
技术摘要:
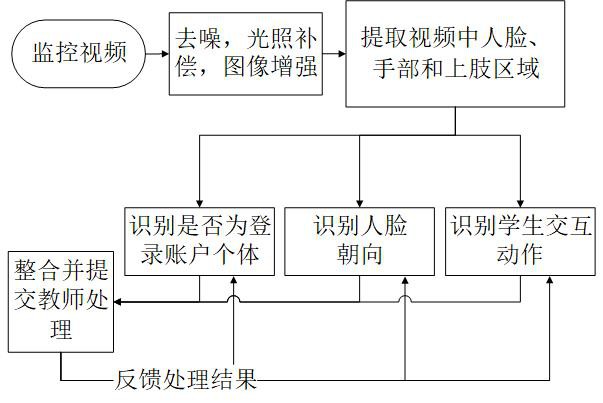
本发明公开了一种智能网课系统,针对于传统网课系统无法有效监督学生们的上课行为和互动较少的问题进行改进,利用摄像头对监控区域进行识别,并判断当前监控区域内是否是学生本人;通过模式识别技术识别当前学生的表情,注意力方向;通过模式识别技术识别当前学生与教 全部
背景技术:
随着在线教育的不断发展,大量课程采取网上教学方式。但是在实际使用中,现有 网课系统存在着如下两个问题:1.现有网课系统无法有效监督学生们的上课行为,包括:如 何监督学生们上课,如何确保当前视频下真的是学生本人,如何识别学生们的动作,这些监 督措施的缺失导致网课效果下降;2.现有网课系统过多的依赖学生们对电脑操作完成师生 互动,过多的电脑操作会导致学生们注意力下降。 本发明所提出的一种智能网课系统是利用摄像头(通常为笔记本摄像头)对监控 区域进行识别,通过目标检测技术识别当前监控区域内是否有个体,该个体是否是真人,并 且确定是否是学生本人;通过模式识别技术识别当前学生的表情,注意力方向;通过模式识 别技术识别当前学生与教师交互的手势动作,提高学生们上课的参与度。本发明涉及到的 功能不会改变原有网课系统的架构,能够以即插即用方式与现有网课系统对接,从而使本 发明在实际应用中有着较高的通用性和灵活性。
技术实现要素:
本发明所要解决的技术问题是为了克服传统网课模式无法有效监督学生们的上 课行为问题和上课互动性差的问题,提出了一种智能网课系统。本系统通过使用目标检测 和模式识别算法来识别学生的身份、注意力和手势动作,处理结果提交给教师,由教师根据 实际情况酌情处理。 本发明解决其技术问题所采用的技术方案是: 一种智能网课系统,基于笔记本自带摄像头或电脑连接的摄像头所摄的视频图像 作为输入,其中摄像头摆放在能够拍摄到人脸图像的位置,通常摆放在屏幕正前方,若不是 正前方,可以在识别结果处理模块中更改人脸朝向的基准偏移角度值来补偿摄像头摆放位 置。本系统包括:图像预处理模块,目标检测模块,人脸识别模块,头部方向检测模块,学生 动作识别模块,识别结果处理模块。 所述的图像预处理模块对摄像头采集到的图像进行去噪和光照补偿,然后进行图 像增强,最后将处理后的图像数据传递给目标检测模块;所述的目标检测模块,对接收到图 像预处理模块传递来的图像数据进行目标检测,分别检测当前区域是否有个体,若有个体 则提取其面部区域并传递给人脸识别模块和头部方向检测模块、提取上肢区域和手部区域 图像传递给学生动作识别模块;所述的人脸识别模块,对接收到目标检测模块传递来的人 脸区域图像数据进行人脸识别,并将识别结果分别传递给头部方向检测模块和识别结果处 理模块;所述的头部方向检测模块,根据目标检测模块传递来的人脸区域图像数据,并结合 人脸识别模块传递来的识别结果进行人脸朝向识别,并将结果传递给识别结果处理模块; 15 CN 111582202 A 说 明 书 2/26 页 所述的学生动作识别模块,根据目标检测模块传递来的上肢区域和手部区域图像数据,进 行动作识别,判断当前学生手部动作和上肢动作,并将识别结果传递给识别结果处理模块; 所述的识别结果处理模块对接收到的识别结果进行整合,根据人脸识别模块的识别结果判 断摄像头前的个体是否为当前登录账户对应的个体,根据头部方向检测模块所识别的个体 面部朝向来判断当前个体注意力朝向,根据学生动作识别模块来判断当前学生与教师的交 互动作。 所述的图像预处理模块,其方法是:在初始化阶段该模块不工作;在检测过程中: 第一步,对监控摄像头所摄的监控图像进行均值去噪,从而得到去噪后的监控图像;第二 步,对去噪后的监控图像进行光照补偿,从而得到光照补偿后的图像;第三步,将光照补偿 后的图像进行图像增强,将图像增强后的数据传递给目标检测模块。 所述的对监控摄像头所摄的监控图像进行均值去噪,其方法是:设监控摄像头所 摄的监控图像为Xsrc,因为Xsrc为彩色RGB图像,因此存在Xsrc-R,Xsrc-G,Xsrc-B三个分量,对于每 一个分量Xsrc′,分别进行如下操作:首先设置一个3×3维的窗口,考虑该图像Xsrc′的每个像 素点Xsrc′(i,j),以该点为中心点的3×3维矩阵所对应的像素值分别为[Xsrc′(i-1,j-1), Xsrc′(i-1,j),Xsrc′(i-1,j 1),Xsrc′(i,j-1),Xsrc′(i,j),Xsrc′(i,j 1),Xsrc′(i 1,j-1), Xsrc′(i 1,j),Xsrc′(j 1,j 1)]进行从大到小排列,取其排在中间的值为去噪后图像Xsrc″在 像素(i,j)所对应滤波后值赋值给Xsrc″(i,j);对于Xsrc′的边界点,会出现其3×3维的窗口 所对应的某些像素点不存在的情况,那么只需计算落在窗口内存在的像素点的中间值即 可,若窗口内为偶数个点,将排在中间两个像素值的平均值作为该像素点去噪后的像素值 赋值给Xsrc″(i,j),从而,新的图像矩阵Xsrc″即为Xsrc在当前RGB分量的去噪后的图像矩阵, 对于Xsrc-R,Xsrc-G,Xsrc-B在三个分量分别进行去噪操作后,将得到的Xsrc-R″,Xsrc-G″,Xsrc-B″分 量,将这三个新的分量整合成一张新的彩色图像XDen即为去噪后所得的图像。 