号肽由三个区域组成:碱性的N末端
区域、中间的疏水区域和极性更大的C末端区域。中间的疏水区含有4-12个疏水残基,其在
未成熟多肽的易位过程中通过膜脂质双层固定信号序列。
起始后,通常被称为信号肽酶的细胞酶在ER腔中切割信号序列。其中,信号序列可
7
CN 111587251 A 说 明 书 5/17 页
以是组织纤溶酶原激活物(tPA)、单纯疱疹病毒糖蛋白D(HSV gD)或生长激素的分泌信号序
列。优选地,可以使用在包括哺乳动物等的高等真核细胞中使用的分泌信号序列。此外,分
泌信号序列可以被宿主细胞中具有高表达频率的密码子取代并使用。
同时,与信号序列和经修饰的Fc区结合的IgE Fc受体的α亚基的胞外域单体可以
具有如SEQ ID NO:11或SEQ ID NO:13所示的氨基酸序列。如SEQ ID NO:11和SEQ ID NO:13
所示的蛋白质可以分别由具有如SEQ ID NO:12和SEQ ID NO:14所示序列的多核苷酸编码。
在本发明的又一个方面提供了一种表达载体,其装载有编码所述单体的多核苷
酸。其中,所述多核苷酸可以具有如SEQ ID NO:12或SEQ ID NO:14所示的序列。
如本发明所用,术语“载体”旨在被引入宿主细胞中并且能够与宿主细胞的基因组
重组并插入至其中。可选地,所述载体为附加体,并且被理解为包含可以自主复制的核苷酸
序列的核酸单元。所述载体包括线性核酸、质粒、噬菌粒、粘粒、RNA载体、病毒载体及其类似
物。所述病毒载体的实例包括但不限于逆转录病毒、腺病毒和腺相关病毒。另外,所述质粒
可以包含选择性标记如抗生素抗性基因,并且可以在选择性的条件下培养携带质粒的宿主
细胞。
如本发明所用,术语靶蛋白的“遗传表达”或“表达”应理解为是指DNA序列的转录、
mRNA转录物的翻译以及融合蛋白的产物或其片段的分泌。有用的表达载体可以是RcCMV
(Invitrogen,Carlsbad)或其变体。表达载体可以包含用于促进哺乳动物细胞中靶基因的
连续转录的人巨细胞病毒(CMV)启动子,以及用于提高转录后RNA的稳定性的牛生长激素多
聚腺苷酸化信号序列。
在本发明的又一个方面提供了一种导入有所述表达载体的宿主细胞。如本发明所
用,术语“宿主细胞”是指可将重组表达载体引入其中的原核细胞或真核细胞。如本发明所
用,术语“转导”、“转化”和“转染”是指使用本领域已知的技术将核酸(例如载体)引入细胞
中。
可用于本发明的优选的宿主细胞包括永生的杂交瘤细胞、NS/0骨髓瘤细胞、293细
胞、中国仓鼠卵巢细胞(CHO细胞)、HeLa细胞、人羊水来源的细胞(CapT细胞)或COS细胞。优
选地,宿主细胞可以是CHO细胞。另一方面,宿主细胞可以是其中导入了载体和负载有唾液
酸转移酶基因的载体的宿主细胞。其中,唾液酸转移酶可以是2,3-唾液酸转移酶或2,6-唾
液酸转移酶。其中,2,6-唾液酸转移酶可以具有如SEQ ID NO:15所示的氨基酸序列。
在本发明的又一方面提供了一种用于治疗或预防过敏性疾病的药物组合物,其包
含多肽二聚体作为活性成分。
在本说明书中,术语“过敏性疾病”是指由例如肥大细胞脱粒等肥大细胞活化介导
的过敏反应引起的病理症状。此类的过敏性疾病包括食物过敏、特应性皮炎、哮喘、过敏性
鼻炎、过敏性结膜炎、过敏性皮炎、过敏性接触性皮炎、过敏性休克、荨麻疹、瘙痒、昆虫过
敏、慢性特发性荨麻疹、药物过敏等。特别是,过敏性疾病可以是IgE介导的。
在本发明的用于治疗或预防过敏性疾病的组合物中,根据其用途、制剂、掺合目的
等可以包含任何量(有效量)的活性成分,只要该活性成分可以表现出抗过敏活性即可。所
述活性成分的常规的有效量可确定在组合物总重量的0.001%-20.0%的范围内。其中,“有
效量”是指能够引起抗过敏作用的活性成分的量。这种有效量可以在本领域技术人员的普
通技术范围内通过实验确定。
8
CN 111587251 A 说 明 书 6/17 页
其中,所述药物组合物可以进一步包含药学上可接受的载体。药学上可接受的载
体可以是使用任何载体,只要该载体是适合递送给患者的无毒物质即可。可以包含蒸馏水、
酒精、脂肪、蜡和惰性固体作为载体。药物组合物中也可以包含药学上可接受的佐剂(缓冲
剂和分散剂)。
具体地,本发明的药物组合物除了包含活性成分之外,还包含药学上可接受的载
体,并且可根据本领域已知的常规方法基于药物的给药途径制成口服或肠胃外制剂。其中,
术语“药学上可接受的”是指其毒性不超过所施用(处方)的受试者所能容纳的程度,不抑制
活性成分的活性。
在将本发明的药物组合物制成口服制剂的情况下,可以将药物组合物根据现有技
术中已知的方法制成粉剂、颗粒剂、片剂、丸剂、糖衣片、胶囊剂、液体制剂、凝胶剂、糖浆剂、
混悬剂、晶片,以及合适的载体。其中,合适的药学上可接受的载体的实例可以包括糖例如
乳糖、葡萄糖、蔗糖、右旋糖、山梨糖醇、甘露醇和木糖醇,淀粉例如玉米淀粉、马铃薯淀粉和
小麦淀粉,纤维素例如纤维素、甲基纤维素、乙基纤维素、羧甲基纤维素钠以及羟丙基甲基
纤维素、聚乙烯吡咯烷酮、水、羟基苯甲酸甲酯(methylhydroxybenzoate)、羟基苯甲酸丙酯
(propylhydroxybenzoate)、硬脂酸镁、矿物油、麦芽、明胶,滑石粉、多元醇、植物油等。在制
成制剂的情况下,可以根据需要添加稀释剂和/或赋形剂如填充剂、增量剂、粘合剂、湿润
剂、崩解剂和表面活性剂来进行制备。
在将本发明的药物组合物制成肠胃外制剂的情况下,可以根据本领域已知的方法
将所述药物组合物与合适的载体一起制成注射剂、透皮药物、鼻吸入剂和栓剂形式的制剂。
在制备成注射剂的情况下,可以将无菌水、乙醇、如甘油和丙二醇等多元醇或其混合物作为
合适的载体。对于载体而言,可以优选使用等渗溶液如林格氏溶液(Ringer's solution)、
含有三乙醇胺的磷酸盐缓冲盐水(PBS)、注射用无菌水和5%右旋糖等。
药物组合物的制备是本领域已知的,具体地,可以参考雷明顿药物科学
(Remington's Pharmaceutical Sciences)(第19版,1995)等。该文献应当被认为是本说明
书的一部分。
根据患者的状况、体重、性别、年龄、疾病严重程度或给药途径,本发明的药物组合
物的优选的日剂量范围为0.01μg/kg-10g/kg,并且优选为0.01mg/kg-1g/kg。每天可进行一
次或多次给药。此类的剂量决不应被解释为对本发明范围的限制。
可以施用(开处方)本发明组合物的受试者可以为哺乳动物和人,特别优选为人。
除了活性成分之外,本发明的用于抗过敏的组合物还可包含其安全性已被验证以及已知其
具有抗过敏活性的任何化合物或天然提取物,从而提高并增强其抗过敏活性。
本发明的另一方面提供了一种用于改善和减轻过敏症状的食品组合物,其包含多
肽二聚体作为活性成分。
其中,所述多肽二聚体可以与合适的递送单位结合以有效地递送到肠中。可以以
任何形式制备本发明的食品组合物,可以例如以饮料例如茶、果汁、碳酸饮料和离子饮料,
加工乳制品例如牛奶和酸奶,具有健康功能食品制剂例如片剂、胶囊剂、丸剂、颗粒剂、液体
制剂、粉剂、薄片、糊剂、糖浆剂、胶状、凝胶剂和棒剂等形式进行制备。另外,本发明的食品
组合物可以落入合法的任何产品类别或功能分类中,只要该食品组合物在制造和分发时符
合执行法规即可。例如,所述的食品组合物可以是《健康功能食品法(Health Functional
9
CN 111587251 A 说 明 书 7/17 页
Foods Act)》中所述的健康功能食品,或可以是《食品卫生法的食品法规(Food Code of
Food Sanitation Act)》(食品标准和规格,由食品药品监督管理局颁布)中所述的属于糖
果、豆类、茶、饮料、特殊用途食品等的各种食品类型。关于可以包含在本发明的食品组合物
中的其他食品添加剂,可以参考食品卫生法(Food Sanitation Act)的食品法规(Food
Code)或食品添加剂法规(Food Additive Code)。
本发明的另一方面提供了一种生产多肽二聚体的方法,该方法包括培养宿主细胞
的步骤,该宿主细胞中引入了编码单体和唾液酸转移酶基因的多核苷酸;和回收多肽二聚
体的步骤。
其中,可以将编码单体的多核苷酸以装载在表达载体上的形式引入宿主细胞。另
外,可以将唾液酸转移酶基因以装载在载体上的形式导入宿主细胞。
首先,进行将装载有编码单体的多核苷酸的载体和装载有唾液酸转移酶基因的载
体导入宿主细胞的步骤。其中,所述的唾液酸转移酶可以是2,3-唾液酸转移酶或2,6-唾液
酸转移酶。
接着,进行培养转化后的细胞的步骤。
最后,进行回收多肽二聚体的步骤。其中,可以从培养基或细胞提取物中纯化出所
述多肽二聚体。例如,获得其中分泌了多肽二聚体的培养基的上清液后,可以使用例如
Amicon或Millipore Pellicon超滤单元等市售的蛋白质浓缩滤器浓缩上清液。然后,可以
通过本领域已知的方法纯化浓缩物。例如,可以使用偶联至蛋白A的基质来实现纯化。
在本发明的又一方面提供了一种通过上述生产二聚体的方法生产的多肽二聚体。
其中,所述多肽二聚体具有高唾液酸含量,因此相对于理论pI值具有非常高的酸
性蛋白质含量。
在本发明的又一方面提供了一种用于治疗或预防过敏性疾病的药物组合物,其包
含通过上述生产二聚体的方法生产的多肽二聚体作为活性成分。
在本发明的又一方面提供了用于改善或减轻过敏症状的食品组合物,其包含通过
上述生产二聚体的方法生产的多肽二聚体作为活性成分。
在本发明的又一方面提供了一种用于治疗或预防过敏性疾病的方法,其包括向受
试者施用包含两个单体的多肽二聚体的步骤,所述两个单体各自包含IgE Fc受体的α亚基
的胞外域(FcεRIa-ECD)。
所述受试者可以是哺乳动物,优选是人类。其中,可以口服或肠胃外进行施用。其
中,肠胃外进行施用可以通过皮下给药、静脉内给药、粘膜给药和肌肉给药等方法进行。
技术实现要素:
在下文中,将参考以下实施例更详细地描述本发明。然而,以下实施例仅旨在解释
本发明,并且本发明的范围不仅限于此。
实施例1.含有FcεRIα-ECD和经修饰的Fc区的多肽的制备
根据美国专利号7,867,491中公开的方法,制备IgE Fc受体的α亚基的胞外域(Fcε
RIα-ECD)的C末端经修饰的多肽。
首先,为了表达如SEQ ID NO:1所示氨基酸序列的FcεRI的α链的胞外域和如SEQ
ID NO:2所示的经修饰的免疫球蛋白Fc分别通过如SEQ ID NO:19所示的铰链、如SEQ ID
