
技术摘要:
本发明公开了一种基于集成学习模型的轨道交通车载数据预测方法,首先收集轨道交通车载数据,并分为训练集和测试集,确定若干备选基模型,分别采用训练集进行训练,然后采用测试集进行测试,通过准确度和差异度进行备选基模型筛选,对保留的备选基模型再进行联合筛选, 全部
背景技术:
轨道交通出行日益成为城市生活必不可少的一部分,列车以及线路上分布着成百 上千个传感器来监测列车运行中的各项数据,这些数据单纯靠人工分析来判断列车出现故 障、列车车门与屏蔽门间隔距离较大的原因工作量巨大。特别是列车停车间隔距离,若车门 与外面屏蔽门之间的距离过大,轻则影响乘客乘车体验,严重的会导致乘客无法轻松地进 入车厢,列车需要重新制动进行调整。 现有很多基于集成学习方法的轨道交通数据分析的案例很多,集成学习的基本思 想是“三个臭皮匠赛过诸葛亮”,将若干个弱学习器(下文均称为基模型)集成在一起从而取 得比单个模型更好的预测效果。集成学习主要分为两个阶段:基模型的质量评估和模型集 成策略。 模型质量的评估不仅仅需要考虑模型预测精准度,各个基模型之间的差异性也必 须考虑进去,这是因为如果所有模型之间没有任何差异性,那么将这些模型集成在一起没 有任何意义。这就像在就某个问题就像讨论一样,如果在场的所有人意见高度的一致,那就 没有任何研究的意义了,因此也需要设计相关策略来衡量各个基模型之间的差异性。模型 的集成策略对于分类问题而言大多采取投票的方式,票数最多的分类即为样本最终的类 别;对于回归问题来说,现有的方法大多基于取平均的方式。这样做的缺点是并没有考虑基 模型之间的重要性不同,对于比较重要的基模型其对应的权重应该大于其他基模型的权 重。因此,也应该设计更加合理的模型集成策略,使得“相对重要”的基模型有更有“决定 权”。
技术实现要素:
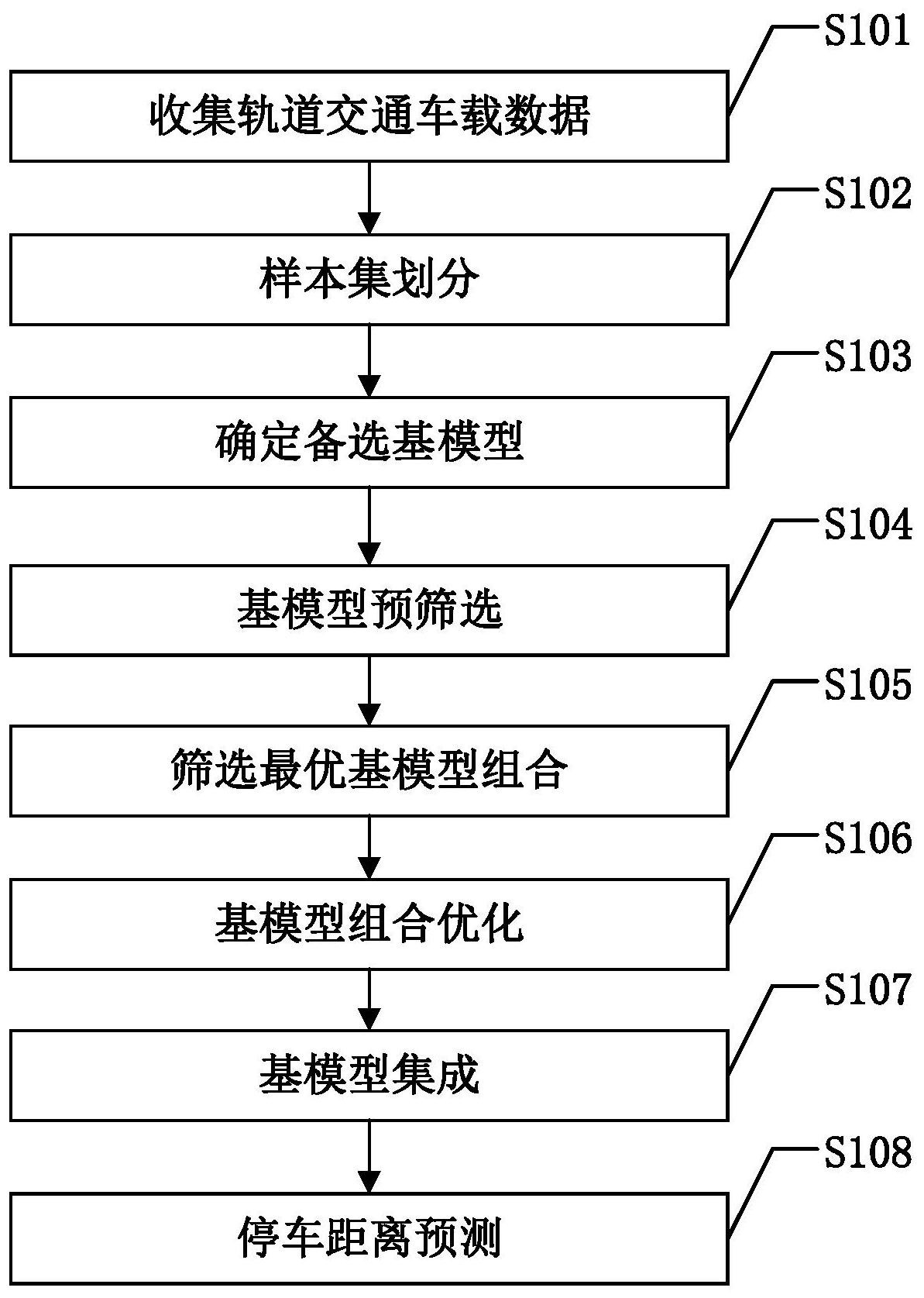
本发明的目的在于克服现有技术的不足,提供一种基于集成学习模型的轨道交通 车载数据预测方法,筛选出适宜的基模型集成得到集成学习模型,提高对停车距离的预测 精度。 为了实现上述发明目的,本发明基于集成学习模型的轨道交通车载数据预测方法 包括以下步骤: S1:根据实际需要设置M个轨道交通的车载数据特征,在轨道交通实际运行过程中 收集N次停车时M个车载数据特征的值,将每次停车时所得到的M个车载数据特征构建为一 条车载数据,同时记录停车完成时列车车门与屏蔽门之间的距离,将其作为对应车载数据 的标签,每条车载数据及其标签作为一个样本; S2:将步骤S1所得到的N个样本划分为两个集合,分别作为训练集和测试集; S3:根据实际需要确定P个备选基模型,将车载数据作为输入,停车距离作为输出, 