所述的对去噪后的监控图像进行光照补偿,设去噪后的监控图像XDen,因为XDen为 彩色RGB图像,因此XDen存在RGB三个分量,对于每一个分量XDen′,分别进行光照补偿,然后将 得到的Xcpst′整合得到彩色RBG图像Xcpst,Xcpst即为XDen光照补偿后的图像,对每一个分量 XDen′分别进行光照补偿的步骤为:第一步,设X sumDen′为m行n列,构造XDen′ 和NumDen为同样m行 n列的矩阵,初始值均为0, 步长 窗口大小为l,其中函数 min(m,n)表示取m和n的最小值, 表示取整数部分,sqrt(l)表示l的平方根,若l<1则l= 1;第二步,设XDen左上角坐标为(1,1),从坐标(1,1)开始,根据窗口大小为l和步长s确定每 一个候选框,该候选框为[(a,b),(a l,b l)]所围成的区域,对于XDen′在候选框区域内所对 应的图像矩阵进行直方图均衡化,得到候选区域[(a,b),(a l,b l)]的均衡化后的图像矩 阵X ″,然后X ′sumDen Den 对应的[(a,b),(a l,b l)]区域的每一个元素计算X sumDen′ (a iXsum,b jXsum)=X ′sumDen (a iXsum,b jXsum) XDen″(iXsum,jXsum),其中(iXsum,jXsum)为整数且1≤iXsum≤l,1 ≤jXsum≤l,并将NvmDen对应的[(a,b),(a l,b l)]区域内的每一个元素加1;最后,计算 其中(iXsumNum,jXsumNum)为XDen对应的每一个点,从而得到Xcpst 即为对当前分量XDen′进行光照补偿。 所述的根据窗口大小为l和步长s确定每一个候选框,其步骤为: 设监控图像为m行n列,(a,b)为选定的区域的左上角坐标,(a l,b l)为选定区域 16 CN 111582202 A 说 明 书 3/26 页 的右下角坐标,该区域由[(a,b),(a l,b l)]表示,(a,b)的初始值为(1,1); 当a l≤m时: b=1; 当b l≤n时: 选定的区域为[(a,b),(a l,b l)]; b=b s; 内层循环结束; a=a s; 外层循环结束; 上述过程中,每次选定的区域[(a,b),(a l,b l)]均为候选框。 所述的对于XDen′在候选框区域内所对应的图像矩阵进行直方图均衡化,设候选框 区域为[(a,b),(a l,b l)]所围成的区域,XDen″即为XDen′在[(a,b),(a l,b l)]区域内的图 像信息,其步骤为:第一步,构造向量I,I(iI)为XDen″中像素值等于iI的个数,0≤iI≤255;第 二步,计算向量 第三步,对于XDen″上的每一个点(iXDen,jXDen),其像素值为 XDen″(iXDen,jXDen),计算X″Den(iXDen,jXDen)=I′(X″Den(iXDen,jXDen))。待XDen″图像内的所有像素 点值都计算并更改后直方图均衡化过程结束,XDen″内保存的即为直方图均衡化的结果。 所述的将光照补偿后的图像进行图像增强,设光照补偿后的图像为Xcpst,其对应 的RGB通道分别为XcpstR,XcpstG,XcpstB,对Xcpst图像增强后得到的图像为Xenh。对其进行图像增 强的步骤为:第一步,对于Xcpst的所有分量XcpstR,XcpstG,XcpstB计算其按指定尺度进行模糊后 的图像;第二步,构造矩阵LXenhR,LXenhG,LXenhB为与XcpstR相同维度的矩阵,对于图像Xcpst的 RGB通道中的R通道,计算LXenhR(i,j)=log(XcpstR(i,j))-LXcpstR(i,j),(i,j)的取值范围为 图像矩阵中所有的点,对于图像Xcpst的RGB通道中的G通道和B通道采用与R通道同样的算法 得到LXenhG和LXenhB;第三步,对于图像Xcpst的RGB通道中的R通道,计算LXenhR中所有点取值的 均值MeanR和均方差VarR(注意是均方差),计算MinR=MeanR-2×VarR和MaxR=MeanR 2× VarR,然后计算XenhR(i,j)=Fix((LXcpstR(i,j)-MinR)/(MaxR-MinR)×255),其中Fix表示取 整数部分,若取值<0则赋值为0,取值>255则赋值为255;对于RGB通道中的G通道和B通道 采用与R通道同样的算法得到XenhG和XenhB,将分别属于RGB通道的XenhR、XenhG、XenhB整合成一张 彩色图像Xenh。 