10
CN 111587251 A 说 明 书 8/17 页
NO:3所示的铰链、如SEQ ID NO:4所示的铰链连接所得到的蛋白质(FcεRIαECD-Fc1)、蛋白
质(FcεRIαECD-Fc2)和蛋白质(FcεR1αECD-Fc3),将通过连接编码每种蛋白的基因获得的表
达盒克隆到pAD15载体(Genexin,Inc.)中,以构建FcεRIαECD-Fc蛋白表达载体。然后,将每
种表达载体转导至CHO DG44细胞(来自美国哥伦比亚大学的Chasin博士)。
其中,在转导至细胞系中时,同时转导通过将α-2,6--唾液酸转移酶的基因克隆至
pCI Hygro载体(Invitrogen)中而获得的表达载体,以分别制备能够表达添加了唾液酸的
FcεRIαECD-Fc2ST和FcεRIαECD-Fc3ST蛋白。
作为初步筛选程序,使用无5-羟色胺(HT)的10%dFBS培养基(Gibco,USA,30067-
334)、MEMα培养基(Gibco,12561,USA,目录号12561-049)和HT 培养基(USA,Gibco,11067-
030)进行HT筛选。然后,使用HT筛选出的克隆进行甲氨蝶呤(MTX)扩增,以使用二氢叶酸还
原酶(DHFR)系统扩增生产力。
在MTX扩增完成后,为了评估生产力,进行约1-5次传代培养以使细胞稳定。之后,
进行MTX扩增细胞的单位生产力评价。结果显示在下表1中。
表1
如表1所示,在2μM的甲氨蝶呤扩增后,FcεRIαECD-Fc3细胞系显示出16.9μg/106个
细胞的生产力。另一方面,在1μM的甲氨蝶呤扩增后,与2,6-唾液酸转移酶共转导的FcεRIα
ECD-Fc3细胞系(FcεRIαECD-Fc3ST)的生产力为17.5μg/106个细胞。此外,在0.5μM的甲氨蝶
呤扩增后,FcεRIαECD-Fc2细胞系显示出20.9μg/106个细胞的生产力。另外,在0.1μM的甲氨
蝶呤扩增后,与2,6-唾液酸转移酶共转导的FcεRIαECD-Fc2细胞系(FcεRIαECD-Fc2ST)显示
出25.1μg/106个细胞的生产力。即可以确认的是,在0.1μM的氨甲蝶呤扩增条件后,与2,6-
唾液酸转移酶共转染的FcεRIαECD-Fc2细胞系显示出最优异的生产力。
实施例2.FcεRIαECD融合蛋白的纯化及其纯度的鉴定
在以上实施例1中筛选的细胞系中,i)FcεRIαECD-Fc3,ii)FcεRIαECD-Fc3ST,和
iii)FcεRIαECD-Fc2ST,以60ml规模通过分批培养方法进行培养。使用Protein-A亲和柱纯
化所得的培养物,然后对纯化的蛋白进行SDS-PAGE和尺寸排阻HPLC(SE-HPLC)以鉴定蛋白
的纯度。
如图1所示,通过SE-HPLC法纯化的所有蛋白质的纯度均为93%以上。另外,SDS-
PAGE分析的结果鉴定出,在非还原条件和还原条件下分别检测到具有约150kDa和约75kDa
大小的蛋白质(图1,泳道1至6)。由此发现,结合Fc的FcεRIαECD形成二聚体。另外,在SDS-
PAGE结果中没有观察到诸如截短形式的杂质。特别地,即使在解冻/冷冻过程之后(图1,泳
道7至8),也已经确定所有蛋白质具有93%或更高的纯度,并且没有杂质。由此发现,相对于
11
CN 111587251 A 说 明 书 9/17 页
应用了野生型IgD铰链的FcεRIαECD-Fc1,截短的蛋白质形式的产生减少了。
其中,在以下测试条件下进行Gel-IEF以鉴定在引入唾液酸转移酶之后蛋白质中
唾液酸含量的程度。由此可知,由于唾液酸含量的增加,酸性蛋白质的含量有所增加。
表2
为了鉴定纯化产量的再现性,将FcεRIαECD-Fc2ST细胞系在1L烧瓶中以250mL的规
模分批培养,并使用Protein-A亲和柱纯化。随后,在Tris-甘氨酸SDS(TGS)缓冲液和200V的
条件下,将培养上清液和纯化的产物在4%至15%的TGXTM凝胶(Bio-Rad Laboratories,
Inc.)上运行30分钟,然后进行SDS PAGE分析。结果显示,不仅通过仅第一步纯化就纯化出
了纯度很高(98%以上)的蛋白质,而且即使在培养上清液中也表达了很高纯度的蛋白质。
这表明,可以将在相关细胞系中表达的FcεRIαECD-Fc蛋白开发为医疗产品,从而简化过程
开发步骤,因而医疗产品的开发成本极有可能显著下降。
实施例3.鉴定FcεRIαECD融合蛋白与IgE的结合能力
比较地检测了以下四种蛋白质对IgE的结合能力:通过上述实施例2的方法纯化的
i)FcεRIαECD-Fc2,ii)FcεRIαECD-Fc2ST,iii)FcεRIαECD-Fc3和iv)FcεRIαECD-Fc3ST,以及
市售的抗IgE抗体奥马珠单抗(omalizumab,商品名:Xolair)。具体而言,通过在蛋白GLC传
感器芯片(Bio-Rad Laboratories,Inc.,Cat#176-5011)的通道上包被IgE,并使得不同浓
度的奥马珠单抗或每种FceR1αECD-Fc蛋白以每分钟30μl的速度流动,来测量与IgE的结合
能力。
通过使用25mM NaOH作为再生缓冲液鉴定出零基线,然后重复上述步骤进行实验。
之后,使用蛋白质结合分析仪(ProteOn XPR36,Bio-Rad Laboratories,Inc.,USA)鉴定结
合曲线。结果示于表3、以及图3和4。
表3
如表3所示,测量的本发明的一个实施方案的多肽二聚体的结合速率(ka)的值比
12
CN 111587251 A 说 明 书 10/17 页
奥马珠单抗低1.5-2.0倍。即,发现与奥马珠单抗相比,其与除IgE以外的物质的结合能力低
1.5-2.0倍。另外,测量的本发明的一个实施方案的多肽二聚体的解离速率(kd)的值比奥马
珠单抗高40至106倍。另外,如图3和图4所示,在结合一定的时间后,奥马珠单抗无法与IgE
结合,而本发明的FcεRIαECD D融合蛋白的多肽二聚体结合至IgE,就不会与IgE分离。
即,可以看出本发明的多肽二聚体不易与IgE分离,并且与奥马珠单抗相比具有更
好的维持其结合状态的能力。从结果可以看出,本发明的一个实施方案的多肽二聚体的平
衡解离常数(KD
)的值比奥马珠单抗高22-69倍。由此可知,与奥马珠单抗相比,本发
明的FcεRIαECD融合蛋白与IgE的结合能力显著提高。特别地,已确定添加了唾液酸的FcεRI
αECD-Fc2(FcεRIαECD-Fc2ST)表现出最强的IgE结合能力,其比奥马珠单抗高69倍。
实施例4.鉴定FcεRIαECD融合蛋白与IgG受体的结合能力
使用Octet RED384系统(ForteBio,CA,USA)测定IgETRAP和奥马珠单抗与IgG受体
的结合程度。将FcγRI、FcγRIIA、FcγRIIB、FcγRIIIA和FcγRIIIB重组蛋白(R&D
Systems Inc.,5μg/ml)固定在活化的AR2G生物传感器上的300mM乙酸盐缓冲液(pH5)中。使
用含有0.1%Tween-20和1%牛血清的PBS作为运行缓冲液。在30℃下用速率为1,000rpm的
样品平板振荡器进行所有实验。结果如图5A至5E所示,奥马珠单抗和IgETRAP与IgG受体的结
合能力的定量检测显示在图6中。
实施例5.通过β-己糖胺酶测定法鉴定在小鼠骨髓来源的肥大细胞中的FcεRIαECD
融合蛋白的活性
进行β-己糖胺酶测定以用于本发明的FcεRIαECD融合蛋白的体外活性分析。具体
地,将本发明的一个实施方案的FcεRIαECD-Fc2蛋白在不同浓度下与小鼠IgE(1μg/mL)混
合,并在室温(20℃)下孵育30分钟以准备样品。用汉克平衡盐溶液(Hank's balanced salt
solution,HBSS)缓冲液洗涤培养物中的小鼠骨髓肥大细胞,以除去培养基,从而活化肥大
细胞,同时测量细胞数。然后调整细胞数,将5×105细胞注入40μL HBSS缓冲液中。
然后,将事先进行孵育制得的50μL样品溶液加入到活化的肥大细胞中。然后,将所
得产物在5%CO2培养箱中于37℃孵育30分钟。随后,在加入10μL DNP(2 ,4-二硝基苯酚,
100ng/mL)(一种外源抗原)后,再次在37℃的5%CO2中孵育30分钟,然后分离出30μL的上清
液。充分混合30μL分离的上清液和30μL底物(4-硝基苯基N-乙酰基-β-D-氨基葡萄糖苷,
5.84mM),然后在5%CO2中于37℃孵育20分钟。接着,加入140μL作为终止溶液的0.1M碳酸钠
缓冲液(pH 10)以终止反应。此后,测量在405nm处的吸光度,以鉴定在活化的肥大细胞中由
外源抗原分泌的α-己糖胺酶的分泌量。结果示于图7。
如图7所示,本发明的一个实施方案的多肽二聚体在浓度为小鼠IgE的一半(0.5μ
g/mL)的情况下,显示出对肥大细胞的抑制率约为49.4%,并且其浓度与小鼠IgE相同(1μg/
mL)的情况下,显示出对肥大细胞的抑制率约为99.4%。即可以看出,本发明的FceRIa-ECD
多肽二聚体极大地抑制了IgE诱导的骨髓来源的肥大细胞的活性。
实施例6.在表达人FcεRI的骨髓来源的肥大细胞中使用β-己糖胺酶测定法比较Fc
εRIαECD融合蛋白和抗人IgE抗体的活性
进行β-己糖胺酶测定,以通过体外活性分析鉴定FcεRIαECD融合蛋白相对于
Xolair的优越性。制备不同浓度的相应药物FcεRIαECD-Fc2ST(IgETRAP)和Xolair,然后与人
IgE(1μg/mL)混合。接着在室温下进行30分钟的孵育。在药物的预孵育过程中,导入人FcεRI
13
CN 111587251 A 说 明 书 11/17 页
基因,并制备从已去除FcεRI gene基因的小鼠的骨髓衍生并分化出的肥大细胞。制备的肥
大细胞用HBSS缓冲液洗涤,然后将5×105细胞注入60μL HBSS缓冲液中。将20μL预孵育的样
品添加到制备的肥大细胞中,然后在5%CO2培养箱中于37℃孵育30分钟。
随后,在加入20μL抗人IgE抗体(BioLegend,目录号325502,0.5μg/mL)后,将所得
产物再次在5%CO2培养箱中于37℃孵育30分钟。随后,在4℃以1,500rpm离心后,分离出30μ
L的上清液。将30μL分离的上清液和30μL底物(4-硝基苯基N-乙酰基-β-氨基葡萄糖,
