 技术摘要:
技术摘要: 本发明一种基于机器学习的区块链共识算法,包括步骤:将区块链系统中所有的节点划分为客户节点、主节点、监督节点3种不同的类型;每种类型的节点具备不同的功能;设准备阶段和确认阶段的算法过程;客户节点在发送数据块生产请求后,对此次请求通过的概率进行预测;若概 全部
背景技术:
随着区块链技术的发展,其核心技术之一共识算法也随之发展。在目前现有的共
识算法中,PBFT算法是较为经典的分布式一致性算法,PBFT算法基于状态机复制原理,通过
预准备阶段、准备阶段、确认阶段三阶段来完成和实现节点之间的共识,并且在此过程中能
够通过大多数诚实节点来忽略掉恶意节点的消息,该算法能够容忍不超过(n-1)/3个节点
为恶意节点(其中,n为节点总数)。但是,PBFT算法,无法动态感知节点数目的变化,且在客
户节点发送请求后一直处于空闲等待状态,造成一定量的资源浪费,同时等待时间也使得
时延增加。
随着研究的深入,很多新的共识算法不断被一些专家和学者提出,其证明方式趋
向于多样化和混合化。授权拜占庭(Delegated Byzantine Fault Tolerant,dBFT)算法,将
POS算法与PBFT算法结合,是一种通过代理投票实现大规模参与的共识协议,具有快速、扩
展性好等特点,但是其节点数量有限,当节点总数超出一定范围时其性能则有所下降。
信用拜占庭协议CPBFT(credit practical byzantine fault tolerance) ,对原
有的PBFT进行了部分改进,引入行为积分和分级机制。CPBFT通过记录和评估节点行为来确
定网络中节点的信用等级。通过动态删除信用评分低的节点来提高共识效率和保证系统的
可扩展性和动态性。但是,信用评估将需要额外的通信过程来使信用评分达成一致,浪费一
定的宽带资源。
通过对已有算法的分析,尤其是分布式系统的共识算法:PBFT算法、dBFT算法、
CPBFT算法等,针对这些共识算法的不足之处,提出新的改进算法尤为必要,因此本算法提
出了一种基于机器学习的区块链共识算法。
技术实现要素:
发明目的:本发明的目的是提供一种有效降低时延、提升效率的基于机器学习的
区块链共识算法。
技术方案:一种基于机器学习的区块链共识算法,包括以下步骤:
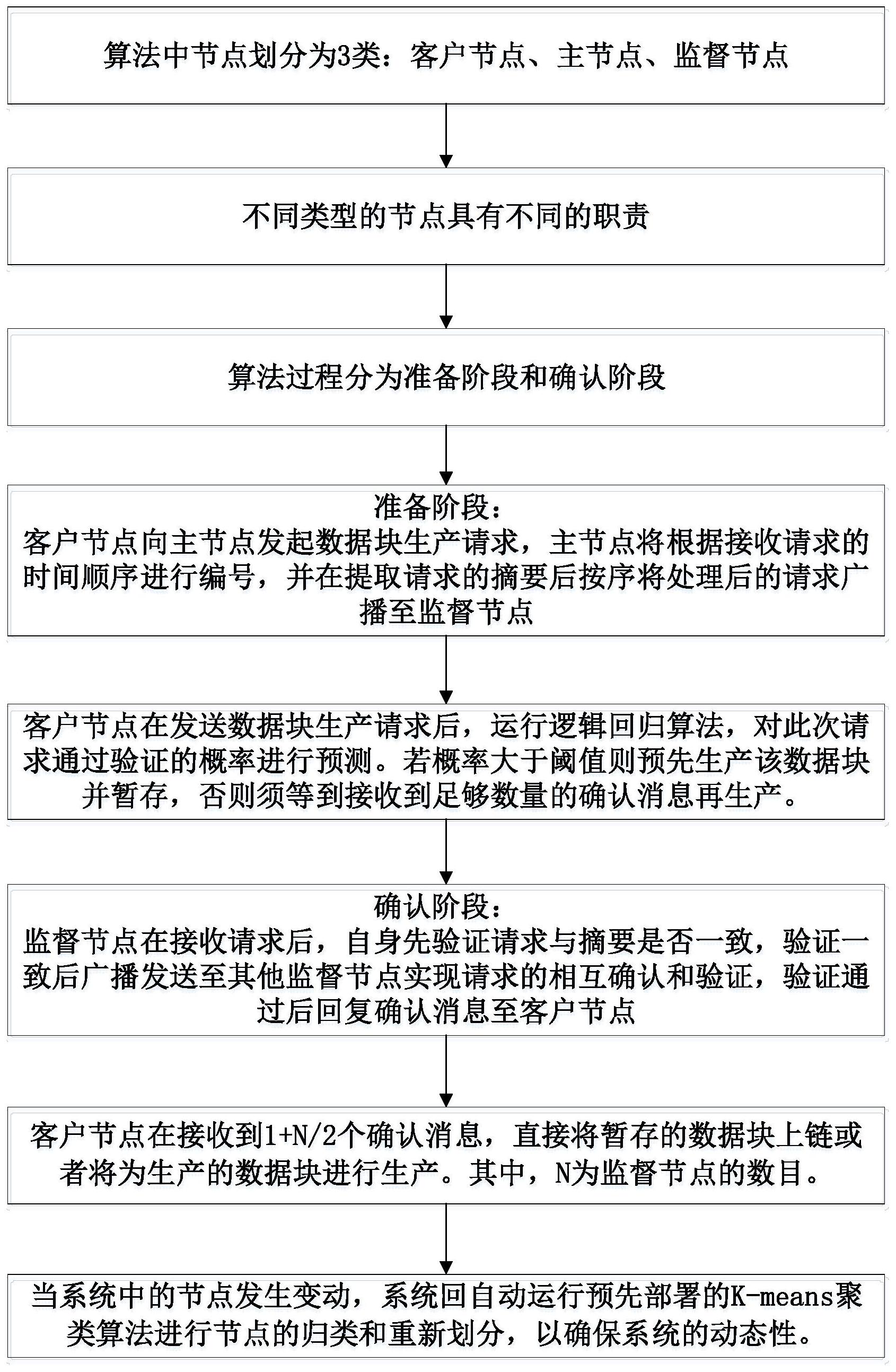
A、将所有在网络中的所有节点划分为3种不同的类型:客户节点、主节点和监督节
点;每一种类型的节点具有其具体的数目,可设客户节点数目为Nc,主节点数目为Nm,监督
节点数目为Ns;
B、每种类型的节点具备不同的功能设置:客户节点用于发起数据块生产请求及生
产数据块;主节点用于对客户节点的请求进行编号和提取摘要,并将处理过的请求发送至
监督节点;监督节点用于验证请求并回复确认消息给客户节点;
C、设准备阶段和确认阶段的算法过程;