所述的对于Xcpst的所有分量XcpstR,XcpstG,XcpstB计算其按指定尺度进行模糊后的图 像,对于RGB通道中的R通道XcpstR,其步骤为:第一步,定义高斯函数G(x,y,σ)=k×exp(-(x2 y2)/σ2),σ为尺度参数,k=1/∫∫G(x,y)dxdy,则对于XcpstR的每一个点XcpstR(i,j)计算, 其中 表示卷积运算,对于距离边界低于尺度σ的点,只 计算XcpstR与G(x,y,σ)对应部分的卷积,Fix( )表示取整数部分,若取值<0则赋值为0,取值 >255则赋值为255。对于RGB通道中的G通道和B通道采用与R通道同样的算法更新XcpstG和 XcpstG。 所述的目标检测模块,在初始化过程中,使用带有已标定人脸面部区域、手部区域 和上肢区域的图像对目标检测算法进行参数初始化;在检测过程中,接收图像预处理模块 17 CN 111582202 A 说 明 书 4/26 页 所传递来的图像,然后对其进行处理,对每一帧图像使用目标检测算法进行目标检测,得到 当前图像的人脸面部区域、手部区域和上肢区域,将提取到的人脸面部区域传递给人脸识 别模块和头部方向检测模块、将上肢区域和手部区域图像传递给学生动作识别模块。 所述的使用带有已标定人脸面部区域、手部区域和上肢区域的图像对目标检测算 法进行参数初始化,其步骤为:第一步,构造特征抽取深度网络;第二步,构造区域选择网 络,第三步,根据所述的构造特征抽取深度网络中所使用的数据库中的每一张图像X和对应 的人工标定的每个区域 然后通过ROI层,其输入为图像X和区域 输出 为7×7×512维度的;第 三步,构建坐标精炼网络。 所述的构造特征抽取深度网络,该网络为深度学习网络结构,其网络结构为:第一 层:卷积层,输入为768×1024×3,输出为768×1024×64,通道数channels=64;第二层:卷 积层,输入为768×1024×64,输出为768×1024×64,通道数channels=64;第三层:池化 层,输入第一层输出768×1024×64与第三层输出768×1024×64在第三个维度上相连接, 输出为384×512×128;第四层:卷积层,输入为384×512×128,输出为384×512×128,通 道数channels=128;第五层:卷积层,输入为384×512×128,输出为384×512×128,通道 数channels=128;第六层:池化层,输入第四层输出384×512×128与第五层384×512× 128在第三个维度上相连接,输出为192×256×256;第七层:卷积层,输入为192×256× 256,输出为192×256×256,通道数channels=256;第八层:卷积层,输入为192×256× 256,输出为192×256×256,通道数channels=256;第九层:卷积层,输入为192×256× 256,输出为192×256×256,通道数channels=256;第十层:池化层,输入为第七层输出192 ×256×256与第九层192×256×256在第三个维度上相连接,输出为96×128×512;第十一 层:卷积层,输入为96×128×512,输出为96×128×512,通道数channels=512;第十二层: 卷积层,输入为96×128×512,输出为96×128×512,通道数channels=512;第十三层:卷 积层,输入为96×128×512,输出为96×128×512,通道数channels=512;第十四层:池化 层,输入为第十一层输出96×128×512与第十三层96×128×512在第三个维度上相连接, 输出为48×64×1024;第十五层:卷积层,输入为48×64×1024,输出为48×64×512,通道 数channels=512;第十六层:卷积层,输入为48×64×512,输出为48×64×512,通道数 channels=512;第十七层:卷积层,输入为48×64×512,输出为48×64×512,通道数 channels=512;第十八层:池化层,输入为第十五层输出48×64×512与第十七层48×64× 512在第三个维度上相连接,输出为48×64×1024;第十九层:卷积层,输入为48×64× 1024,输出为48×64×256,通道数channels=256;第二十层:池化层,输入为48×64×256, 输出为24×62×256;第二十一层:卷积层,输入为24×32×1024,输出为24×32×256,通道 数channels=256;第二十二层:池化层,输入为24×32×256,输出为12×16×256;第二十 