
技术摘要:
本发明公开了一种定向定量的互联网数据采集方法及系统,属于大数据应用与分析领域,本发明要解决的技术问题为如何避免因为采集范围大而造成的采集用时长、资源节点占用量大、目标数量漏采,采用的技术方案为:该方法是通过自定义的数据显示上限和偏移值对网站发送检索 全部
背景技术:
现在的社会是一个高速发展的社会,随着计算机和信息技术的迅猛发展和普及应 用,行业应用系统的规模迅速扩大,行业应用所产生的数据呈爆炸性增长,人们愈加认识到 数据的重要性,数据这一概念已经引起了各行业从业者与用户的广泛关注。对于海量数据 的挖掘和运用,预示着新一波生产率增长和消费者盈余浪潮的到来。而随着政府信息公开 与企业数字化发展,大量有价值的数据都可以通过对互联网数据的采集来获取。 传统的数据采集技术一般不涉及对网站访问请求的人为变更,即不会根据采集需 求人为修改请求访问参数,通常都是根据网站页面的默认显示形式去遍历网站进而获取全 量目标数据。 由于目前各大网站的内容不断扩展、数据总量不断增大,按网站默认显示形式发 送请求获取响应数据所需的发送次数大幅增长。放任采集程序按照既定的显示参数从网站 提取全量目标数据,所需的采集用时、资源节点、处理加工等数据采集成本也随之大幅上 升。故在互联网数据采集过程中,如何避免因为采集范围大而造成的采集用时长、资源节点 占用量大、目标数量漏采是目前亟待解决的问题。 专利号为CN108804620A的专利文献公开了一种互联网数据采集方法、系统及计算 机终端。该方法包括:S1从所述待采集列表中获取待采集对象,根据预设规则构造该待采集 对象的访问链接;S2根据所述访问链接获取所述待采集对象的网页内容,对所述网页内容 进行解析以获取包含所述待采集对象的相关对象的有用信息,存储所述有用信息及将所述 待采集对象加入已采集列表中;S3判断所述相关对象是否在待采集列表或已采集列表中, 若均不存在,将所述相关对象加入到待采集列表中,重新执行步骤S1及后续步骤直至所述 待采集列表内所有对象的有用信息采集完毕。该技术方案解决了如何通过一个访问链接发 现新的价值链接的情况,实现互联网数据采集的自动化及全面化,但是不能解决因为采集 范围大而造成的采集用时长、资源节点占用量大、目标数量漏采的问题。
技术实现要素:
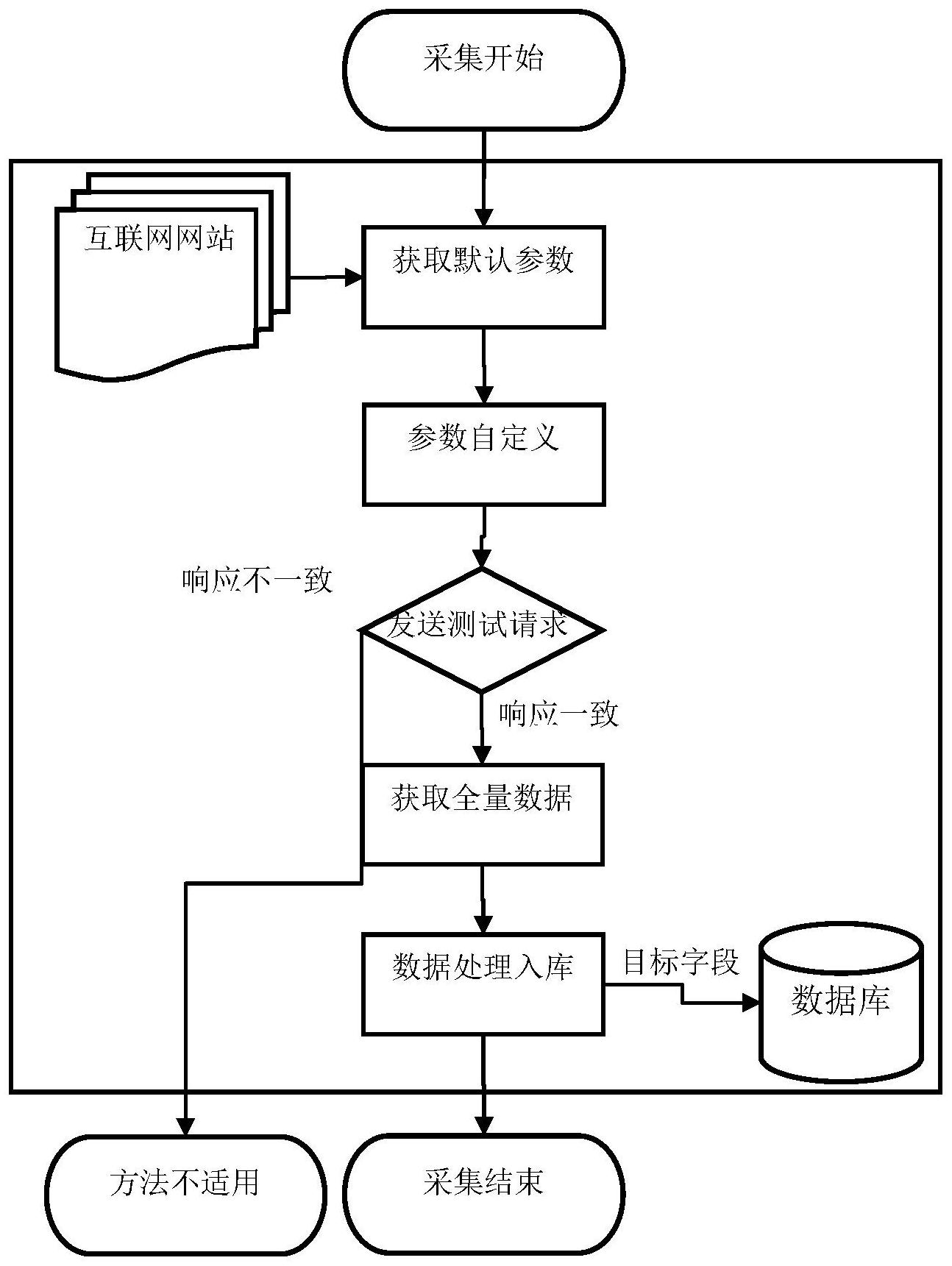
