
技术摘要:
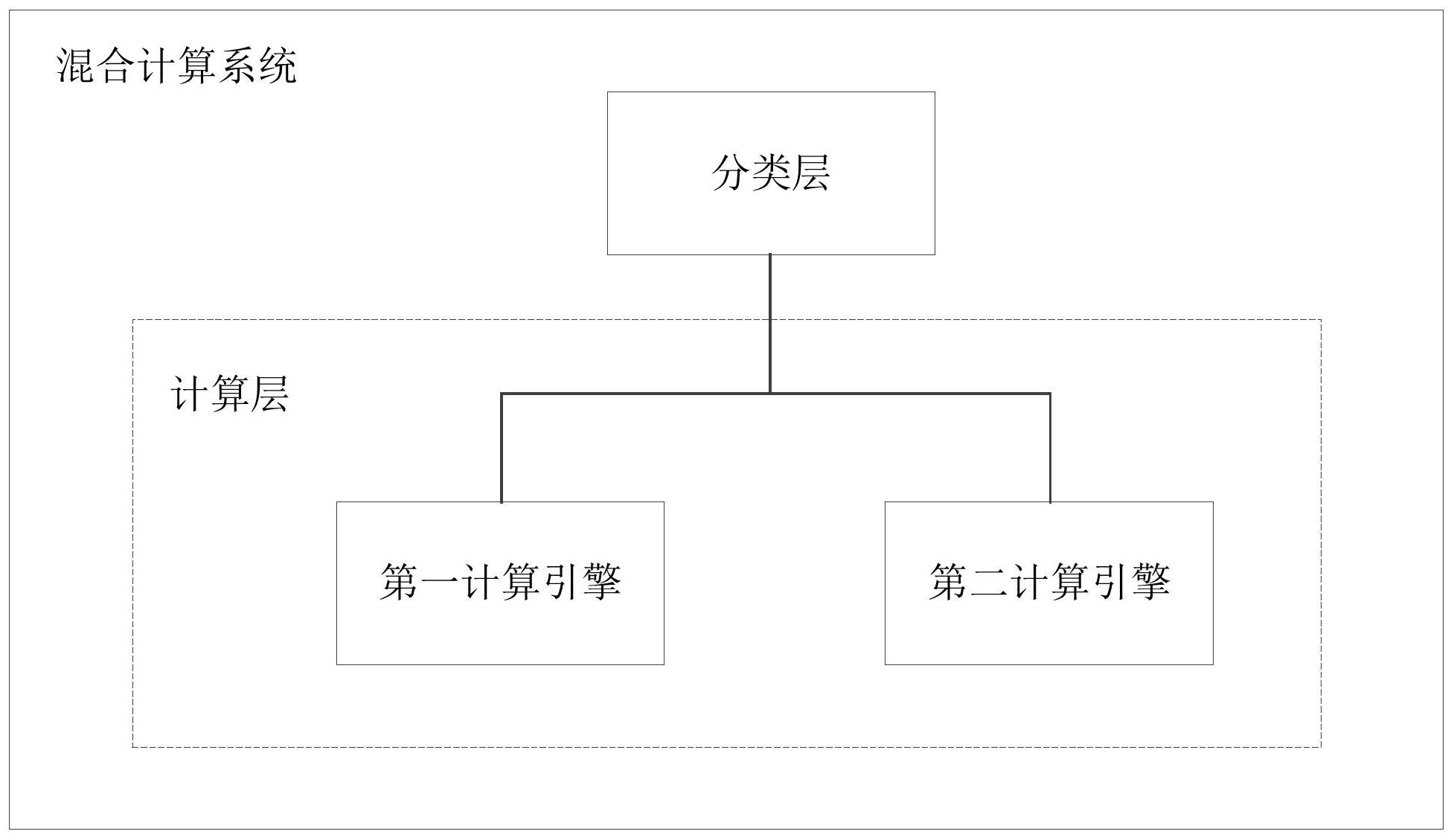
本发明实施例提供一种混合计算系统、数据处理方法及装置,该混合计算系统包括分类层和计算层,计算层包括基于批处理的第一计算引擎和基于流处理的第二计算引擎;分类层用于根据计算任务对应的第一代码,获取计算任务的特征,并根据所述特征确定目标计算引擎;分类层还 全部
背景技术:
目前,大数据处理框架包括基于批处理的计算框架和基于流处理的计算框架。其 中,基于批处理的计算框架中,以Apache Hadoop生态圈中MapReduce最典型;基于流处理的 计算框架中,最典型的是Apache Storm和Samza。 批处理适用于操作大容量历史数据集,并在计算过程完成后返回结果,其优势是 大规模吞吐量,缺点为高延迟;而流处理无需针对整个数据集执行操作,而是对每个数据项 执行操作,适用于对实时数据的处理,流处理可以做到低时延,但是数据不够准确。 然而,各类计算任务对于吞吐量、时延和数据准确性的需求是不同的,目前基于批 处理的计算框架和基于流处理的计算框架,均无法适用于各类计算任务。
技术实现要素:
本发明实施例提供一种混合计算系统、数据处理方法及装置,能够适用于各类计 算任务。 第一方面,本发明实施例提供一种混合计算系统,包括:分类层和计算层,所述计 算层包括基于批处理的第一计算引擎和基于流处理的第二计算引擎; 所述分类层用于根据计算任务对应的第一代码,获取所述计算任务的特征,并根 据所述特征确定目标计算引擎,所述目标计算引擎为所述第一计算引擎或者所述第二计算 引擎; 所述分类层还用于将所述第一代码转换为与所述目标计算引擎对应的第二代码, 并将所述第二代码发送给所述目标计算引擎,以使所述目标计算引擎执行所述计算任务以 对待处理数据进行处理。 可选的,所述计算任务的特征包括下述中的至少一项:所述第一代码的时间复杂 度、所述第一代码的空间复杂度、所述待处理数据的信息。 可选的,所述第一计算引擎为Apache Spark,所述第二计算引擎为Apache Flink。 可选的,所述混合计算系统还包括: 存储层,用于分布式存储所述待处理数据。 可选的,所述存储层包括分布式文件存储系统HDFS和分布式内存存储系统 Alluxio。 可选的,所述混合计算系统还包括: 资源管理层,用于对所述第一计算引擎和所述第二计算引擎执行所述计算任务所 需的资源进行管理和调度。 可选的,所述资源管理层包括Yarn资源管理系统。 4 CN 111611221 A 说 明 书 2/9 页 可选的,所述混合计算系统还包括: 输入层,用于获取所述计算任务对应的第一代码。 第二方面,本发明实施例提供一种数据处理方法,包括: 根据计算任务对应的第一代码,获取所述计算任务的特征,并根据所述特征确定 目标计算引擎,所述目标计算引擎为所述第一计算引擎或者所述第二计算引擎,所述第一 计算引擎用于批处理,所述第二计算引擎用于流处理; 将所述第一代码转换为与所述目标计算引擎对应的第二代码,并将所述第二代码 发送给所述目标计算引擎,以使所述目标计算引擎执行所述计算任务以对待处理数据进行 处理。 可选的,所述计算任务的特征包括下述中的至少一项:所述第一代码的时间复杂 度、所述第一代码的空间复杂度、所述待处理数据的信息。 