D、准备阶段:客户节点向主节点发起数据块生产请求,主节点将根据接收请求的
时间顺序进行编号并提取请求的摘要;然后按编号顺序将处理后的请求发送至监督节点;
6
CN 111598127 A 说 明 书 2/9 页
E、确认阶段:监督节点在接收请求后,先验证请求与摘要是否一致,一致为Y,不一
致为N,验证后添加自身验证结果(一致为Y,不一致为N)至消息中,验证一致的,然后发送至
其他监督节点实现请求的相互确认和验证,验证通过后回复确认消息至客户节点;
F、客户节点在发送数据块生产请求后,运行逻辑回归算法,对此次请求通过的概
率进行预测;若概率大于0.7,则提前生产该数据块,待接收到1 Ns/2个监督节点的确认消
息后,直接发送新的数据块生产请求,其中,Ns为监督节点的数目;若概率不大于0.7,则需
要在接收到1 Ns/2个监督节点的确认消息后,才能生产数据块。
G、整个区块链系统中预先部署K-means聚类算法,当系统中的节点数目增加或减
少时,所述算法启动,将增加的节点归类或调整因减少节点造成的类别数目差异。
进一步的,所述步骤A中所述算法中节点的划分:
a-a、算法中的节点分3类:客户节点、主节点、监督节点;
a-b、不同类型的节点具有不同的数目,可设客户节点数目为Nc,主节点数目为Nm,
监督节点数目为Ns;
a-c、节点类型划分规则如下:
a-c-a、所有节点在加入区块链系统时,除了提供自身的真实身份信息外,还需提
供其本身对所要成为类型的期望值x和本身具有的资源y等两项重要信息;
a-c-b、其中期望值x取值范围为1~5,资源y的取值范围为0~1;
a-c-c、当x取值处于1~3且y的取值处于0~0.5时,该类节点为客户节点;当x取值
处于2~4且y的取值处于0.5~1时,该类节点为主节点;当x取值处于3~5且y的取值处于0
~0.5时,该类节点为监督节点。
进一步的,所述步骤B所述功能设置:
b-a、客户节点用于发起数据块生产请求和生产数据块,同时通过逻辑回归算法预
测自己发起的数据块生产请求通过验证的概率,并根据概率确定是否提前生产数据块;
b-b、主节点用于将客户节点的请求按照时间顺序进行编号,并对请求进行摘要提
取,然后按编号顺序将请求广播发送至所有的监督节点;
b-c、监督节点依编号顺序对请求的确认和验证,在接收到主节点的消息后,自身
先验证请求与摘要是否一致并将验证结果(一致为Y,不一致为N)添加至消息中,之后广播
发送至其他监督节点进行彼此确认验证,当监督节点收到多于Ns/2个来自其他监督节点的
验证通过消息后,回复确认消息至客户节点。
进一步的,所述步骤D中算法过程中的准备阶段:
d-a、客户节点发起生产数据块请求,请求消息内容为Request:
,Bcontent为将要生产的数据块,Tc为客户节点发送Request消息的时间戳,Sc为客户节点