5.84mM)充分混合,然后在5%CO2培养箱中于37℃孵育25分钟。然后,加入140μL的0.1M碳酸
钠缓冲液(pH 10)以终止反应。
接着,检测在405nm处的吸光度以比较分泌的β-己糖胺酶的相对量,并且鉴定出基
于每种药物浓度的肥大细胞的抑制作用。结果示于图8。如图8所示,测得FcεRIαECD融合蛋
白的IC50约为11.16ng/mL,Xolair蛋白的IC50约为649.8ng/mL。因此,已确定FcεRIαECD融合
蛋白对肥大细胞活性的抑制能力比Xolair高58倍。
实施例7.FcεRIαECD融合蛋白的体内测定(食物过敏模型)
以14天的间隔向Balb/c小鼠(Orientbio Inc .)腹膜内施用两次50μg卵清蛋白
(OVA)和1mg明矾以引起过敏。此后,在第28、30、32、34和36天总共口服五次共50mg OVA,以
诱发肠道食物过敏。
在口服OVA两次后,即在第31天,将小鼠分为三组,每组包含7只小鼠。三组分别为:
第一组接受高浓度(200μg)的FcεRIαECD-Fc2ST融合蛋白,第二组接受低浓度的FcεRIαECD-
Fc2ST融合蛋白(20μg),第三组未接受任何药物。口服OVA时,测定是否由于食物过敏引起了
腹泻。在第37天处死小鼠,分析每个组的小鼠中小肠肥大细胞数量、血液中IgE的浓度和血
液中肥大细胞脱粒的酶(肥大细胞蛋白酶-1(MCPT-1))浓度。
如图9可知,经证明与未接受任何药物的小鼠组相比,接受多肽二聚体FcεRIαECD-
Fc2ST的小鼠组在高浓度时显示出缓解食物过敏的效果,并且呈浓度依赖性。
序列表
SEQ ID NO:1
SEQ ID NO:2
SEQ ID NO:3
RNTGRGGEEK KGSKEKEEQE ERETKTPECP
SEQ ID NO:4
14
CN 111587251 A 说 明 书 12/17 页
AQPQAEGSLA KATTAPATTR NTGRGGEEKK GSKEKEEQEE RETKTPECP
SEQ ID NO:5
SEQ ID NO:6
SEQ ID NO:7
SEQ ID NO:8
SEQ ID NO:9
MDAMLRGLCC VLLLCGAVFV SPSHA
15
CN 111587251 A 说 明 书 13/17 页
SEQ ID NO:10
SEQ ID NO:11
SEQ ID NO:12
16
CN 111587251 A 说 明 书 14/17 页
SEQ ID NO:13
SEQ ID NO:14
17
CN 111587251 A 说 明 书 15/17 页
SEQ ID NO:15
18
CN 111587251 A 说 明 书 16/17 页
SEQ ID NO:16
SEQ ID NO:17
RNTGRGGEEK KXXKEKEEQE ERETKTPECP
SEQ ID NO:18
AQPQAEGSLA KATTAPATTR NTGRGGEEKK XXKEKEEQEE RETKTPECP
19
CN 111587251 A 说 明 书 17/17 页
SEQ ID NO:19
RNTGRGGEEK KKEKEKEEQE ERETKTPECP
SEQ ID NO:20
SEQ ID NO:21
SEQ ID NO:22
20
CN 111587251 A 序 列 表 1/18 页
SEQUENCE LISTING
<110> GI 医诺微新
<120> IgE FC受体的α亚基的胞外域、包含其的药物组合物及其制备方法
<130> P20113066WP
<150> KR 10-2018-0002248
<151> 2018-01-08
<160> 22
<170> PatentIn version 3.5
<210> 1
<211> 180
<212> PRT
<213> Artificial Sequence
<220>
<223> FCeRI1 ECD
<400> 1
Val Pro Gln Lys Pro Lys Val Ser Leu Asn Pro Pro Trp Asn Arg Ile
1 5 10 15
Phe Lys Gly Glu Asn Val Thr Leu Thr Cys Asn Gly Asn Asn Phe Phe
20 25 30
Glu Val Ser Ser Thr Lys Trp Phe His Asn Gly Ser Leu Ser Glu Glu
35 40 45
Thr Asn Ser Ser Leu Asn Ile Val Asn Ala Lys Phe Glu Asp Ser Gly
50 55 60
Glu Tyr Lys Cys Gln His Gln Gln Val Asn Glu Ser Glu Pro Val Tyr
65 70 75 80
Leu Glu Val Phe Ser Asp Trp Leu Leu Leu Gln Ala Ser Ala Glu Val
85 90 95
Val Met Glu Gly Gln Pro Leu Phe Leu Arg Cys His Gly Trp Arg Asn
100 105 110
Trp Asp Val Tyr Lys Val Ile Tyr Tyr Lys Asp Gly Glu Ala Leu Lys
115 120 125
Tyr Trp Tyr Glu Asn His Asn Ile Ser Ile Thr Asn Ala Thr Val Glu
130 135 140
Asp Ser Gly Thr Tyr Tyr Cys Thr Gly Lys Val Trp Gln Leu Asp Tyr
145 150 155 160
Glu Ser Glu Pro Leu Asn Ile Thr Val Ile Lys Ala Pro Arg Glu Lys
165 170 175
Tyr Trp Leu Gln
21
CN 111587251 A 序 列 表 2/18 页
180
<210> 2
<211> 215
<212> PRT
<213> Artificial Sequence
<220>
<223> 经修饰的Fc
<400> 2
Ser His Thr Gln Pro Leu Gly Val Phe Leu Phe Pro Pro Lys Pro Lys
1 5 10 15
Asp Thr Leu Met Ile Ser Arg Thr Pro Glu Val Thr Cys Val Val Val
20 25 30
Asp Val Ser Gln Glu Asp Pro Glu Val Gln Phe Asn Trp Tyr Val Asp
35 40 45
Gly Val Glu Val His Asn Ala Lys Thr Lys Pro Arg Glu Glu Gln Phe
50 55 60
Asn Ser Thr Tyr Arg Val Val Ser Val Leu Thr Val Leu His Gln Asp
65 70 75 80
Trp Leu Asn Gly Lys Glu Tyr Lys Cys Lys Val Ser Asn Lys Gly Leu
85 90 95
Pro Ser Ser Ile Glu Lys Thr Ile Ser Lys Ala Lys Gly Gln Pro Arg
100 105 110
Glu Pro Gln Val Tyr Thr Leu Pro Pro Ser Gln Glu Glu Met Thr Lys
115 120 125
Asn Gln Val Ser Leu Thr Cys Leu Val Lys Gly Phe Tyr Pro Ser Asp
130 135 140
Ile Ala Val Glu Trp Glu Ser Asn Gly Gln Pro Glu Asn Asn Tyr Lys
145 150 155 160
Thr Thr Pro Pro Val Leu Asp Ser Asp Gly Ser Phe Phe Leu Tyr Ser
165 170 175
Arg Leu Thr Val Asp Lys Ser Arg Trp Gln Glu Gly Asn Val Phe Ser
180 185 190
Cys Ser Val Met His Glu Ala Leu His Asn His Tyr Thr Gln Lys Ser
195 200 205
Leu Ser Leu Ser Leu Gly Lys
210 215
<210> 3
<211> 30
<212> PRT
22
CN 111587251 A 序 列 表 3/18 页
<213> Artificial Sequence
<220>
<223> IgD铰链变体
<400> 3
Arg Asn Thr Gly Arg Gly Gly Glu Glu Lys Lys Gly Ser Lys Glu Lys
1 5 10 15
Glu Glu Gln Glu Glu Arg Glu Thr Lys Thr Pro Glu Cys Pro
20 25 30
<210> 4
<211> 49
<212> PRT
<213> Artificial Sequence
<220>
<223> IgD铰链变体
<400> 4
Ala Gln Pro Gln Ala Glu Gly Ser Leu Ala Lys Ala Thr Thr Ala Pro
1 5 10 15
Ala Thr Thr Arg Asn Thr Gly Arg Gly Gly Glu Glu Lys Lys Gly Ser
20 25 30
Lys Glu Lys Glu Glu Gln Glu Glu Arg Glu Thr Lys Thr Pro Glu Cys
35 40 45
Pro
<210> 5
<211> 540
<212> DNA
<213> Artificial Sequence
<220>
<223> FCeRI1 ECD的核苷酸序列
<400> 5
gtgccccaga agcccaaggt gagcctgaac cctccctgga acagaatctt caagggcgag 60
aacgtgaccc tgacctgcaa cggcaacaac ttcttcgagg tgagcagcac caagtggttc 120
