
技术摘要:
本发明公开了一种基于任务指导的轻量级人脸检测方法,先将训练集进行数据增广,通过轻量级骨干网络在有限尺度空间内尽量保持原有特征,接着利用特征整合模块实现双分支架构且精简计算,再引入关联锚点辅助预测,以半监督方式生成人脸周边的头部、身体信息,最后应用任 全部
背景技术:
当计算机在工业生产、监管等方面逐渐普及,智能化设备内含的算法程序便成为 了目前的研究重点。其中,目标检测因其广泛的应用场景是计算机视觉领域内当之无愧的 最重要的分支,专注于从数字图像中检测出特定类(如人类、动物或汽车等)的可视化对象 实例。人脸检测是目标检测领域里经典的二分类问题,即从图像中辨别出人脸、背景,并给 出目标人脸所外接的矩形框的具体位置坐标。人脸检测利用机器去处理和分析海量图像、 视频所包含的有效信息,在隐私保护、安防监控、社会管理等方面取得了突破性的进展,具 体应用如3D人脸识别解锁手机、嫌犯追踪、刷脸验证和支付等。 随着深度学习的飞速发展,基于卷积神经网络的人脸检测方法以其强大的表征学 习与非线性建模能力逐步取代了传统的人工模板匹配方法,通过自主习得面部特征,显著 地提升了检测精度。目前多种人脸检测方法相继被提出,在公认的人脸检测基准上的精度 均达到了领先水平,其模型大小基本都在百兆量级上,这些方法显然是想通过构建更加复 杂的模型、引入更加全面的参数去提高准确率。 然而,当人脸检测被应用于边缘与终端设备上,如移动手机端或嵌入式结构,甚至 摄像头内部时,这些设备受限于计算能力和内存大小,完全无法承载模型大小在百兆量级 上的一些目前最先进的人脸检测方法。这些方法在公认的人脸检测基准上仅存在微小的性 能数值差异,在实际应用中也很难被察觉,故而提高人脸检测在边缘与终端设备上的实时 性尤为关键,这样才能在真正意义上实现工业级的落地标准。 实时性对网络模型的推理速度提出要求,意味着其模型结构、参数计算等方面务 必精简,这在一定意义上也限制了特征提取的充分性,对检测精度的影响较大,因此在实际 应用场景下,具备实时性的轻量级人脸检测方法仍然具有较大的准确率提升空间。而现有 技术中尚无适用于边缘与终端设备,且能够在实时性和准确率中取得较好平衡的人脸检测 方法。
技术实现要素:
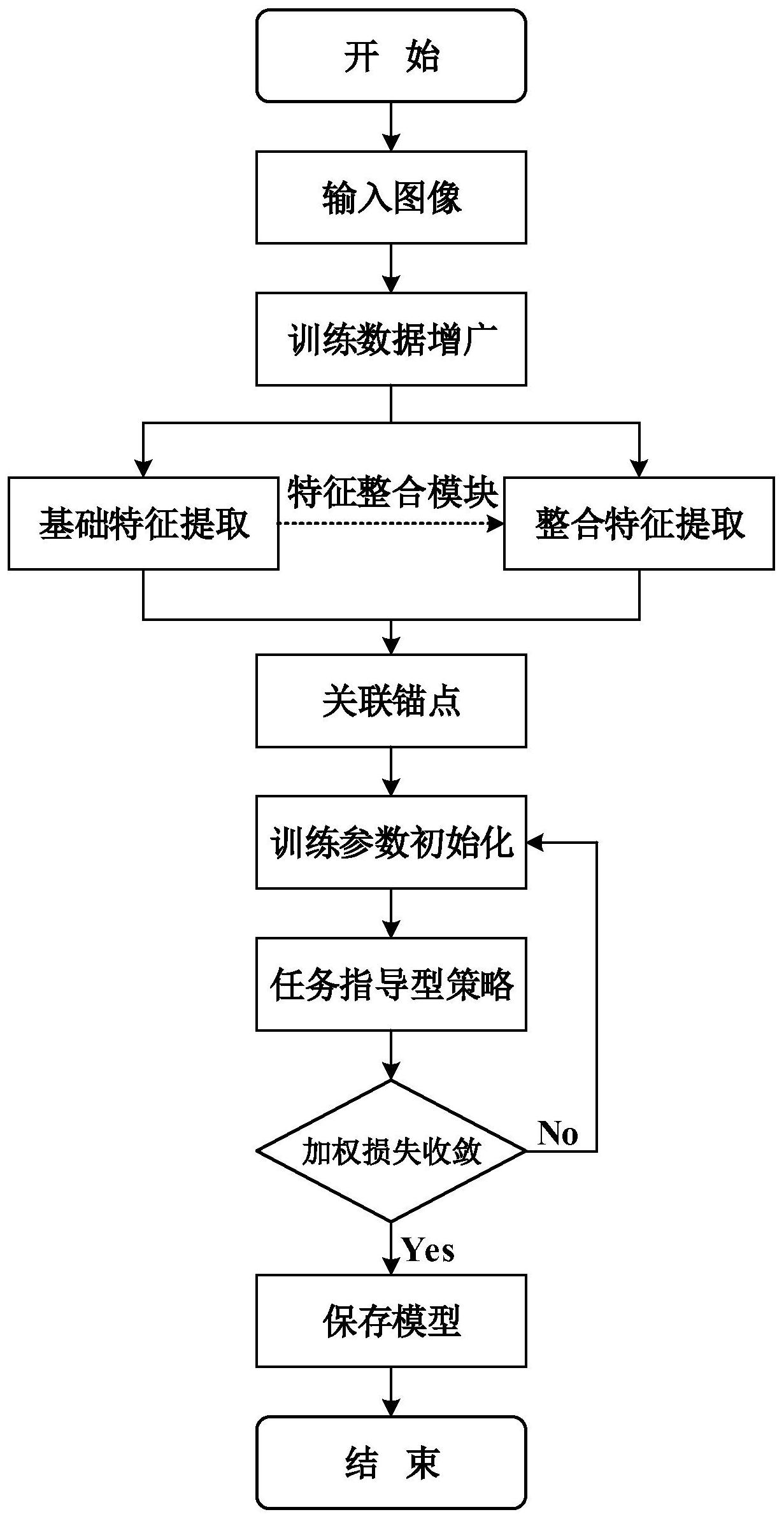