5 CN 111612260 A 说 明 书 2/10 页 采用S2中所得到的训练集分别对每个备选基模型进行训练,在车载数据输入时,需要将车 载数据转化为备选基模型规定的输入格式,将训练完毕的P个备选基模型构成基模型候选 集; S4:分别采用步骤S2中测试集对每个备选基模型进行测试,统计每个备选基模型 的准确度,将准确度低于预设准确度阈值的备选基模型从基模型候选集中删除,然后两两 计算备选基模型之间的差异度,当两个备选基模型的差异度小于预设阈值时,从基模型候 选集中删除其中准确度较低的备选基模型,否则不作任何操作; S5:从步骤S4得到的基模型候选集提取所有基模型组合,每个基模型组合中包含Q 个基模型,然后计算每个基模型组合评价指标,选择评价指标最小的基模型组合作为最优 基模型组合,每个基模型组合的评价指标L的计算公式如下: 其中,Aq表示该基模型组合中第q个基模型的准确度,R表示该基模型组合中Q个基 模型综合差异度,α表示权重参数; S6:对于步骤S5得到的最优基模型组合中的每个基模型,分别判断第q个基模型是 否满足以下公式: 其中,Corij表示第i个基模型和第j个基模型在车载数据分布上的相关性,Coriq表 示第i个基模型和第q个基模型在车载数据分布上的相关性,eq表示第q个基模型在车载数 据分布上的误差; 如果不满足,则不作任何操作,如果满足则将第q个基模型剔除出最优基模型组 合,记优化后最优基模型组合中的基模型数量为K; S7:根据需要分别设置K个基模型的权重ωk,将步骤S6得到的K个基模型集成得到 集成学习模型; S8:在轨道交通运行过程中,采集当前M个车载数据特征的值,将其输入集成学习 模型,得到停车距离的预测结果。 本发明基于集成学习模型的轨道交通车载数据预测方法,首先收集轨道交通车载 数据,并分为训练集和测试集,确定若干备选基模型,分别采用训练集进行训练,然后采用 测试集进行测试,通过准确度和差异度进行备选基模型筛选,对保留的备选基模型再进行 联合筛选,将最终筛选得到的基模型集成得到集成学习模型,采集轨道交通实际运行过程 中的车载数据输入集成学习模型,得到停车距离的预测结果。 本发明综合考虑基模型的准确度和差异度进行基模型的初步筛选,进一步通过基 模型构建集成学习模型的效果进行基模型的联合筛选,从而使得到的集成学习模型更加合 理,并且可以通过所提出的基模型权重设置方法,进一步提高集成学习模型的性能,从而提 高对停车距离的预测精度。 6 CN 111612260 A 说 明 书 3/10 页 附图说明 图1是本发明基于集成学习模型的轨道交通车载数据预测方法的