cacaatggca gcctgagcga ggagaccaac agctccctga acatcgtgaa cgccaagttc 180
gaggacagcg gcgagtacaa gtgccagcac cagcaggtga acgagagcga gcccgtgtac 240
ctggaggtgt tcagcgactg gctgctgctg caggccagcg ccgaggtggt gatggagggc 300
cagcccctgt tcctgagatg ccacggctgg agaaactggg acgtgtacaa ggtgatctac 360
tacaaggatg gcgaggccct gaagtactgg tacgagaacc acaacatctc catcaccaac 420
gccaccgtgg aggacagcgg cacctactac tgcacaggca aggtgtggca gctggactac 480
gagagcgagc ccctgaacat caccgtgatc aaggctccca gagagaagta ctggctgcag 540
<210> 6
23
CN 111587251 A 序 列 表 4/18 页
<211> 561
<212> DNA
<213> Artificial Sequence
<220>
<223> 经修饰的Fc的核苷酸序列
<400> 6
tgcgtggtcg tggatgtgag ccaggaagat cccgaagtgc agttcaactg gtacgtggat 60
ggcgtggaag tgcacaacgc caagaccaag cccagagaag agcagttcaa ctccacctac 120
agagtggtga gcgtgctgac cgtgctgcac caggactggc tgaacggcaa ggagtacaag 180
tgcaaggtgt ccaacaaagg cctgcccagc tccatcgaga agaccatcag caaagccaaa 240
ggccagccca gagaacccca ggtgtacacc ctgcctccca gccaggaaga gatgaccaag 300
aaccaggtgt ccctgacctg cctggtgaaa ggcttctacc ccagcgacat cgccgtggag 360
tgggaaagca acggccagcc cgagaacaat tacaagacaa cccctcccgt gctggatagc 420
gatggcagct tctttctgta cagcagactg accgtggaca agagcagatg gcaggaaggc 480
aacgtgttca gctgcagcgt gatgcacgaa gccctgcaca accactacac ccagaagagc 540
ctgtccctga gcctgggcaa g 561
<210> 7
<211> 174
<212> DNA
<213> Artificial Sequence
<220>
<223> IgD铰链变体的核苷酸序列
<400> 7
aggaacaccg gcagaggagg cgaggaaaag aaaggaagca aggagaagga ggagcaggag 60
gaaagagaaa ccaagacccc cgagtgcccc agccacaccc agcccctggg cgtgttcctg 120
ttccccccca agcccaagga caccctgatg atcagcagaa cccccgaggt gacc 174
<210> 8
<211> 231
<212> DNA
<213> Artificial Sequence
<220>
<223> IgD铰链变体的核苷酸序列
<400> 8
gcccagcccc aggccgaggg cagcctggct aaggccacca cagctcccgc caccaccagg 60
aacaccggca gaggaggcga ggaaaagaaa ggaagcaagg agaaggagga gcaggaggaa 120
agagaaacca agacccccga gtgccccagc cacacccagc ccctgggcgt gttcctgttc 180
ccccccaagc ccaaggacac cctgatgatc agcagaaccc ccgaggtgac c 231
<210> 9
<211> 25
24
CN 111587251 A 序 列 表 5/18 页
<212> PRT
<213> Artificial Sequence
<220>
<223> 信号肽
<400> 9
Met Asp Ala Met Leu Arg Gly Leu Cys Cys Val Leu Leu Leu Cys Gly
1 5 10 15
Ala Val Phe Val Ser Pro Ser His Ala
20 25
<210> 10
<211> 75
<212> DNA
<213> Artificial Sequence
<220>
<223> 信号肽核苷酸
<400> 10
atggacgcca tgctgagagg cctgtgctgt gtgctgctgc tgtgcggcgc cgtgttcgtg 60
tcccctagcc acgcc 75
<210> 11
<211> 450
<212> PRT
<213> Artificial Sequence
<220>
<223> FceRIa ECD-铰链-Fc2
<400> 11
Met Asp Ala Met Leu Arg Gly Leu Cys Cys Val Leu Leu Leu Cys Gly
1 5 10 15
Ala Val Phe Val Ser Pro Ser His Ala Val Pro Gln Lys Pro Lys Val
20 25 30
Ser Leu Asn Pro Pro Trp Asn Arg Ile Phe Lys Gly Glu Asn Val Thr
35 40 45
Leu Thr Cys Asn Gly Asn Asn Phe Phe Glu Val Ser Ser Thr Lys Trp
50 55 60
Phe His Asn Gly Ser Leu Ser Glu Glu Thr Asn Ser Ser Leu Asn Ile
65 70 75 80
Val Asn Ala Lys Phe Glu Asp Ser Gly Glu Tyr Lys Cys Gln His Gln
85 90 95
Gln Val Asn Glu Ser Glu Pro Val Tyr Leu Glu Val Phe Ser Asp Trp
100 105 110
25
CN 111587251 A 序 列 表 6/18 页
Leu Leu Leu Gln Ala Ser Ala Glu Val Val Met Glu Gly Gln Pro Leu
115 120 125
Phe Leu Arg Cys His Gly Trp Arg Asn Trp Asp Val Tyr Lys Val Ile
130 135 140
Tyr Tyr Lys Asp Gly Glu Ala Leu Lys Tyr Trp Tyr Glu Asn His Asn
145 150 155 160
Ile Ser Ile Thr Asn Ala Thr Val Glu Asp Ser Gly Thr Tyr Tyr Cys
165 170 175
Thr Gly Lys Val Trp Gln Leu Asp Tyr Glu Ser Glu Pro Leu Asn Ile
180 185 190
Thr Val Ile Lys Ala Pro Arg Glu Lys Tyr Trp Leu Gln Arg Asn Thr
195 200 205
Gly Arg Gly Gly Glu Glu Lys Lys Gly Ser Lys Glu Lys Glu Glu Gln
210 215 220
Glu Glu Arg Glu Thr Lys Thr Pro Glu Cys Pro Ser His Thr Gln Pro
225 230 235 240
Leu Gly Val Phe Leu Phe Pro Pro Lys Pro Lys Asp Thr Leu Met Ile
245 250 255
Ser Arg Thr Pro Glu Val Thr Cys Val Val Val Asp Val Ser Gln Glu
260 265 270
Asp Pro Glu Val Gln Phe Asn Trp Tyr Val Asp Gly Val Glu Val His
275 280 285
Asn Ala Lys Thr Lys Pro Arg Glu Glu Gln Phe Asn Ser Thr Tyr Arg
290 295 300
Val Val Ser Val Leu Thr Val Leu His Gln Asp Trp Leu Asn Gly Lys
305 310 315 320
Glu Tyr Lys Cys Lys Val Ser Asn Lys Gly Leu Pro Ser Ser Ile Glu
325 330 335
Lys Thr Ile Ser Lys Ala Lys Gly Gln Pro Arg Glu Pro Gln Val Tyr
340 345 350
Thr Leu Pro Pro Ser Gln Glu Glu Met Thr Lys Asn Gln Val Ser Leu
355 360 365
Thr Cys Leu Val Lys Gly Phe Tyr Pro Ser Asp Ile Ala Val Glu Trp
370 375 380
Glu Ser Asn Gly Gln Pro Glu Asn Asn Tyr Lys Thr Thr Pro Pro Val
385 390 395 400
Leu Asp Ser Asp Gly Ser Phe Phe Leu Tyr Ser Arg Leu Thr Val Asp
405 410 415