三层:卷积层,输入为12×16×256,输出为12×16×128,通道数channels=128;第二十四 层:池化层,输入为12×16×128,输出为6×8×128;第二十五层:全连接层,首先将输入的6 ×8×128维度的数据展开成6144维度的向量,然后输入进全连接层,输出向量长度为768, 激活函数为relu激活函数;第二十六层:全连接层,输入向量长度为768,输出向量长度为 96,激活函数为relu激活函数;第二十七层:全连接层,输入向量长度为96,输出向量长度为 2,激活函数为soft-ma×激活函数;所有卷积层的参数为卷积核kernel大小=3,步长 18 CN 111582202 A 说 明 书 5/26 页 stride=(1,1),激活函数为relu激活函数;所有池化层均为最大池化层,其参数为池化区 间大小kernel_size=2,步长stride=(2,2);设该深度网络为Fconv27,对于一幅彩色图像 X,经过该深度网络所得到的特征图集合用Fconv27(X)表示,该网络的评价函数为对 (Fconv27(X)-y)计算其交叉熵损失函数,收敛方向为取最小值,y输入对应的分类。数据库 为在自然界采集的包含人脸及非人脸的图像,每张图像为768×1024维度的彩色图像,按照 图像中是否包含人脸分成两类,迭代次数为2000次。在训练结束后,取第一层到第十七层为 特征抽取深度网络Fconv,对于一幅彩色图像X,经过该深度网络所得到的输出用Fconv(X) 表示。 所述的构造区域选择网络,接收Fconv深度网络提取出512个48×64特征图集合 Fconv(X),然后第一步经过卷积层得到Conv1(Fconv(X)),该卷积层的参数为:卷积核 kernel大小=1,步长stride=(1,1),输入为48×64×512,输出为48×64×512,通道数 channels=512;然后将Conv1(Fconv(X))分别输入到两个卷积层(Conv2-1和Cony2-2), Conv2-1的结构为:输入为48×64×512,输出为48×64×18,通道数channels=18,该层得到 的输出为Conv2-1(Conv1(Fconv(X))),再对该输出使用激活函数softmax得到softmax(Conv2-1 (Conv1(Fconv(X))));Conv2-2的结构为:输入为48×64×512,输出为48×64×36,通道数 channels=36;该网络的损失函数有两个:第一个误差函数loss1为对Wshad-cls ⊙ (Conv2-1 (Conv1(Fconv(X)))-Wcls(X))计算softmax误差,第二个误差函数loss2为对Wshad-reg(X) ⊙ (Conv2-1(Conv1(Fconv(X)))-Wreg(X))计算smooth L1误差,区域选择网络的损失函数= loss1/sum(Wcls(X)) loss2/sum(Wcls(X)),sum(·)表示矩阵所有元素之和,收敛方向为取 最小值,Wcls(X)和Wreg(X)分别为数据库图像X对应的正负样本信息,⊙ 表示矩阵按照对应位 相乘,Wshad-cls(X)和Wshad-reg(X)为掩码,其作用为选择Wshad(X)中权值为1的部分进行训练,从 而避免正负样本数量差距过大,每次迭代时重新生成Wshad-cls(X)和Wshad-reg(X),算法迭代 1000次。 所述的构造特征抽取深度网络中所使用的数据库,对于数据库中的每一张图像, 第一步:人工标定图像中的人脸面部区域、手部区域和上肢区域,设其在输入图像的中心坐 标为(abas_tr,bbas_tr),中心坐标在纵向距离上下边框的距离为lbas_tr,中心坐标在横向距离 左 右 边 框 的 距 离 为 w b a s _ t r ,则 其 对 应 于 C o n v 1 的 位 置 为 中 心 坐 标 为 半长为 半宽为 表示取整数部分;第 二步:随机生成正负样本。 所述的随机生成正负样本,其方法为:第一步,构造9个区域框,第二步,对于数据 库的每一张图像Xtr,设Wcls为48×64×18维度,Wreg为48×64×36维度,所有初始值均为0,对 Wcls和Wreg进行填充。 所述的构造9个区域框,这9个区域框分别为:Ro1(xRo,yRo)=(xRo,yRo,64,64),Ro2 (xRo,yRo)=(xRo,yRo,45,90),Ro3(xRo,yRo)=(xRo,yRo,90,45),Ro4(xRo,yRo)=(xRo,yRo,128, 128),Ro5(xRo,yRo)=(xRo,yRo,90,180),Ro6(xRo,yRo)=(xRo,yRo,180,90),Ro7(xRo,yRo)= (xRo,yRo,256,256),Ro8(xRo,yRo)=(xRo,yRo,360,180),Ro9(xRo,yRo)=(xRo,yRo,180,360),对 于每一个区域块,Roi(xRo,yRo)表示对于第i个区域框,当前区域框的中心坐标(xRo,yRo),第 三位表示中心点距离上下边框的像素距离,第四位表示中心点距离左右边框的像素距离,i 的取值从1到9。 