
技术摘要:
本发明属于计算机视觉领域、人物识别,为更好的通过人体姿态信息达到更高准确度的人物重识别。为达上述目的,本发明,可穿戴设备下基于形状和姿态的跨视角人物识别方法,给定第一相机中待检测行人的视频帧图像和第二相机获得的视频,对于前两者所有的视频帧都检测出对 全部
背景技术:
作为图像检索的一个子问题,跨视角人物识别(CVPI)的研究非常重要,并具有广 泛的应用场景,例如:室外密集区域下的视频监控、智能的人机交互和军事调查中。早期的 研究要追溯到跨摄像头多目标跟踪问题上,传统监控视频大多都是通过固定位置的摄像头 获得的,它们只能从预先固定的视角覆盖有限的区域,由于摄像头的固定性会造成遮挡和 摄像头中目标行人视野消失等问题,所以早期的研究主要致力于解决当目标行人在某个相 机视野中丢失之后如何将其行动轨迹,在其他相机视野下再次关联起来的问题上。近年来, 随着可穿戴相机技术的更新和普及,拍摄者可使用可穿戴相机进行拍摄,进而扩大了视频 的覆盖区域,进而在多段假定时间同步的视频中寻找到同一名行人成为CVPI的一个研究热 点。 CVPI是通过在视频之间匹配人物外观和其运动特征来实现的,而姿态特征的匹配 是在野外采集的视频、图像上进行的,由于野外数据集的高度不准确性,故基于3D人体姿态 估计的方法无法很好的提高CVPI性能。为了解决这一问题,各国的研究人员们提出了很多 有效的方法,郑康等人(Zheng K ,Fan X ,Lin Y ,et al .Learning view-invariant features for person identification in temporally synchronized videos taken by wearable cameras[C]//Proceedings of the IEEE International Conference on Computer Vision.2017:2858-2866.)首先提出使用监督深度学习的方法提取视点不变运 动特征,并运用人体外观特征和运动特征的相互影响的方法,提高CVPI匹配结果的准确度, 该方法基于光流来表示每个视频中的人物姿态,但是仅检查光流的相似性对于CVPI来说是 不全面的,故郑康等人(Liang G ,Lan X ,Zheng K ,et al .Cross-View Person Identification by Matching Human Poses Estimated with Confidence on Each Body Joint[C]//Thirty-Second AAAI Conference on Artificial Intelligence.2018.)保留 运用人体外观特征和运动特征的思想,提出了添加置信度的思想,分别引入2D置信度、3D置 信度和时间置信度,实验结果表明不准确估计的人体姿态、不同的置信度量组合和将姿态 信息集成到外观和运动特征上的方法,可以达到当时最好的CVPI性能。由于该方法估计出 的姿态的不准确性,且检测集是通过视频的连续帧图片输入的,但该方法忽略了视频连续 帧中姿态一致性的特点,会在一定程度上影响CVPI的准确性。
技术实现要素:
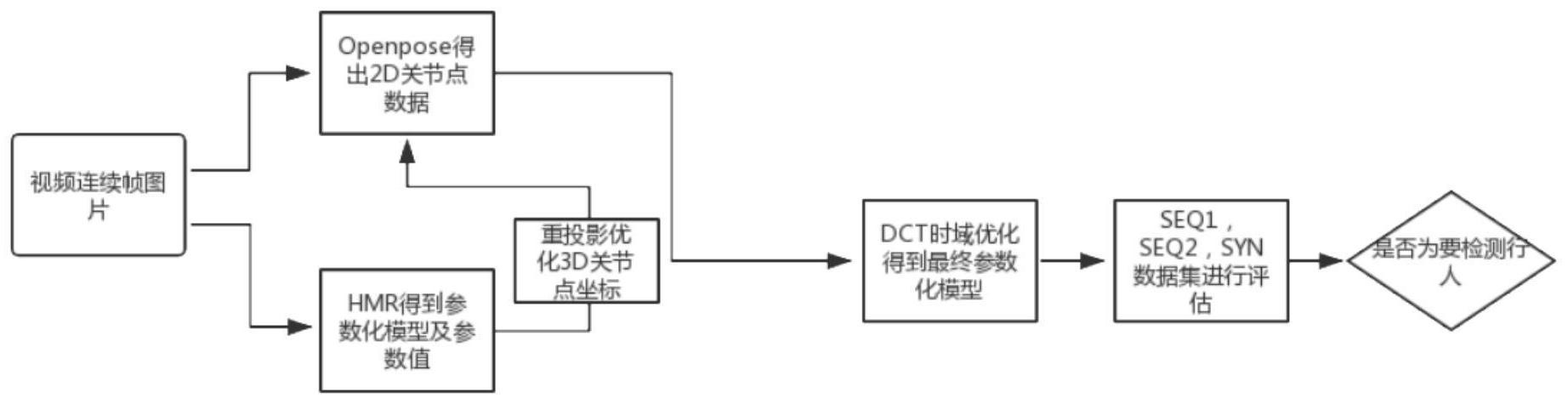
