
技术摘要:
本申请涉及人工智能,提供了一种强化学习方法和装置,能够提高强化学习的训练效率。该方法包括:获取结构图,结构图包括通过学习获取的环境或智能体的结构信息;向智能体的策略函数输入环境的当前状态和结构图,策略函数用于生成响应于当前状态和结构图的动作,智能体 全部
背景技术:
人工智能(artificial intelligence,AI)是研究用于模拟、延伸和扩展人的智能 的理论、方法、技术及应用系统的一门新的技术科学。机器学习是人工智能的核心。机器学 习的方法包括强化学习。 强化学习是智能体(agent)以“试错”的方式进行学习,通过动作(action)与环境 进行交互获得的奖励(reward)指导行为,目标是使智能体获得最大的奖励。策略函数是智 能体在强化学习中使用的行为的规则。策略函数通常为一个神经网络。智能体的策略函数 通常采用深度神经网络,但深度神经网络往往存在学习效率不高的问题。在训练神经网络 参数量庞大的情况下,如果给定有限的数据或训练轮数,则会导致策略函数的预期收益较 低,从而强化学习的训练效率也较低。 因此,提高强化学习的训练效率是业界亟待解决的问题。
技术实现要素:
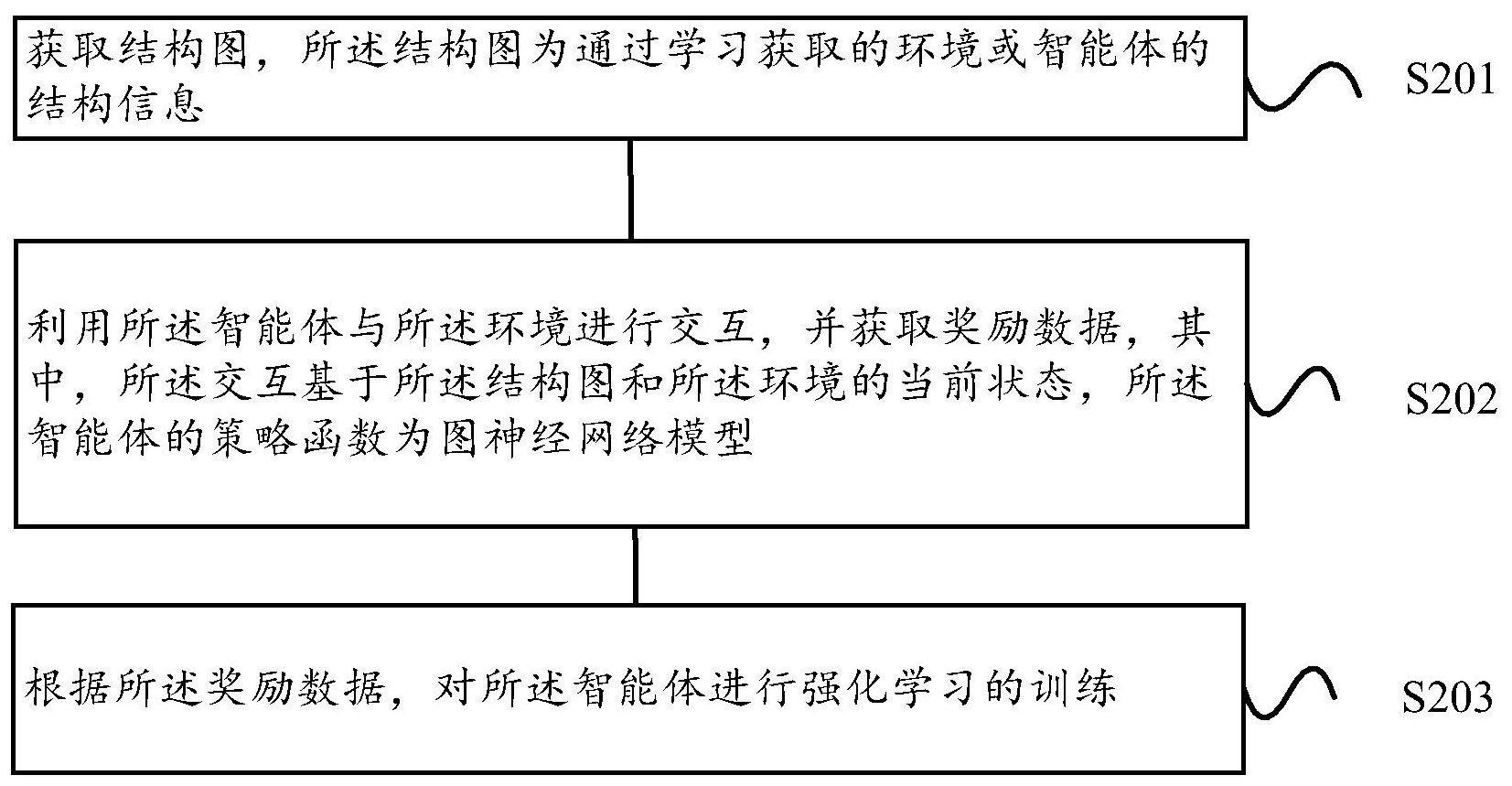
本申请提供一种强化学习的方法和装置,能够提高强化学习的训练效率。 第一方面,提供了一种强化学习的方法,包括:获取结构图,所述结构图包括通过 学习获取的环境或智能体的结构信息;向所述智能体的策略函数输入所述环境的当前状态 和所述结构图,所述策略函数用于生成响应于所述当前状态和所述结构图的动作,所述智 能体的策略函数为图神经网络;利用所述智能体向所述环境输出所述动作;利用所述智能 体从所述环境获取响应于所述动作的下一个状态和奖励数据;根据所述奖励数据,对所述 智能体进行强化学习的训练。 在本申请实施例中,提供了一种强化学习的模型架构,其将图神经网络模型作为 智能体的策略函数,并通过学习获取环境或智能体的结构图,使得智能体可以基于该结构 图与环境之间进行交互,以实现对智能体的强化训练。这种强化方式中将自动学习得到的 结构图和作为策略函数的图神经网络结合起来,能够缩短强化学习找到更优解的时间,提 高了强化学习的训练效率。 在本申请实施例中,利用图神经网络模型作为智能体的策略函数,其可以包括对 环境结构的理解,从而可以提高对智能体的训练效率。 结合第一方面,在第一方面的一种可能的实施方式中,所述获取结构图,包括:获 取所述环境的历史交互数据;将所述历史交互数据输入至结构学习模型;利用所述结构学 习模型从所述历史交互数据中学习结构图。 在本申请实施例中,可以通过结构学习模型从历史交互数据中获取环境结构,实 现对环境的自动的结构学习,并将该结构图应用于强化学习中,以提高强化学习的效率。 