19 CN 111582202 A 说 明 书 6/26 页 所述的对Wcls和Wreg进行填充,其方法为: 对于每一个人工标定的人体区间,设其在输入图像的中心坐标为(abas_tr,bbas_tr), 中心坐标在纵向距离上下边框的距离为lbas_tr,中心坐标在横向距离左右边框的距离为 w b a s _ t r,则其对应于Conv 1的位置为中心坐标为 半长为 半宽为 对于左上角 右下角 坐标 所围成的区间内的每个点 (xCtr,yctr): 对于i取值从1到9: 对于点(xCtr,yCtr),其在数据库图像的映射区间为左上角点(16(xCtr-1) 1,16 (yCtr-1) 1)右下角点(16xCtr,16yCtr)所围成的16×16区间,对于该区间的每一个点(xOtr, yotr): 计算(xotr,yotr)所对应区域Roi(xOtr,yotr)与当前人工标定的区间的重合率; 选择当前16×16区间内重合率最高的点(xIouMax,yIoUMax),若重合率>0.7,则Wcts (xCtr,yCtr,2i-1)=1,Wcls(xctr,yCtr,2i)=0,该样本为正样本,Wreg(xCtr,yCtr,4i-3)=(xOtr- 16xCtr 8)/8,Wreg(xCtr,yCtr,4i-2)=(yOtr-16yCtr 8)/8,Wreg(xCtr,yCtr,4i-2)=Down1(lbas_tr/ Roi的第三位),Wreg(xCtr,yctr,4i)=Down1(wbas_tr/Roi的第四位),Down1(·)表示若值大于1 则取值为1;若重合率<0.3,则Wcls(xCtr,yCtr,2i-1)=0,Wcls(xCtr,yCtr,2i)=1;否则Wcls(xCtr, yCtr,2i-1)=-1,Wcls(xCtr,yCtr,2i)=-1. 若当前人工标定的区域没有重合率>0.6的Roi(xotr,yotr),则选择重合率最高的 Roi(xOtr,yotr)对Wcls和Wreg赋值,赋值方法与重合率>0.7的赋值方法相同。 所述的计算(xOtr,yotr)所对应区域Roi(xOtr,yOtr)与当前人工标定的区间的重合 率,其方法为:设人工标定的人体区间在输入图像的中心坐标为(abas_tr,bbas_tr),中心坐标 在纵向距离上下边框的距离为lbas_tr,中心坐标在横向距离左右边框的距离为wbas_tr,设Roi (xotr,yOtr)的第三位为lotr,第四位为wOtr,若满足|xOtr-abas_tr|≤lotr lbas_tr-1并且|yOtr- bbas_tr|≤wotr wbas_tr-1,说明存在重合区域,重合区域=(lOtr lbas_tr-1-|xOtr-abas_tr|)× (wotr wbas_tr-1-|yOtr-bbas_tr|),否则重合区域=0;计算全部区域=(2lotr-1)×(2wOtr-1) (2abas_tr-1)×(2wbas_tr-1)-重合区域;从而得到重合率=重合区域/全部区域,|·|表示取 绝对值。 所述的Wshad-cls(X)和Wshad-rea(X),其构造方法为:对于该图像X,其对应的正负样本 信息为Wcls(X)和Wreg(X),第一步,构造Wshad-cls(X)与和Wshad-reg(X),Wshad-cls(X)与Wcls(X)维度 相同,Wshad-reg(X)与Wreg(X)维度相同;第二步,记录所有正样本的信息,对于i=1到9,若Wcls (X)(a,b,2i-1)=1,则Wshad-cls(X)(a,b,2i-1)=1,Wshad-cls(X)(a,b,2i)=1,Wshad-reg(X)(a, b,4i-3)=1,Wshad-reg(X)(a,b,4i-2)=1,Wshad-reg(X)(a,b,4i-1)=1,Wshad-reg(X)(a,b,4i)= 1,正样本一共选择了sum(Wshad-cls(X))个,sum(·)表示对矩阵的所有元素求和,若sum (Wshad-cls(X))>256,随机保留256个正样本;第三步,随机选择负样本,随机选择(a,b,i),若 Wcls(X)(a,b,2i-1)=1,则Wshad-cls(X)(a,b,2i-1)=1,Wshad-cls(X)(a,b,2i)=1,Wshad-reg(X) (a,b,4i-3)=1,Wshad-reg(X)(a,b,4i-2)=1,Wshad-reg(X)(a,b,4i-1)=1,Wshad-reg(X)(a,b, 20 CN 111582202 A 说 明 书 7/26 页 4i)=1,若已选中的负样本数量为256-sum(Wshad-cls(X))个,或者虽然负样本数量不足256- sum(Wshad-cls(X))个但是在20次生成随机数(a,b,i)内都无法得到负样本,则算法结束。 