本发明的技术任务是提供一种定向定量的互联网数据采集方法及系统,来解决如 何避免因为采集范围大而造成的采集用时长、资源节点占用量大、目标数量漏采的问题。 本发明的技术任务是按以下方式实现的,一种定向定量的互联网数据采集方法, 该方法是通过自定义的数据显示上限和偏移值对网站发送检索请求,得到相关联的定制化 检索结果,经由一次或少次请求遍历获取全量数据,再将得到检索结果合并后做结构化处 理,保存入库达到数据采集的目的。 作为优选,该方法具体如下: 4 CN 111723268 A 说 明 书 2/5 页 S1、获取默认参数:通过浏览器开发工具或数据采集工具对向目标网站发送的检 索请求或翻页请求进行拦截,获取包括每页显示上限和当前页数(即偏移值)在内的各个请 求参数名称和值; S2、参数自定义:根据网站的目标数据总量,人为调整增大显示上限的数值并设定 合理的偏移量,将全量数据分割为小于网站总页数的数块; S3、发送测试请求:自定义的数据显示上限和偏移值后,发送1次请求并获取网站 响应数据,与网站对应偏移量的网页数据作对比,判断两者是否符合: ①、若是,则说明该方法有效,能够发送定量定向请求,执行步骤S4; ②、若不是,则说明不适用于该网站; S4、获取全量数据:依次发送步骤S2中自定义的显示上限和不同偏移量对应的请 求,获取每次请求的响应数据,从而得到全量目标数据; S5、数据处理入库:对步骤S4获取的全量数据进行数据处理,存入数据库,完成数 据采集。其中,数据处理采用的是现有技术常用的分类、回归、聚类、相似匹配、数据压缩等 数据处理方法。 更优地,所述自定义的数据显示上限和偏移值是指用于网站检索的请求参数与需 要采集的网站数据的显示形式有相关含义的数字;其中,自定义的数据显示上限的值大于 网站默认值。 作为优选,所述相关联的定制化检索结果指的是与自定义的数据显示上限和偏移 值相符的响应数据。 更优地,所述经由一次或少次请求遍历获取全量数据是指获取网站公示的全量数 据所需发送的访问请求次数仅需1次或小于网站默认显示的总页数的次数。 更优地,所述偏移量的最大值与每页显示上限的值的乘积小于等于目标数据总 量。 