结合第一方面,在第一方面的一种可能的实施方式中,在将所述历史交互数据输 4 CN 111612126 A 说 明 书 2/14 页 入至结构学习模型之前,还包括:利用掩码过滤所述历史交互数据,所述掩码用于消除所述 智能体的动作对所述历史交互数据的影响。 在本申请实施例中,可以通过将历史交互数据输入至结构学习模型中获取结构 图,并且利用掩码对历史交互数据进行处理,以过滤智能体动作对环境的观测数据的影响, 从而能够提高结构图的准确性,提高强化学习的训练效率。 结合第一方面,在第一方面的一种可能的实施方式中,所述结构学习模型利用掩 码计算损失函数,其中,所述掩码用于消除所述智能体的动作对所述历史交互数据的影响, 所述结构学习模型基于所述损失函数学习所述结构图。 在本申请实施例中,可以利用掩码计算结构学习模型中的损失函数,以过滤智能 体动作对环境的观测数据的影响,从而能够提高结构图的准确性,提高强化学习的训练效 率。 结合第一方面,在第一方面的一种可能的实施方式中,所述结构学习模型包括以 下任意一项:神经交互推断模型、贝叶斯网络和线性非高斯无环图模型。 结合第一方面,在第一方面的一种可能的实施方式中,所述环境为机器人控制场 景。 结合第一方面,在第一方面的一种可能的实施方式中,所述环境为包括结构信息 的游戏环境。 结合第一方面,在第一方面的一种可能的实施方式中,所述环境为多小区基站工 程参数调优的场景。 第二方面,提供了一种用于强化学习的装置,包括:获取单元,用于获取结构图,所 述结构图包括通过学习获取的环境或智能体的结构信息;交互单元,用于向所述智能体的 策略函数输入所述环境的当前状态和所述结构图,所述策略函数用于生成响应于所述当前 状态和所述结构图的动作,所述智能体的策略函数为图神经网络;所述交互单元还用于利 用所述智能体向所述环境输出所述动作;所述交互单元还用于利用所述智能体从所述环境 获取响应于所述动作的下一个状态和奖励数据;训练单元,用于根据所述奖励数据,对所述 智能体进行强化学习的训练。 可选地,该装置可以包括用于执行第一方面的方法的模块。 可选地,该装置为计算机系统。 可选地,该装置为芯片。 可选地,该装置为配置于计算机系统中的芯片或电路。例如,该装置可以称为AI模 块。 在本申请实施例中,提供了一种强化学习的模型架构,其将图神经网络模型作为 智能体的策略函数,并通过学习获取环境或智能体的结构图,使得智能体可以基于该结构 图与环境之间进行交互,以实现对智能体的强化训练。这种强化方式中将自动学习得到的 结构图和作为策略函数的图神经网络结合起来,能够缩短强化学习找到更优解的时间,提 高了强化学习的训练效率。 结合第二方面,在第二方面的一种可能的实施方式中,所述获取单元具体用于:获 取所述环境的历史交互数据;将所述历史交互数据输入至结构学习模型;利用所述结构学 习模型从所述历史交互数据中学习结构图。 