所述的ROI层,其输入为图像X和区域 其方法为:对于 图像X通过特征抽取深度网络Fconv所得到的输出Fconv(X)的维度为48×64×512,对于每 一个48×64矩阵VROI_I的信息(一共512个矩阵),提取VROI_I矩阵中左上角 右下角 所围成的 区域, 表示取整数部分;输出为roiI(X)维度为7×7,则步长 对于iROI=1:到7: 对于jROI=1到7: 构 造 区 间 roiI(X)(iROI,jROI)=区间内最大点的值。 当512个48×64矩阵全部处理结束后,将输出拼接得到7×7×512维度的输出 参数表示对于图像X,在区域框 范围内的ROI。 所述的构建坐标精炼网络,其方法为:第一步,扩展数据库:扩展方法为对于数据 库中的每一张图像X和对应的人工标定的每个区域 其对应的 ROI为 若当前区间为人体图像区域则BClass=[1,0,0, 0,0],BBox=[0,0,0,0],若当前区间为人脸面部区域则BClass=[0,1,0,0,0],BBox=[0, 0,0,0],若当前区间为手部区域则BClass=[0,0,1,0,0],BBox=[0,0,0,0],若当前区间为 产品区域则BClass=[0,0,0,1,0],BBox=[0,0,0,0];随机生成取值在-1到1之间随机数 arand,brand,lrand,wrand,从而得到新的区间 表示取整数部分,该区间的BBox=[arand,brand, lrand,wrand],若新的区间与 的重合率>0.7则BClass=当前区域 的BClass,若新的区间与 的重合率<0.3,则BClass=[0,0,0,0, 1],二者均不满足,则不赋值。每个区间最多生成10个正样本区域,设生成Num1个正样本区 域,则生成Num1 1个负样本区域,若负样本区域不够Num1 1个,则扩大arand,brand,lrand,wrand 的范围,直到找到足够多的负样本数为止。第二步,构建坐标精炼网路:对于数据库中的每 一张图像X和对应的人工标定的每个区域 其对应的ROI为 将将7×7×512维度的ROI展开成25088维向量,然后经 过两个全连接层Fc2,得到输出Fc2(ROI),然后将Fc2(ROI)分别通过分类层FClass和区间微 调层FBBox,得到输出FClass(Fc2(ROI))和FBBox(Fc2(ROI)),分类层FClass为全连接层,其 输入向量长度为512,输出向量长度为4,区间微调层FBBox为全连接层,其输入向量长度为 512,输出向量长度为4;该网络的损失函数有两个:第一个误差函数loss1为对FClass(Fc2 21 CN 111582202 A 说 明 书 8/26 页 (ROI))-BClass计算softmax误差,第二个误差函数loss2为对(FBBox(Fc2(ROI))-BBox)计 算欧氏距离误差,则该精炼网络的整体损失函数=loss1 loss2,算法迭代过程为:首先迭 代1000次收敛误差函数loss2,然后迭代1000次收敛整体损失函数。 所述的两个全连接层Fc2,其结构为:第一层:全连接层,输入向量长度为25088,输 出向量长度为4096,激活函数为relu激活函数;第二层:全连接层,输入向量长度为4096,输 出向量长度为512,激活函数为relu激活函数。 所述的对每一帧图像使用目标检测算法进行目标检测,得到当前图像的人脸面部 区域、手部区域和上肢区域,其步骤为: 第一步,将输入图像Xcpst分割成768×1024维度的子图; 第二步,对于每一个子图Xs: 第2.1步,使用在初始化时构造的特征抽取深度网络Fconv进行变换,得到512个特 征子图集合Fconv(Xs); 第2.2步,对Fconv(Xs)使用区域选择网络中第一层Conv1、第二层Conv2-1 softmax 激活函数和Conv2-2进变换,分别得到输出softmax(Conv2-1(Conv1(Fconv(Xs))))和Conv2-2 (Conv1(Fconv(Xs))),然后根据输出值得到该区间内的所有的初步候选区间; 第2.3步,对于当前帧图像的所有子图的所有的初步候选区间: 第2.3.1步,根据其当前候选区域的得分大小进行选取,选取最大的50个初步候选 区间作为候选区域; 第2.3.2步,调整候选区间集合中所有的越界候选区间,然后剔除掉候选区间中重 叠的框,从而得到最终候选区间; 