为解决上述问题,本发明提供了一种基于任务指导的轻量级人脸检测方法,着重 在以下两方面进行改进和优化:一方面,在实时性与精确度之间权衡,通过轻量级骨干网络 在有限尺度空间内尽量保留原有特征,并引入关联锚点,以半监督方式生成人脸周边的头 部、身体信息,辅助目标人脸的检测;另一方面,利用特征整合模块实现双分支架构,防止高 层语义对低层细节的破坏并精简计算,推理时应用任务指导型策略,对分类和回归分而治 之,避免判别力不足的低层特征参与位置回归,缓解了不同层特征图之间的相互干扰,实现 了算法模型的高效化。 为了达到上述目的,本发明提供如下技术方案: 6 CN 111553227 A 说 明 书 2/10 页 基于任务指导的轻量级人脸检测方法,包括如下步骤: 步骤1,对WIDERFACE(目前最为权威的人脸检测基准)训练集进行数据增广; 步骤2,基于步骤1所得到的增广图片,以轻量级骨干网络提取基础特征,利用特征 整合模块实现双分支架构,进而提取整合特征,并为用于预测的各分支、各层级特征图引入 关联锚点,以半监督方式生成人脸周边的头部、身体信息; 步骤3,在训练参数初始化后,应用任务指导型策略,将分类和回归分而治之,对构 建的选择性分类组和选择性回归组的损失进行加权求和,用以指导和监督模型的自主学习 过程,待模型收敛后保存并进行检测。 进一步的,所述步骤1具体包括如下子步骤: 步骤1.1:对训练集中的图片进行水平翻转和随机裁剪,作为初步预处理,具体操 作为:首先将输入图像扩展为原先尺寸的4倍,接着再对每一张图片进行镜像水平翻转,最 后随机地裁剪出640×640的区域大小,即应用下式进行处理: xpreprocess=Crop(Flip(Extend(xinput))) 式中,xinput表示输入的训练集图片,Extend操作是采用填充均值的方式进行图片 扩展,Flip操作表示随机地进行水平翻转,Crop为随机裁剪操作,xpreprocess则表示相应的初 步预处理结果,其尺寸统一为640×640。 步骤1.2:采用色彩抖动、噪声扰动方式来模拟无约束场景下的干扰,再次对步骤 1.1中得到的初步预处理结果xpreprocess进行不同程度地增强,进而得到综合处理后的增广 图片xprocess,如下式所示: 式中,Color操作表示色彩抖动方式,Noise(Gaussian)、Noise(Salt&pepper)操作 分别表示为图片加高斯噪声、椒盐噪声。 进一步的,所述步骤2具体包括如下子步骤: 步骤2.1:通过轻量级骨干网络对增广的输入图片进行基础特征抽取,轻量级骨干 网络采用若干Inception模块,Inception模块包括若干具有不同卷积核大小的卷积分支, 激活函数选用串联整流线性单元,分别选取Inception1、Inception2、Inception3、 Inception4、conv5_2、conv6_2作最后的预测,特征图尺寸分别为160×160、80×80、40× 40、20×20、10×10、5×5; 步骤2.2:利用特征整合模块实现双分支架构,通过转置卷积对步骤2.1中的基本 