5 CN 111612126 A 说 明 书 3/14 页 结合第二方面,在第二方面的一种可能的实施方式中,所述获取单元还用于:利用 掩码过滤所述历史交互数据,所述掩码用于消除所述智能体的动作对所述历史交互数据的 影响。 结合第二方面,在第二方面的一种可能的实施方式中,所述结构学习模型利用掩 码计算损失函数,其中,所述掩码用于消除所述智能体的动作对所述历史交互数据的影响, 所述结构学习模型基于所述损失函数学习所述结构图。 结合第二方面,在第二方面的一种可能的实施方式中,所述结构学习模型包括以 下任意一项:神经交互推断模型、贝叶斯网络和线性非高斯无环图模型。 结合第二方面,在第二方面的一种可能的实施方式中,所述环境为机器人控制场 景。 结合第二方面,在第二方面的一种可能的实施方式中,所述环境为包括结构信息 的游戏环境。 结合第二方面,在第二方面的一种可能的实施方式中,所述环境为多小区基站工 程参数调优的场景。 第三方面,提供了一种用于强化学习的装置,该装置包括处理器,该处理器与存储 器耦合,该存储器用于存储计算机程序或指令,处理器用于执行存储器存储的计算机程序 或指令,使得第一方面中的方法被执行。 可选地,该装置包括的处理器为一个或多个。 可选地,该装置包括的存储器可以为一个或多个。 可选地,该存储器可以与该处理器集成在一起,或者分离设置。 第四方面,提供一种芯片,该芯片包括处理模块与通信接口,处理模块用于控制所 述通信接口与外部进行通信,处理模块还用于实现第一方面中的方法。 第五方面,提供一种计算机可读存储介质,其上存储有用于实现第一方面中的方 法的计算机程序(也可称为指令或代码)。 例如,该计算机程序被计算机执行时,使得该计算机可以执行第一方面中的方法。 第六方面,提供一种计算机程序产品,该计算机程序产品包括计算机程序(也可称 为指令或代码),该计算机程序被计算机执行时使得所述计算机实现第一方面中的方法。该 计算机可以为通信装置。 附图说明 图1是强化学习的训练过程示意图。 图2是本申请一实施例的强化学习的方法的流程示意图。 图3是本申请一实施例的图神经网络的聚合方式的示意图。 图4是本申请一实施例的强化学习模型100的系统架构图。 图5是本申请一实施例的直接观测数据和受干扰的数据的对比示意图。 图6是本申请一实施例的结构学习的框架示意图。 图7是本申请一实施例的“牧羊犬游戏”的模型计算过程的示意图。 图8是本申请一实施例的“牧羊犬游戏”中的智能体模型计算流程示意图。 图9是本申请一实施例的用于强化学习的装置900的示意性框图。 6 CN 111612126 A 说 明 书 4/14 页 图10是本申请一实施例的用于强化学习的装置1000的示意性框图。