一种定向定量的互联网数据采集系统,该系统包括, 默认参数获取模块,用于通过浏览器开发工具或数据采集工具对向目标网站发送 的检索请求或翻页请求进行拦截,获取包括每页显示上限和当前页数(即偏移值)在内的各 个请求参数名称和值; 参数自定义模块,用于根据网站的目标数据总量,人为调整增大显示上限的数值 并设定合理的偏移量,将全量数据分割为小于网站总页数的数块; 测试请求发送模块,用于自定义的数据显示上限和偏移值后,发送1次请求并获取 网站响应数据,与网站对应偏移量的网页数据作对比,判断两者是否符合; 全量数据获取模块,用于依次发送参数自定义模块中自定义的显示上限和不同偏 移量对应的请求,获取每次请求的响应数据,从而得到全量目标数据; 数据处理入库模块,用于对全量数据获取模块中获取的全量数据进行数据处理, 存入数据库,完成数据采集。 作为优选,所述自定义的数据显示上限和偏移值是指用于网站检索的请求参数与 需要采集的网站数据的显示形式有相关含义的数字;其中,自定义的数据显示上限的值大 于网站默认值; 偏移量的最大值与每页显示上限的值的乘积小于等于目标数据总量。 5 CN 111723268 A 说 明 书 3/5 页 一种电子设备,包括:存储器和至少一个处理器; 其中,所述存储器存储计算机执行指令; 所述至少一个处理器执行所述存储器存储的计算机执行指令,使得所述至少一个 处理器执行如上述的定向定量的互联网数据采集方法。 一种计算机可读存储介质,所述计算机可读存储介质中存储有计算机执行指令, 当处理器执行所述计算机执行时,实现如上述的定向定量的互联网数据采集方法。 本发明的定向定量的互联网数据采集方法及系统具有以下优点: (一)本发明通过对目标网站的公开数据发送指定显示上限和偏移值的访问请求, 实现了定量定向抓取,经由一次(或少次)请求获取全量数据,提高了互联网数据的利用效 率;同时有利于爬虫程序开发人员在数据采集方面节省精力,降低研发成本,同时也为后续 的数据存储和数据分析等工作提供便利; (二)本发明对爬虫程序每次请求的数据显示上限和偏移值加以调整,通过设定大 于网站默认显示条数的显示上限数值和相应的偏移值,对网站数据进行定量定向采集,从 而经由一次或少次请求,遍历获取全量数据,解决了互联网数据采集过程中,由于采集范围 大而造成的采集用时长、资源节点占用量大、目标数据漏采的问题; (三)本发明脱离了网站自身的数据显示形式的限制,可以指定检索范围,从而定 量定向的抓取网站目标数据,使访问请求更少,采集用时更短,占用采集节点更少,避免数 据漏采,快速高效的数据采集,也为后续数据存储和数据分析降低成本。 附图说明 下面结合附图对本发明进一步说明。 附图1为定向定量的互联网数据采集方法的流程框图。











