
技术摘要:
本发明实施例公开了一种面向Spark MLlib机器学习算法优化方法,包括:步骤1,通过训练数据集的扩充矩阵运算得到γ矩阵,所述γ矩阵包含训练数据集的统计信息,所述训练数据集的统计信息用于求解机器学习算法的参数;步骤2,通过所述γ矩阵求解机器学习算法的参数。通过 全部
背景技术:
随着计算机和信息技术的不断发展,商业活动和科学研究都产生了海量的数据需 要去存储和分析,但是单机的性能存在很大的限制。分布式和超算系统是两个不同的解决 方案,由于成本和技术问题,分布式大数据处理框架成为了热门的研究领域。 近些年来类似MapReduce,Spark,Giraph等分布式大数据处理框架受到了越来越 多的关注。Spark依靠弹性分布式数据集(Resilient Distributed Dataset,RDD)带来了性 能和拓展性的优势,同时带来的scala函数式编程接口由于其易于使用特点,在众多分布式 编程框架中脱颖而出。而RDD是一种分布式内存数据集的抽象,提供函数式的编程接口。RDD 由一系列可以分布于不同机器上的Partition组成,并能够在数据丢失的情况下提供重新 计算的方法,相比于MapReduce基于磁盘的计算框架而言,RDD具有相当大的性能提升,具体 的,通过Big data Sort Benchmark对二者的比较结果显示Spark的排序性能相比 MapReduce而言有大概3倍的提升。 此外,Spark支持有向无环图(Directed acyclic graph,DAG)构造计算图。与 MapReduce那样只包含map,reduce相的简单计算框架不同,Spark任务一般会划分成多个 stage,没有依赖关系的stage可以同时用不同的线程运行。Spark中,除了all-to-all shuffle,还支持union,group By Key,join等communication模式。此外Spark允许数据通 过RDD驻留在内存之中,Spark相比MapReduce,对于数据本地化更加敏感,因为Spark从远程 内存获取数据的速度比本地内存获取慢10倍,而MapReduce从远程磁盘获取数据速度只是 本地的1-3倍。Spark社区在分布式计算引擎的基础上构建了一个生态系统来满足各种各样 的计算需求,包括Spark MLlib,Spark SQL,Spark Streaming,Spark GraphX。 其中,Spark MLlib是基于RDD函数式接口开发的机器学习库,它提供了对用户非 常友好的接口用于高效率的构建机器学习模型。但是MLlib还存在不少的问题,性能还有很 大的提升空间。此外对于大规模机器学习算法性能评估方面,一些老的benchmark平台不能 很好地适用于Spark平台,而IBM2015年设计的SparkBench过于沉重。 基于上述背景,本申请提出一种面向Spark MLlib机器学习算法优化方法。
技术实现要素:
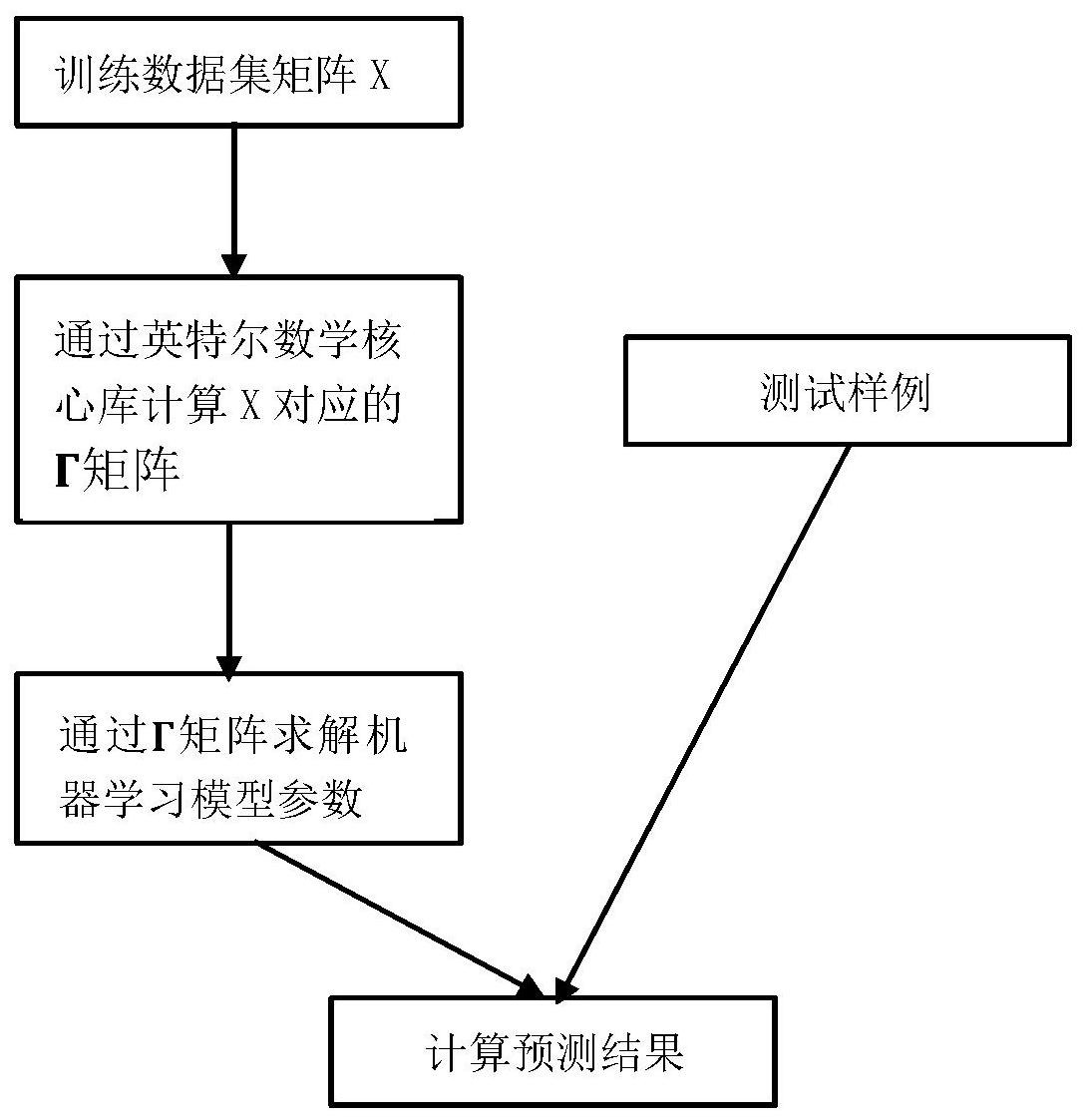
为了优化Spark中机器学习算法,首先需要找到机器学习应用的性能瓶颈,对于一 个分布式的机器学习应用,主要的性能开销包括CPU运算,磁盘IO,内存IO以及网络IO,找到 这四个因素中最主要的因素,然后对那一块进行优化是更加明智的选择。为了找到性能瓶 颈,一般的做法是用profiler来分析机器学习算法的benchmark来找到瓶颈,通过Ganglia 对Spark应用的分析和对源代码的观察,发现MLlib中机器学习算法大致可以分为两种,一 4 CN 111612154 A 说 明 书 2/9 页 个是基于分析解的机器学习算法,训练过程通过矩阵运算即可完成;另一种是通过mini- batch SGD最小化损失函数从而完成模型训练的算法。