第2.3.3步,将子图Xs和每一个最终候选区间输入到ROI层,得到对应的ROI输出, 设当前的最终候选区间为(aBB(1),bBB(2),lBB(3),wBB(4)),然后计算FBBox(Fc2(ROI))得到 四位输出(OutBB(1),OutBB(2),OutBB(3),OutBB(4))从而得到更新后的坐标(aBB(1) 8×OutBB (1),bBB(2) 8×OutBB(2),lBB(3) 8×OutBB(3),wBB(4) 8×OutBB(4));然后计算FClass(Fc2 (ROI))得到输出,若输出第一位最大则当前区间为人脸面部区域,若输出第二位最大则当 前区间为手部区域,若输出第三位最大则当前区间为上肢区域,若输出第四位最大则当前 区间为负样本区域并删除该最终候选区间。 第三步,更新所有子图的精炼后的最终候选区间的坐标,更新的方法为设当前候 选区域的坐标为(TLx,TLy,RBx,RBy),其对应的子图的左上角坐标为(Seasub,Sebsub),更新 后的坐标为(TLx Seasub-1,TLy Sebsub-1,RBx,RBy)。 所述的将输入图像Xcpst分割成768×1024维度的子图,其步骤为:设分割的步长为 384和512,设窗口大小为m行n列,(asub,bsub)为选定的区域的左上角坐标,(a,b)的初始值为 (1,1);当asub<m时: bsub=1; 当bsub<n时: 选定的区域为[(asub,bsub),(asub 384,bsub 512)],将输入图像Xcpst上该区间所对 应的图像区域的信息复制到新的子图中,并附带左上角坐标(asub,bsub)作为位置信息;若选 定区域超出输入图像Xcpst区间,则将超出范围内的像素点对应的RGB像素值均赋值为0; bsub=bsub 512; 22 CN 111582202 A 说 明 书 9/26 页 内层循环结束; asub=asub 384; 外层循环结束; 所述的根据输出值得到该区间内的所有的初步候选区间,其方法为:第一步:对于 softmax(Conv2-1(Conv1(Fconv(Xs))))其输出为48×64×18,对于Conv2-2(Conv1(FConv (Xs))),其输出为48×64×36,对于48×64维空间上的任何一点(x,y),softmax(Conv2-1 (Conv1(Fconv(Xs))))(x,y)为18维向量II,Conv2-2(Conv1(Fconv(Xs)))(x,y)为36维向量 IIII,若II(2i-1)>II(2i),对于i取值从1到9,lOtr为Roi(xOtr,yOtr)的第三位,wOtr为Roi (xOtr,yOtr)的第四位,则初步候选区间为[II(2i-1),(8×IIII(4i-3) x,8×IIII(4i-2) y, lOtr×IIII(4i-1),wOtr×IIII(4i))],其中第一位II(2i-1)表示当前候选区域的得分,第二 位(8×IIII(4i-3) x,8×IIII(4i-2) y,IIII(4i-1),IIII(4i))表示当前候选区间的中心 点为(8×IIII(4i-3) x,8×IIII(4i-2) y),候选框的半长半宽分别为lotr×IIII(4i-1)和 wOtr×IIII(4i))。 所述的调整候选区间集合中所有的越界候选区间,其方法为:设监控图像为m行n 列,对于每一个候选区间,设其[(ach,bch)],候选框的半长半宽分别为lch和wch,若ach lch> m,则 然后更新其ach=a′ch,lch= l′ch;若bch wch>n,则 然后更新 其bch=b′ch,wch=w′ch· 所述的剔除掉候选区间中重叠的框,其步骤为: 若候选区间集合不为空: 从候选区间集合中取出得分最大的候选区间iout: 计算候选区间iout与候选区间集合中的每一个候选区间ic的重合率,若重合率> 0.7, 则从候选区间集合删除候选区间ic; 将候选区间iout放入输出候选区间集合; 当候选区间集合为空时,输出候选区间集合内所含的候选区间即为剔除掉候选区 间中重叠的框后所得到的候选区间集合。 所述的计算候选区间iout与候选区间集合中的每一个候选区间ic的重合率,其方 法为:设候选区间ic的坐标区间为中心点[(aic,bic)],候选框的半长半宽分别为lic和wic,候 选区间ic的坐标区间为中心点[(aiout,bicout)],候选框的半长半宽分别为liout和wiout;计算 xA=max(aic,aiout);yA=max(bic,biout);xB=min(lic,liout),yB=min(wic,wiout);若满足| aic-aiout|≤lic liout-1并且|bic-biout|≤wic wiout-1,说明存在重合区域,重合区域=(lic liout-1-|aic-aiout|)×(wic wiout-1-|bic-biout|),否则重合区域=0;计算全部区域=(2lic- 1)×(2wic-1) (2liout-1)×(2wiout-1)-重合区域;从而得到重合率=重合区域/全部区域。 