Lys Ser Arg Trp Gln Glu Gly Asn Val Phe Ser Cys Ser Val Met His
26
CN 111587251 A 序 列 表 7/18 页
420 425 430
Glu Ala Leu His Asn His Tyr Thr Gln Lys Ser Leu Ser Leu Ser Leu
435 440 445
Gly Lys
450
<210> 12
<211> 1350
<212> DNA
<213> Artificial Sequence
<220>
<223> FceRIa ECD-铰链-Fc2的核苷酸序列
<400> 12
atggacgcca tgctgagagg cctgtgctgt gtgctgctgc tgtgcggcgc cgtgttcgtg 60
tcccctagcc acgccgtgcc ccagaagccc aaggtgagcc tgaaccctcc ctggaacaga 120
atcttcaagg gcgagaacgt gaccctgacc tgcaacggca acaacttctt cgaggtgagc 180
agcaccaagt ggttccacaa tggcagcctg agcgaggaga ccaacagctc cctgaacatc 240
gtgaacgcca agttcgagga cagcggcgag tacaagtgcc agcaccagca ggtgaacgag 300
agcgagcccg tgtacctgga ggtgttcagc gactggctgc tgctgcaggc cagcgccgag 360
gtggtgatgg agggccagcc cctgttcctg agatgccacg gctggagaaa ctgggacgtg 420
tacaaggtga tctactacaa ggatggcgag gccctgaagt actggtacga gaaccacaac 480
atctccatca ccaacgccac cgtggaggac agcggcacct actactgcac aggcaaggtg 540
tggcagctgg actacgagag cgagcccctg aacatcaccg tgatcaaggc tcccagagag 600
aagtactggc tgcagaggaa caccggcaga ggaggcgagg aaaagaaagg aagcaaggag 660
aaggaggagc aggaggaaag agaaaccaag acccccgagt gccccagcca cacccagccc 720
ctgggcgtgt tcctgttccc ccccaagccc aaggacaccc tgatgatcag cagaaccccc 780
gaggtgacct gcgtggtcgt ggatgtgagc caggaagatc ccgaagtgca gttcaactgg 840
tacgtggatg gcgtggaagt gcacaacgcc aagaccaagc ccagagaaga gcagttcaac 900
tccacctaca gagtggtgag cgtgctgacc gtgctgcacc aggactggct gaacggcaag 960
gagtacaagt gcaaggtgtc caacaaaggc ctgcccagct ccatcgagaa gaccatcagc 1020
aaagccaaag gccagcccag agaaccccag gtgtacaccc tgcctcccag ccaggaagag 1080
atgaccaaga accaggtgtc cctgacctgc ctggtgaaag gcttctaccc cagcgacatc 1140
gccgtggagt gggaaagcaa cggccagccc gagaacaatt acaagacaac ccctcccgtg 1200
ctggatagcg atggcagctt ctttctgtac agcagactga ccgtggacaa gagcagatgg 1260
caggaaggca acgtgttcag ctgcagcgtg atgcacgaag ccctgcacaa ccactacacc 1320
cagaagagcc tgtccctgag cctgggcaag 1350
<210> 13
<211> 469
<212> PRT
<213> Artificial Sequence
27
CN 111587251 A 序 列 表 8/18 页
<220>
<223> FceRIa ECD-铰链-Fc3
<400> 13
Met Asp Ala Met Leu Arg Gly Leu Cys Cys Val Leu Leu Leu Cys Gly
1 5 10 15
Ala Val Phe Val Ser Pro Ser His Ala Val Pro Gln Lys Pro Lys Val
20 25 30
Ser Leu Asn Pro Pro Trp Asn Arg Ile Phe Lys Gly Glu Asn Val Thr
35 40 45
Leu Thr Cys Asn Gly Asn Asn Phe Phe Glu Val Ser Ser Thr Lys Trp
50 55 60
Phe His Asn Gly Ser Leu Ser Glu Glu Thr Asn Ser Ser Leu Asn Ile
65 70 75 80
Val Asn Ala Lys Phe Glu Asp Ser Gly Glu Tyr Lys Cys Gln His Gln
85 90 95
Gln Val Asn Glu Ser Glu Pro Val Tyr Leu Glu Val Phe Ser Asp Trp
100 105 110
Leu Leu Leu Gln Ala Ser Ala Glu Val Val Met Glu Gly Gln Pro Leu
115 120 125
Phe Leu Arg Cys His Gly Trp Arg Asn Trp Asp Val Tyr Lys Val Ile
130 135 140
Tyr Tyr Lys Asp Gly Glu Ala Leu Lys Tyr Trp Tyr Glu Asn His Asn
145 150 155 160
Ile Ser Ile Thr Asn Ala Thr Val Glu Asp Ser Gly Thr Tyr Tyr Cys
165 170 175
Thr Gly Lys Val Trp Gln Leu Asp Tyr Glu Ser Glu Pro Leu Asn Ile
180 185 190
Thr Val Ile Lys Ala Pro Arg Glu Lys Tyr Trp Leu Gln Ala Gln Pro
195 200 205
Gln Ala Glu Gly Ser Leu Ala Lys Ala Thr Thr Ala Pro Ala Thr Thr
210 215 220
Arg Asn Thr Gly Arg Gly Gly Glu Glu Lys Lys Gly Ser Lys Glu Lys
225 230 235 240
Glu Glu Gln Glu Glu Arg Glu Thr Lys Thr Pro Glu Cys Pro Ser His
245 250 255
Thr Gln Pro Leu Gly Val Phe Leu Phe Pro Pro Lys Pro Lys Asp Thr
260 265 270
Leu Met Ile Ser Arg Thr Pro Glu Val Thr Cys Val Val Val Asp Val
275 280 285
28
CN 111587251 A 序 列 表 9/18 页
Ser Gln Glu Asp Pro Glu Val Gln Phe Asn Trp Tyr Val Asp Gly Val
290 295 300
Glu Val His Asn Ala Lys Thr Lys Pro Arg Glu Glu Gln Phe Asn Ser
305 310 315 320
Thr Tyr Arg Val Val Ser Val Leu Thr Val Leu His Gln Asp Trp Leu
325 330 335
Asn Gly Lys Glu Tyr Lys Cys Lys Val Ser Asn Lys Gly Leu Pro Ser
340 345 350
Ser Ile Glu Lys Thr Ile Ser Lys Ala Lys Gly Gln Pro Arg Glu Pro
355 360 365
Gln Val Tyr Thr Leu Pro Pro Ser Gln Glu Glu Met Thr Lys Asn Gln
370 375 380
Val Ser Leu Thr Cys Leu Val Lys Gly Phe Tyr Pro Ser Asp Ile Ala
385 390 395 400
Val Glu Trp Glu Ser Asn Gly Gln Pro Glu Asn Asn Tyr Lys Thr Thr
405 410 415
Pro Pro Val Leu Asp Ser Asp Gly Ser Phe Phe Leu Tyr Ser Arg Leu
420 425 430
Thr Val Asp Lys Ser Arg Trp Gln Glu Gly Asn Val Phe Ser Cys Ser
435 440 445
Val Met His Glu Ala Leu His Asn His Tyr Thr Gln Lys Ser Leu Ser
450 455 460
Leu Ser Leu Gly Lys
465
<210> 14
<211> 1407
<212> DNA
<213> Artificial Sequence
<220>
<223> FceRIa ECD-铰链-Fc3的核苷酸序列
<400> 14
atggacgcca tgctgagagg cctgtgctgt gtgctgctgc tgtgcggcgc cgtgttcgtg 60