本申请主要关注于优化第一种算法, 提出了一种面向Spark MLlib机器学习算法优化方法,通过γ矩阵实现了主成分分析 (Principal Components Analysis,PCA)算法和线性回归(linear regression,LR)算法, 算法的流程示意图如图1所示,并且通过设计的全新benchmark平台,评估了本发明的实现 和Spark MLlib的实现性能对比,benchmark平台的结构如图2所示。 一种面向Spark MLlib机器学习算法优化方法,包括以下步骤: 步骤1,通过训练数据集的扩充矩阵运算得到γ矩阵,所述γ矩阵包含训练数据集 的统计信息,所述训练数据集的统计信息用于求解机器学习算法的参数; 步骤2,通过所述γ矩阵求解机器学习算法的参数。 进一步地,在一种实现方式中,所述步骤1包括:定义所述γ矩阵及γ矩阵的属性, 所述γ矩阵的定义如下: 对于所述机器学习算法,所述训练数据集由相同维度的特征向量以及每个特征向 量对应的标签构成,使用X代表d*n的输入矩阵,所述输入矩阵X的每一列都是训练数据集中 一个样本的特征向量,d为所述特征向量的维数,n为所述训练数据集大小,Y代表标签向量, 所述标签向量是一个n维向量,所述标签向量的每个值与训练数据集中每个样本一一对应; 所述γ矩阵的定义中: n=|X| 其中,n代表输入矩阵的大小,即训练数据集的大小,xi代表输入矩阵X的第i列,即 输入矩阵X的列向量,L代表输入矩阵X的第i列xi的线性和,Q代表输入矩阵X所有列向量xi的 二次和,即所有列向量xi的外积之和。 进一步地,在一种实现方式中,所述步骤1包括:所述γ矩阵通过输入矩阵X的一个 扩充矩阵Z进行运算得到,所述扩充矩阵Z的定义为: 相应的γ矩阵表示为: 通过所述扩充矩阵Z的所有列向量xi的外积之和计算γ矩阵,即 5 CN 111612154 A 说 明 书 3/9 页 进一步地,在一种实现方式中,所述步骤2包括通过γ矩阵求解主成分分析算法的 参数,包括: 计算所述输入矩阵X的协方差矩阵或关系矩阵,所述输入矩阵X的协方差矩阵表示 为V,所述输入矩阵X的关系矩阵表示为ρ,所述关系矩阵ρ即对协方差矩阵V每个维度进行标 准化后得到的矩阵; 根据所述关系矩阵ρ的公式和Γ矩阵的表达式,得出以下公式: 其中,ρab为关系矩阵ρ第a行第b列的元素,n为训练数据集大小,Qab为xi的二次和矩 阵的第a行第b列元素,La为线性和向量的第a个元素,Lb为线性和向量的第b个元素,Qaa为xi 的二次和矩阵的第a行第a列元素,Qbb为xi的二次和矩阵的第b行第b列元素; 将所述关系矩阵ρ作为主成分分析算法的关键参数,通过对所述关系矩阵ρ进行特 征值分解,按照从大到小的顺序,取前k个的特征值对应的特征向量构成投影矩阵,将所述 投影矩阵与输入矩阵X相乘即完成降维。 进一步地,在一种实现方式中,所述步骤2包括通过γ矩阵求解线性回归算法的参 数,所述参数包括线性乘法的系数β,包括: 按照以下形式表达线性回归的数值解: Y=βTX ∈ β=(XXT)-1XYT =Q-1(XYT) 其中,使用X代表d*n的输入矩阵,d为特征向量的维数,n为训练数据集大小,∈代 表高斯误差,Q代表输入矩阵X所有列向量的二次和。 进一步地,在一种实现方式中,所述γ矩阵对于主成分分析算法模型或线性回归 算法模型的训练数据集满足n>>d,即训练数据集的大小n远大于特征向量的维数d,此时满 足O(d^2)<