所述的人脸识别模块,其方法是:在初始化阶段,首先构造通用图像特征提取网络 N1,然后保留深度网络N1的第一层到第二十三层,删掉第二十三层的激活函数,该深度网络 FaceNet作为人脸图像特征提取网络,然后,读取学生在系统上登记的照片,使用初始化阶 段构造人脸图像特征提取网络FaceNet对人脸图像进行特征提取,对于登记照片P,将P作为 特征提取网络FaceNet的输入,得到对应的1000维度输出FaceNet(P)。在检测过程中,接受 23 CN 111582202 A 说 明 书 10/26 页 目标检测模块传递过来的人脸图像,然后判断人脸识别标签,若人脸识别标签为不识别,则 跳过当前人脸图像;若人脸识别标签为识别,则对当前人脸图像进行识别,将识别结果发送 给识别结果处理模块;若人脸识别标签为识别,但目标检测模块未传递过来人脸图像,将识 别结果设为不通过,并发送给识别结果处理模块。 所述的构造通用图像特征提取网络N1,方法是:第一步,构建深度网络N1;第二步 使用ILSVRC-2012国际标准数据库对深度网络N1进行训练。 所述的构建深度网络N1,其网络结构为:第一层:卷积层,输入为224×224×3,输 出为224×224×64,通道数channels=64;第二层:卷积层,输入为224×224×64,输出为 224×224×64,通道数channels=64;第三层:池化层,输入224×224×64,输出112×112× 64;第四层:卷积层,输入为112×112×64,输出为112×112×128,通道数channels=128; 第五层:卷积层,输入为112×112×128,输出为112×112×128,通道数channels=128;第 六层:池化层,输入112×112×128,输出为56×56×128;第七层:卷积层,输入为56×56× 128,输出为56×56×256,通道数channels=256;第八层:卷积层,输入为56×56×256,输 出为56×56×256,通道数channels=256;第九层:卷积层,输入为56×56×256,输出为56 ×56×256,通道数channels=256;第十层:池化层,输入为56×56×256,输出为28×28× 256;第十一层:卷积层,输入为28×28×256,输出为28×28×512,通道数channels=512; 第十二层:卷积层,输入为28×28×512,输出为28×28×512,通道数channels=512;第十 三层:卷积层,输入为28×28×512,输出为28×28×512,通道数channels=512;第十四层: 池化层,输入为28×28×512,输出为14×14×512;第十五层:卷积层,输入为14×14×512, 输出为14×14×512,通道数channels=512;第十六层:卷积层,输入为14×14×512,输出 为14×14×512,通道数channels=512;第十七层:卷积层,输入为14×14×512,输出为14 ×14×512,通道数channels=512;第十八层:池化层,输入为14×14×512,输出为7×7× 512;第十九层:首先将输入的7×7×512的数据展开成25,088维度的向量,然后输入进全连 接层,输出向量长度为4096,激活函数为relu激活函数;第二十层:Dropout层,概率为0.5; 第二十一层:全连接层,输入向量长度为4096,输出向量长度为4096,激活函数为relu激活 函数;第二十二层:Dropout层,概率为0.5;第二十三层:全连接层,输入向量长度为4096,输 出向量长度为1000,激活函数为soft-max激活函数;所有卷积层的参数为:卷积核kernel大 小=3,步长stride=(1,1),激活函数为relu激活函数;所有池化层均为最大池化层,其参 数为池化区间大小kernel_size=2,步长stride=(2,2)。 所述的使用ILSVRC-2012国际标准图像分类数据库对深度网络N1进行训练,其步 骤为:首先对输入图像进行处理,因为ILSVRC-2012国际标准数据库的输入为高清图像,对 于每一张图像按照最短边不变,最长以中心为基准截取一个正方形区域,然后将图像大小 调整为224×224,图像大小调整采用双线性插值法,得到的224×224×3的彩色图像X作为 输入,对于数据集中1000个类,构造一个1000维度的向量Y,若当前图像属于1000类中的第K 类,则向量的第K位等于1,其他位等于0,处理好的数据对