tcccctagcc acgccgtgcc ccagaagccc aaggtgagcc tgaaccctcc ctggaacaga 120
atcttcaagg gcgagaacgt gaccctgacc tgcaacggca acaacttctt cgaggtgagc 180
agcaccaagt ggttccacaa tggcagcctg agcgaggaga ccaacagctc cctgaacatc 240
gtgaacgcca agttcgagga cagcggcgag tacaagtgcc agcaccagca ggtgaacgag 300
agcgagcccg tgtacctgga ggtgttcagc gactggctgc tgctgcaggc cagcgccgag 360
gtggtgatgg agggccagcc cctgttcctg agatgccacg gctggagaaa ctgggacgtg 420
tacaaggtga tctactacaa ggatggcgag gccctgaagt actggtacga gaaccacaac 480
29
CN 111587251 A 序 列 表 10/18 页
atctccatca ccaacgccac cgtggaggac agcggcacct actactgcac aggcaaggtg 540
tggcagctgg actacgagag cgagcccctg aacatcaccg tgatcaaggc tcccagagag 600
aagtactggc tgcaggccca gccccaggcc gagggcagcc tggctaaggc caccacagct 660
cccgccacca ccaggaacac cggcagagga ggcgaggaaa agaaaggaag caaggagaag 720
gaggagcagg aggaaagaga aaccaagacc cccgagtgcc ccagccacac ccagcccctg 780
ggcgtgttcc tgttcccccc caagcccaag gacaccctga tgatcagcag aacccccgag 840
gtgacctgcg tggtcgtgga tgtgagccag gaagatcccg aagtgcagtt caactggtac 900
gtggatggcg tggaagtgca caacgccaag accaagccca gagaagagca gttcaactcc 960
acctacagag tggtgagcgt gctgaccgtg ctgcaccagg actggctgaa cggcaaggag 1020
tacaagtgca aggtgtccaa caaaggcctg cccagctcca tcgagaagac catcagcaaa 1080
gccaaaggcc agcccagaga accccaggtg tacaccctgc ctcccagcca ggaagagatg 1140
accaagaacc aggtgtccct gacctgcctg gtgaaaggct tctaccccag cgacatcgcc 1200
gtggagtggg aaagcaacgg ccagcccgag aacaattaca agacaacccc tcccgtgctg 1260
gatagcgatg gcagcttctt tctgtacagc agactgaccg tggacaagag cagatggcag 1320
gaaggcaacg tgttcagctg cagcgtgatg cacgaagccc tgcacaacca ctacacccag 1380
aagagcctgt ccctgagcct gggcaag 1407
<210> 15
<211> 406
<212> PRT
<213> Artificial Sequence
<220>
<223> 人a-2,6-唾液酸转移酶
<400> 15
Met Ile His Thr Asn Leu Lys Lys Lys Phe Ser Cys Cys Val Leu Val
1 5 10 15
Phe Leu Leu Phe Ala Val Ile Cys Val Trp Lys Glu Lys Lys Lys Gly
20 25 30
Ser Tyr Tyr Asp Ser Phe Lys Leu Gln Thr Lys Glu Phe Gln Val Leu
35 40 45
Lys Ser Leu Gly Lys Leu Ala Met Gly Ser Asp Ser Gln Ser Val Ser
50 55 60
Ser Ser Ser Thr Gln Asp Pro His Arg Gly Arg Gln Thr Leu Gly Ser
65 70 75 80
Leu Arg Gly Leu Ala Lys Ala Lys Pro Glu Ala Ser Phe Gln Val Trp
85 90 95
Asn Lys Asp Ser Ser Ser Lys Asn Leu Ile Pro Arg Leu Gln Lys Ile
100 105 110
Trp Lys Asn Tyr Leu Ser Met Asn Lys Tyr Lys Val Ser Tyr Lys Gly
115 120 125
30
CN 111587251 A 序 列 表 11/18 页
Pro Gly Pro Gly Ile Lys Phe Ser Ala Glu Ala Leu Arg Cys His Leu
130 135 140
Arg Asp His Val Asn Val Ser Met Val Glu Val Thr Asp Phe Pro Phe
145 150 155 160
Asn Thr Ser Glu Trp Glu Gly Tyr Leu Pro Lys Glu Ser Ile Arg Thr
165 170 175
Lys Ala Gly Pro Trp Gly Arg Cys Ala Val Val Ser Ser Ala Gly Ser
180 185 190
Leu Lys Ser Ser Gln Leu Gly Arg Glu Ile Asp Asp His Asp Ala Val
195 200 205
Leu Arg Phe Asn Gly Ala Pro Thr Ala Asn Phe Gln Gln Asp Val Gly
210 215 220
Thr Lys Thr Thr Ile Arg Leu Met Asn Ser Gln Leu Val Thr Thr Glu
225 230 235 240
Lys Arg Phe Leu Lys Asp Ser Leu Tyr Asn Glu Gly Ile Leu Ile Val
245 250 255
Trp Asp Pro Ser Val Tyr His Ser Asp Ile Pro Lys Trp Tyr Gln Asn
260 265 270
Pro Asp Tyr Asn Phe Phe Asn Asn Tyr Lys Thr Tyr Arg Lys Leu His
275 280 285
Pro Asn Gln Pro Phe Tyr Ile Leu Lys Pro Gln Met Pro Trp Glu Leu
290 295 300
Trp Asp Ile Leu Gln Glu Ile Ser Pro Glu Glu Ile Gln Pro Asn Pro
305 310 315 320
Pro Ser Ser Gly Met Leu Gly Ile Ile Ile Met Met Thr Leu Cys Asp
325 330 335
Gln Val Asp Ile Tyr Glu Phe Leu Pro Ser Lys Arg Lys Thr Asp Val
340 345 350
Cys Tyr Tyr Tyr Gln Lys Phe Phe Asp Ser Ala Cys Thr Met Gly Ala
355 360 365
Tyr His Pro Leu Leu Tyr Glu Lys Asn Leu Val Lys His Leu Asn Gln
370 375 380
Gly Thr Asp Glu Asp Ile Tyr Leu Leu Gly Lys Ala Thr Leu Pro Gly
385 390 395 400
Phe Arg Thr Ile His Cys
405
<210> 16
<211> 1218
<212> DNA
31
CN 111587251 A 序 列 表 12/18 页
<213> Artificial Sequence
<220>
<223> 人a-2,6-唾液酸转移酶的核苷酸序列
<400> 16
atgatccaca ccaacctgaa gaagaagttc agctgctgcg tgctggtgtt cctgctgttc 60
gccgtgatct gcgtgtggaa ggagaagaag aaaggcagct actacgacag cttcaagctg 120
cagaccaagg agttccaggt gctgaagagc ctgggcaagc tggccatggg cagcgacagc 180
cagagcgtgt ccagctcctc cacccaggat ccccacagag gcagacagac cctgggcagc 240
ctgagaggcc tggccaaggc caagcccgag gccagcttcc aggtgtggaa caaggacagc 300
agcagcaaga acctgatccc cagactgcag aagatctgga agaactacct gagcatgaac 360
aagtacaagg tgagctacaa aggacccgga cccggcatca agttcagcgc cgaggccctg 420
aggtgccacc tgagagacca cgtgaacgtg agcatggtgg aagtgaccga cttccccttc 480
aacaccagcg agtgggaagg ctacctgccc aaggagagca tcaggaccaa ggctggcccc 540