可选的,所述第一计算引擎为Apache Spark,所述第二计算引擎为Apache Flink。 第三方面,本发明实施例提供一种数据处理装置,包括: 选择模块,用于根据计算任务对应的第一代码,获取所述计算任务的特征,并根据 所述特征确定目标计算引擎,所述目标计算引擎为所述第一计算引擎或者所述第二计算引 擎,所述第一计算引擎用于批处理,所述第二计算引擎用于流处理; 发送模块,用于将所述第一代码转换为与所述目标计算引擎对应的第二代码,并 将所述第二代码发送给所述目标计算引擎,以使所述目标计算引擎执行所述计算任务以对 待处理数据进行处理。 可选的,所述计算任务的特征包括下述中的至少一项:所述第一代码的时间复杂 度、所述第一代码的空间复杂度、所述待处理数据的信息。 可选的,所述第一计算引擎为Apache Spark,所述第二计算引擎为Apache Flink。 第四方面,本发明实施例提供一种数据处理装置,包括:至少一个处理器和存储 器; 所述存储器存储计算机执行指令; 所述至少一个处理器执行所述存储器存储的计算机执行指令,使得所述至少一个 处理器执行如第二方面任一项所述的方法。 第五方面,本发明实施例提供一种计算机可读存储介质,所述计算机可读存储介 质中存储有计算机执行指令,当处理器执行所述计算机执行指令时,实现如第二方面任一 项所述的方法。 本发明实施例提供的混合计算系统、数据处理方法及装置,该混合计算系统包括 分类层和计算层,所述计算层包括基于批处理的第一计算引擎和基于流处理的第二计算引 擎;所述分类层用于根据计算任务对应的第一代码,获取所述计算任务的特征,并根据所述 特征确定目标计算引擎,所述目标计算引擎为所述第一计算引擎或者所述第二计算引擎; 所述分类层还用于将所述第一代码转换为与所述目标计算引擎对应的第二代码,并将所述 第二代码发送给所述目标计算引擎,以使所述目标计算引擎执行所述计算任务以对待处理 数据进行处理;通过在混合计算系统中包括基于批处理的第一计算引擎和基于流处理的第 二计算引擎,使得混合计算系统既适合执行批处理任务,也适合执行流处理任务,提高了混 合计算系统的适用性;根据计算任务的特征,自动将计算任务发送给适合执行该计算任务 5 CN 111611221 A 说 明 书 3/9 页 的目标计算引擎,保证了计算任务的各项需求得以满足。 附图说明 为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例或现 有技术描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本 发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动性的前提下,还可 以根据这些附图获得其他的附图。 图1为本发明实施例提供的混合计算系统的结构示意图一; 图2为本发明实施例提供的混合计算系统的结构示意图二; 图3为图2所示的混合计算系统的数据处理过程示意图; 图4为本发明实施例提供的数据处理方法的流程示意图; 图5为本发明实施例提供的数据处理装置的结构示意图一; 图6为本发明实施例提供的数据处理装置的结构示意图二。