为克服现有技术的不足,本发明旨在提出一种准确度更高的CVPI方法,可以更好 的通过人体姿态信息达到更高准确度的人物重识别。为达上述目的,本发明采取的方案是, 可穿戴设备下基于形状和姿态的跨视角人物识别方法,给定第一相机中待检测行人的视频 4 CN 111582036 A 说 明 书 2/6 页 帧图像和第二相机获得的视频,对于前两者所有的视频帧都检测出对应该帧图像的人体参 数化模型和二位关节点位置,二维关节点位置的作用是为了优化人体参数化模型Smpl,之 后通过三维关节点重投影优化操作和人体参数化模型的离散余弦变换DCT时域优化操作获 得最终的人体参数化模型,将待检测目标的最终人体参数化模型与第二相机中每一个视频 帧中的人体参数化模型做对比,找出所要检测的目标。 具体步骤如下: (1)通过二维人体关节点的检测方法OpenPose得到视频帧图像的2D关节点位作为 输入; (2)人体参数化模型和对应参数的检测方法通过HMR获得人体参数化模型Smpl及 该模型对应人体3D关节点位置; (3)由步骤(2)得到对应视频帧的人体参数化模型Smpl,Smpl由两组参数控制,一 组用于身体形状,另一组用于姿态; (4)得出相机参数和控制Smpl参数化模型的形状参数β、姿态参数θ; (5)使用能量方程EM(β,θ)、Ep(β,θ)、 优化方程: Smpl模型记为M(β,θ,Φ),β是对于参数化模型的形状参数向量,θ是参数化模型对 应的姿态参数,Φ是从很多参数化模型中学习到的混合参数,首先估计V个不同视频中每一 帧的β,θ参数,将它们对应的2D关节点表示为 将这部分的能量方程定义如 下: 方程中,KV是拍摄视频V的相机参数,EP是考虑Eβ,Eθ两部分的先验项,EJ代表关节点 拟合项这也是该步骤的核心方程,Eβ是在Smpl形状训练数据中学习得到的,表示为形状参 数的能量方程,Eθ是在CMU(Cmu mocap dataset)运动捕捉数据集上学到的,表示为姿态参 数部分的能量方程,EP,EJ分别如下: EP(β,θ)=λθEθ(θ) λβEβ(β) (2) 这里J(β)返回23个关节点的三维坐标,R是旋转方程,ΠK是将3D坐标映射到2D平 面的方程,wi则是2D关节点估计方法得到的置信值,ρσ是关于残差e和鲁棒性参数σ的误差函 数,考虑到整个过程中不可避免的检测噪声和误差,使用误差函数Geman-McClure代替标准 平方误差,其定义如下: (6)DCT时域优化部分:由2D关节点拟合项与对应系数为C的低维DCT重建项B组成, 具体形式为: 5 CN 111582036 A 说 明 书 3/6 页 其中Θ={θ1,θ2,......,θN},是N帧视频中的姿态参数集合,Θ为上一阶段获得姿 态参数的中位数,C是对应的DCT系数,D是所有帧的3DSmpl关节点的集合,De ,d代表第e个 Smpl模型上关节点d的坐标,具体定义为: De,d=[Rθ1(Jd(βm))e,Rθ2(Jd(βm))e,......RθN(Jd(βm))e] (6) βm为上一步骤中得到的形状参数中位数,通过重建项为B的低维DCT近似N个帧中 的De,d轨迹: 本发明的特点及有益效果是: 本发明针对参数化模型的形状和姿态的优化方法进行CVPI性能的提升,具有以下 特点: ①在本发明中,我们建立了一个多模块的框架,从姿势和形状的线索进行多个可 穿戴相机的人物重识别。 ②由于考虑到使用人的形状特征来解决穿着相似和动作相似的问题,本发明使用 Smpl模型来代替传统的3D人体姿势估计操作,提高了行人重识别的性能。 ③本发明提出了一种基于投影优化Smpl模型姿态参数的技术,进而提高检测目标 人物对应的Smpl模型形状和姿态估计的精度。 ④本发明通过施加多帧联合时域优化来获得时域一致的姿态来解决遮挡问题,获 得时域一致的参数化模型,进而提高最后CVPI的准确性。 附图说明: 本发明上述各步骤与下面对实施细节的描述及实验结果参考附图将变得清晰和 容易理解。 图1方法流程示意图。