的签名;数据块分为块头和数据两部分,块头为上一个数据块的简要信息,若该块为创世
块,则块头信息标识为为创世块;
d-b、主节点接收到Request消息后,将该消息进行编号,提取摘要信息,并添加时
间戳和签名,之后广播发送至所有的监督节点,所发送的消息为Query:,D,Tm,Sm>,Num为编号,D为摘要,Tm为主节点添加的时间戳,Sm为主节点的签名;
d-c、客户节点在发送数据块生产请求后,运行逻辑回归算法,对本次请求通过的
概率进行预测。
7
CN 111598127 A 说 明 书 3/9 页
进一步的,步骤d-c所述的预测过程如下:
d-c-a、现已存在的样本数据
每个样本数据中的
包含4个特征值
d-c-b、其中,X1为客户节点历史成功生产数据块的概率,X2为监督节点历史回复验
证通过的概率,X3为监督节点历史回复验证不通过的概率,X4为监督节点不回复任何消息的
概率,y为请求被验证通过的概率,概率均在(0,1)区间内;
d-c-b、将样本数据种的 作为输入参数,;
d-c-c、将步骤d-c-b中所述 乘以权重矩阵 再加上偏差 得到中间结果
d-c-d、输出为Y={0,1},使用Sigmoid函数将中间结果 转化成0值或1值,
Sigmoid函数如下:
得公式:
d-c-e、根据上述公式以及Python代码结合已有的样本数据进行训练,得到权重矩
阵 和偏差 的具体数值;
d-c-f、将得到的 和 的值代入计算如下公式,即可得到逻辑回归的模型;
d-c-g、根据所得模型,对一开始的所有样本数据进行测试,将预测出的概率Y与样
本数据提供的原始概率y进行对比,得出合适的阈值;
d-c-h、实验所得具体阈值数据为0.691,取整选取0.7为阈值。
d-d、,若预测概率大于阈值,客户节点则预先生产该数据块并暂存,否则等待确认
8
CN 111598127 A 说 明 书 4/9 页
消息。进一步的,所述步骤E中算法过程中的确认阶段,具体包括以下步骤:
e-a、监督节点接收主节点发送过来的Query消息后,首先自我验证,验证请求与摘
要是否一致,添加自身验证结果后广播发送消息至其他监督节点进行彼此确认验证,广播
发送的消息为Valid:,D,Tm,Sm>,Y/N>,其中ID为监督节点自
身的号码,Y表示验证请求与摘要一致,N表示验证请求与摘要不一致;
e-b、当监督节点收到至少1 Ns/2个(Ns为监督节点的数目)个带有Y的Valid消息
后,回复确认消息至客户节点,确认消息为Commit:,D,Tm,Sm
>,Y/N,Ts,Ss>,Ts为监督节点添加的时间戳,Ss为监督节点的签名;
e-c、客户节点接收到至少1 Ns/2个(Ns为监督节点的数目)个包含Y的Commit消息
时,则认为预先生产的数据块有效,或者根据收到的Commit消息生产预测通过概率低于0.7
的数据块;否则此次请求不通过,客户节点将其丢弃后由客户节点重新发起请求。