tggggcagat gcgccgtggt gagcagcgct ggcagcctga agagctccca gctgggcaga 600
gagatcgacg accacgatgc cgtgctgagg ttcaatggcg ctcccaccgc caacttccag 660
caggacgtgg gcaccaagac cacaatccgg ctgatgaaca gccagctggt gacaaccgag 720
aagcggttcc tgaaggacag cctgtacaac gagggcatcc tgatcgtgtg ggatcccagc 780
gtgtaccaca gcgacatccc caagtggtac cagaatcccg actacaactt cttcaacaac 840
tacaagacct atagaaagct gcaccccaac cagcccttct acatcctgaa gccccagatg 900
ccctgggagc tgtgggacat cctgcaggag atcagccctg aagagatcca gcccaaccct 960
ccctccagcg gcatgctggg cattatcatc atgatgaccc tgtgcgacca ggtggacatc 1020
tacgagttcc tgcccagcaa gagaaagacc gacgtgtgct actactatca gaagttcttc 1080
gacagcgcct gcaccatggg cgcctaccac cccctgctgt acgagaagaa cctggtgaag 1140
cacctgaacc agggcaccga cgaggacatc tacctgctgg gcaaagccac cctgcccggc 1200
ttcagaacca tccactgc 1218
<210> 17
<211> 30
<212> PRT
<213> Artificial Sequence
<220>
<223> IgD铰链变体
<220>
<221> misc_feature
<222> (12)
<223> Xaa is Lys or Gly
<220>
<221> misc_feature
<222> (13)
<223> Xaa is Glu, Gly or Ser
32
CN 111587251 A 序 列 表 13/18 页
<400> 17
Arg Asn Thr Gly Arg Gly Gly Glu Glu Lys Lys Xaa Xaa Lys Glu Lys
1 5 10 15
Glu Glu Gln Glu Glu Arg Glu Thr Lys Thr Pro Glu Cys Pro
20 25 30
<210> 18
<211> 49
<212> PRT
<213> Artificial Sequence
<220>
<223> IgD铰链变体
<220>
<221> misc_feature
<222> (31)
<223> Xaa is Lys or Gly
<220>
<221> misc_feature
<222> (32)
<223> Xaa is Glu, Gly or Ser
<400> 18
Ala Gln Pro Gln Ala Glu Gly Ser Leu Ala Lys Ala Thr Thr Ala Pro
1 5 10 15
Ala Thr Thr Arg Asn Thr Gly Arg Gly Gly Glu Glu Lys Lys Xaa Xaa
20 25 30
Lys Glu Lys Glu Glu Gln Glu Glu Arg Glu Thr Lys Thr Pro Glu Cys
35 40 45
Pro
<210> 19
<211> 30
<212> PRT
<213> Artificial Sequence
<220>
<223> IgD铰链
<400> 19
Arg Asn Thr Gly Arg Gly Gly Glu Glu Lys Lys Lys Glu Lys Glu Lys
1 5 10 15
Glu Glu Gln Glu Glu Arg Glu Thr Lys Thr Pro Glu Cys Pro
20 25 30
<210> 20
33
CN 111587251 A 序 列 表 14/18 页
<211> 425
<212> PRT
<213> Artificial Sequence
<220>
<223> FceRIa ECD-铰链-Fc1
<400> 20
Val Pro Gln Lys Pro Lys Val Ser Leu Asn Pro Pro Trp Asn Arg Ile
1 5 10 15
Phe Lys Gly Glu Asn Val Thr Leu Thr Cys Asn Gly Asn Asn Phe Phe
20 25 30
Glu Val Ser Ser Thr Lys Trp Phe His Asn Gly Ser Leu Ser Glu Glu
35 40 45
Thr Asn Ser Ser Leu Asn Ile Val Asn Ala Lys Phe Glu Asp Ser Gly
50 55 60
Glu Tyr Lys Cys Gln His Gln Gln Val Asn Glu Ser Glu Pro Val Tyr
65 70 75 80
Leu Glu Val Phe Ser Asp Trp Leu Leu Leu Gln Ala Ser Ala Glu Val
85 90 95
Val Met Glu Gly Gln Pro Leu Phe Leu Arg Cys His Gly Trp Arg Asn
100 105 110
Trp Asp Val Tyr Lys Val Ile Tyr Tyr Lys Asp Gly Glu Ala Leu Lys
115 120 125
Tyr Trp Tyr Glu Asn His Asn Ile Ser Ile Thr Asn Ala Thr Val Glu
130 135 140
Asp Ser Gly Thr Tyr Tyr Cys Thr Gly Lys Val Trp Gln Leu Asp Tyr
145 150 155 160
Glu Ser Glu Pro Leu Asn Ile Thr Val Ile Lys Ala Pro Arg Glu Lys
165 170 175
Tyr Trp Leu Gln Arg Asn Thr Gly Arg Gly Gly Glu Glu Lys Lys Lys
180 185 190
Glu Lys Glu Lys Glu Glu Gln Glu Glu Arg Glu Thr Lys Thr Pro Glu
195 200 205
Cys Pro Ser His Thr Gln Pro Leu Gly Val Phe Leu Phe Pro Pro Lys
210 215 220
Pro Lys Asp Thr Leu Met Ile Ser Arg Thr Pro Glu Val Thr Cys Val
225 230 235 240
Val Val Asp Val Ser Gln Glu Asp Pro Glu Val Gln Phe Asn Trp Tyr
245 250 255
Val Asp Gly Val Glu Val His Asn Ala Lys Thr Lys Pro Arg Glu Glu
34
CN 111587251 A 序 列 表 15/18 页
260 265 270
Gln Phe Asn Ser Thr Tyr Arg Val Val Ser Val Leu Thr Val Leu His
275 280 285
Gln Asp Trp Leu Asn Gly Lys Glu Tyr Lys Cys Lys Val Ser Asn Lys
290 295 300
Gly Leu Pro Ser Ser Ile Glu Lys Thr Ile Ser Lys Ala Lys Gly Gln
305 310 315 320
Pro Arg Glu Pro Gln Val Tyr Thr Leu Pro Pro Ser Gln Glu Glu Met
325 330 335
Thr Lys Asn Gln Val Ser Leu Thr Cys Leu Val Lys Gly Phe Tyr Pro
340 345 350
Ser Asp Ile Ala Val Glu Trp Glu Ser Asn Gly Gln Pro Glu Asn Asn
355 360 365
Tyr Lys Thr Thr Pro Pro Val Leu Asp Ser Asp Gly Ser Phe Phe Leu
370 375 380
Tyr Ser Arg Leu Thr Val Asp Lys Ser Arg Trp Gln Glu Gly Asn Val
385 390 395 400
Phe Ser Cys Ser Val Met His Glu Ala Leu His Asn His Tyr Thr Gln
405 410 415
Lys Ser Leu Ser Leu Ser Leu Gly Lys
420 425
<210> 21
<211> 425
<212> PRT
<213> Artificial Sequence
<220>
<223> FceRIa ECD-铰链-Fc2
<400> 21
Val Pro Gln Lys Pro Lys Val Ser Leu Asn Pro Pro Trp Asn Arg Ile
1 5 10 15
Phe Lys Gly Glu Asn Val Thr Leu Thr Cys Asn Gly Asn Asn Phe Phe
20 25 30
Glu Val Ser Ser Thr Lys Trp Phe His Asn Gly Ser Leu Ser Glu Glu
35 40 45
Thr Asn Ser Ser Leu Asn Ile Val Asn Ala Lys Phe Glu Asp Ser Gly
50 55 60
Glu Tyr Lys Cys Gln His Gln Gln Val Asn Glu Ser Glu Pro Val Tyr
65 70 75 80
Leu Glu Val Phe Ser Asp Trp Leu Leu Leu Gln Ala Ser Ala Glu Val
35
CN 111587251 A 序 列 表 16/18 页
85 90 95
Val Met Glu Gly Gln Pro Leu Phe Leu Arg Cys His Gly Trp Arg Asn
100 105 110
Trp Asp Val Tyr Lys Val Ile Tyr Tyr Lys Asp Gly Glu Ala Leu Lys
115 120 125
Tyr Trp Tyr Glu Asn His Asn Ile Ser Ile Thr Asn Ala Thr Val Glu
130 135 140
Asp Ser Gly Thr Tyr Tyr Cys Thr Gly Lys Val Trp Gln Leu Asp Tyr
145 150 155 160
Glu Ser Glu Pro Leu Asn Ile Thr Val Ile Lys Ala Pro Arg Glu Lys
165 170 175
Tyr Trp Leu Gln Arg Asn Thr Gly Arg Gly Gly Glu Glu Lys Lys Gly
180 185 190
Ser Lys Glu Lys Glu Glu Gln Glu Glu Arg Glu Thr Lys Thr Pro Glu
195 200 205
Cys Pro Ser His Thr Gln Pro Leu Gly Val Phe Leu Phe Pro Pro Lys
210 215 220
Pro Lys Asp Thr Leu Met Ile Ser Arg Thr Pro Glu Val Thr Cys Val
225 230 235 240
Val Val Asp Val Ser Gln Glu Asp Pro Glu Val Gln Phe Asn Trp Tyr
245 250 255
Val Asp Gly Val Glu Val His Asn Ala Lys Thr Lys Pro Arg Glu Glu
260 265 270
Gln Phe Asn Ser Thr Tyr Arg Val Val Ser Val Leu Thr Val Leu His
275 280 285
Gln Asp Trp Leu Asn Gly Lys Glu Tyr Lys Cys Lys Val Ser Asn Lys
290 295 300
Gly Leu Pro Ser Ser Ile Glu Lys Thr Ile Ser Lys Ala Lys Gly Gln
305 310 315 320
Pro Arg Glu Pro Gln Val Tyr Thr Leu Pro Pro Ser Gln Glu Glu Met
325 330 335
Thr Lys Asn Gln Val Ser Leu Thr Cys Leu Val Lys Gly Phe Tyr Pro
340 345 350
Ser Asp Ile Ala Val Glu Trp Glu Ser Asn Gly Gln Pro Glu Asn Asn
355 360 365
Tyr Lys Thr Thr Pro Pro Val Leu Asp Ser Asp Gly Ser Phe Phe Leu
370 375 380
Tyr Ser Arg Leu Thr Val Asp Lys Ser Arg Trp Gln Glu Gly Asn Val
385 390 395 400
36
CN 111587251 A 序 列 表 17/18 页
Phe Ser Cys Ser Val Met His Glu Ala Leu His Asn His Tyr Thr Gln
405 410 415
Lys Ser Leu Ser Leu Ser Leu Gly Lys
420 425
<210> 22
<211> 444
<212> PRT
<213> Artificial Sequence
<220>
<223> FceRIa ECD-铰链-Fc3
<400> 22
Val Pro Gln Lys Pro Lys Val Ser Leu Asn Pro Pro Trp Asn Arg Ile
1 5 10 15
Phe Lys Gly Glu Asn Val Thr Leu Thr Cys Asn Gly Asn Asn Phe Phe
20 25 30
Glu Val Ser Ser Thr Lys Trp Phe His Asn Gly Ser Leu Ser Glu Glu
35 40 45
Thr Asn Ser Ser Leu Asn Ile Val Asn Ala Lys Phe Glu Asp Ser Gly
50 55 60
Glu Tyr Lys Cys Gln His Gln Gln Val Asn Glu Ser Glu Pro Val Tyr
65 70 75 80
Leu Glu Val Phe Ser Asp Trp Leu Leu Leu Gln Ala Ser Ala Glu Val
85 90 95
Val Met Glu Gly Gln Pro Leu Phe Leu Arg Cys His Gly Trp Arg Asn
100 105 110
Trp Asp Val Tyr Lys Val Ile Tyr Tyr Lys Asp Gly Glu Ala Leu Lys
115 120 125
Tyr Trp Tyr Glu Asn His Asn Ile Ser Ile Thr Asn Ala Thr Val Glu
130 135 140
Asp Ser Gly Thr Tyr Tyr Cys Thr Gly Lys Val Trp Gln Leu Asp Tyr
145 150 155 160
Glu Ser Glu Pro Leu Asn Ile Thr Val Ile Lys Ala Pro Arg Glu Lys
165 170 175
Tyr Trp Leu Gln Ala Gln Pro Gln Ala Glu Gly Ser Leu Ala Lys Ala
180 185 190
Thr Thr Ala Pro Ala Thr Thr Arg Asn Thr Gly Arg Gly Gly Glu Glu
195 200 205
Lys Lys Gly Ser Lys Glu Lys Glu Glu Gln Glu Glu Arg Glu Thr Lys
210 215 220
37
CN 111587251 A 序 列 表 18/18 页
Thr Pro Glu Cys Pro Ser His Thr Gln Pro Leu Gly Val Phe Leu Phe
225 230 235 240
Pro Pro Lys Pro Lys Asp Thr Leu Met Ile Ser Arg Thr Pro Glu Val
245 250 255
Thr Cys Val Val Val Asp Val Ser Gln Glu Asp Pro Glu Val Gln Phe
260 265 270
Asn Trp Tyr Val Asp Gly Val Glu Val His Asn Ala Lys Thr Lys Pro
275 280 285
Arg Glu Glu Gln Phe Asn Ser Thr Tyr Arg Val Val Ser Val Leu Thr
290 295 300
Val Leu His Gln Asp Trp Leu Asn Gly Lys Glu Tyr Lys Cys Lys Val
305 310 315 320
Ser Asn Lys Gly Leu Pro Ser Ser Ile Glu Lys Thr Ile Ser Lys Ala
325 330 335
Lys Gly Gln Pro Arg Glu Pro Gln Val Tyr Thr Leu Pro Pro Ser Gln
340 345 350
Glu Glu Met Thr Lys Asn Gln Val Ser Leu Thr Cys Leu Val Lys Gly
355 360 365
Phe Tyr Pro Ser Asp Ile Ala Val Glu Trp Glu Ser Asn Gly Gln Pro
370 375 380
Glu Asn Asn Tyr Lys Thr Thr Pro Pro Val Leu Asp Ser Asp Gly Ser
385 390 395 400
Phe Phe Leu Tyr Ser Arg Leu Thr Val Asp Lys Ser Arg Trp Gln Glu
405 410 415
Gly Asn Val Phe Ser Cys Ser Val Met His Glu Ala Leu His Asn His
420 425 430
Tyr Thr Gln Lys Ser Leu Ser Leu Ser Leu Gly Lys
435 440
38
CN 111587251 A 说 明 书 附 图 1/12 页
39
CN 111587251 A 说 明 书 附 图 2/12 页
图1
40
CN 111587251 A 说 明 书 附 图 3/12 页
图2
41
CN 111587251 A 说 明 书 附 图 4/12 页
图3
图4
42
CN 111587251 A 说 明 书 附 图 5/12 页
43
CN 111587251 A 说 明 书 附 图 6/12 页
44
CN 111587251 A 说 明 书 附 图 7/12 页
45
CN 111587251 A 说 明 书 附 图 8/12 页
46
CN 111587251 A 说 明 书 附 图 9/12 页
图5
47
CN 111587251 A 说 明 书 附 图 10/12 页
图6
图7
48
CN 111587251 A 说 明 书 附 图 11/12 页
图8
49
CN 111587251 A 说 明 书 附 图 12/12 页
图9
50