进一步的,所述步骤G中保证系统可扩展性的K-means聚类算法:
g-a、预先部署K-means聚类算法,节点划分为3种类型,由于在节点总数变动之前
已进行过若干次共识过程,所有的节点当中可能存在恶意节点,因此将K设为4;
g-b、客户节点生成创世块后,K-means算法被触发,并一直处于开启状态,一旦节
点数目发生变动,则自动运行;
g-c、此时,每个节点具有标明其特征的两个参数值:节点当前的类型x,节点本身
在此之前诚实工作的频率y,
g-d、其中期望值x取值范围为1~5,资源y的取值范围为0~1;g-e、当系统中的节
点数目首次发生变动时,K-means自动运行,进行计算,具体如下:g-e-a、当系统中节点数增
加时:
g-e-a-a、新加入的节点需要提供其本身对所要成为类型的期望值x和本身具有的
资源y,各自的取值范围同步骤g-d中所述;
g-e-a-b、运行K-means算法,从所有的节点当中任选4个为初始聚类中心;
g-e-a-c、使用欧氏距离计算其余所有节点到此4个初始聚类中心的距离;
g-e-a-d、根据计算所得,将节点与距离最近的聚类中心节点归为同一类;然后,重
新计算选取新的聚类中心节点;
g-e-a-d、当新的聚类中心节点与上一次聚类中心节点之间的距离为0时,完成分
类。
g-e-b、当系统种节点数目减少时:
g-e-b-a、运行K-means算法,从所有的节点当中任选4个为初始聚类中心
g-e-b-b、使用欧氏距离计算其余所有节点到此4个初始聚类中心的距离;
g-e-b-c、根据计算所得,将节点与距离最近的聚类中心节点归为同一类;然后,重
新计算选取新的聚类中心节点;
g-e-b-d、当新的聚类中心节点与上一次聚类中心节点之间的距离为0时,完成分
类;
g-f、当系统中的节点数目再次发生变动时,将上次次计算得到的聚类中心的结果
作为此次的初始聚类中心点即可。
有益效果:本发明的,与现有技术相比,具有以下优点:
9
CN 111598127 A 说 明 书 5/9 页
1 .本发明以PBFT算法为基础,结合逻辑回归算法,通过对数据块生产请求是否通
过的预测结果,提前生产数据块,充分利用等待确认消息的时间,简化步骤,降低时延,提升
效率。
2.本发明利用K-means算法,其中K为3,在系统中节点总数目发生变化时,K-means
算法自动被触发运行,对发生变化的节点进行类别划分,找出各类别节点的数目,确保系统
的动态性和可扩展性。
3.本发明与PBFT、dBFT、CPBFT算法相比,具有更低时延、更高的吞吐量,以及一定
的动态性。
附图说明
图1为本发明的算法流程图;
图2为本发明的算法的节点类别划分及职责结构图;
图3为本发明的算法判断流程图;
图4为本发明的客户节点预测请求是否通过的流程图;
图5为本发明的保证系统动态性的K-means算法。。