特征进行整合,具体如下式: φi'=φi·Ψ(φi 1;θ) φi 式中,φi、φi 1分别表示当前的特征图和较高一层的特征图,Ψ则是应用在高层 级特征图上的转置卷积操作,θ代表转置卷积操作的相关参数,φi'为整合后生成的新特征 图,·为逐元素相乘; 步骤2.3:为上述步骤中所得到的各个分支、各个层级的用作预测的特征图引入关 联锚点,以半监督方式生成目标人脸周围的头部、身体信息,假定相同比例、偏移量的不同 7 CN 111553227 A 说 明 书 3/10 页 人脸具有相似的周边环境特征,以某原始图像中的某目标人脸区域regiontarget为例,锚点 选择第i层特征层的第j个锚点anchori,j,步长设为si,则第k个关联锚点的标签定义如下: 式中,s kaa 代表关联锚点的步长,其中k=0 ,1 ,… ,K;anchori .j·si表示锚点 anchor k ki.j在原始图像中对应的区域,anchori.j·si/saa 表示其对应的以步长saa 进行下采 样的区域,iou表示计算该下采样区域anchor ki.j·si/saa 与真实的人脸区域regiontarget的 交并比,threshold则是根据交并比判定样本属性的阈值。 进一步的,所述步骤3具体包括如下子步骤: 步骤3.1:对训练参数初始化; 步骤3.2:在预测时,应用任务指导型策略,对分类和回归分而治之,构建选择性分 类组专门完成类别打分任务,构建选择性回归组专门完成位置回归任务,再将二者的损失 加权求和,用以指导和监督模型的自主学习过程; 步骤3.3:当步骤3.2中所计算得到的加权损失不再上升,而稳定在一个较小值域 时,则停止训练,存储模型,并进行检测;反之,则返回步骤3.1。 进一步的,所述步骤3.1中,优化器选用动量值为0.9的随机梯度下降方法;同时设 置权重衰减值为10-5。 进一步的,当迭代次数在设置的步进列表{40000,60000,80000}中时,学习率降为 原先的0.1。 进一步的,所述步骤3.2中,任务指导型策略选取步骤2.1中的轻量级骨干网络所 生成的Inception1、Inception2、Inception3、Inception4、conv5_2、conv6_2作最终的预 测,对于选择性分类组而,原始的轻量级骨干网络中的Inception1、Inception2、 Inception3首先根据预设的交并比阈值对大部分易区分的负样本进行过滤;对于选择性回 归组,原始的轻量级骨干网络中的Inception4、conv5_2、conv6_2首先对锚点的位置进行粗 略地调整。 进一步的,所述步骤3.2中,将二者的损失加权求和的过程包括如下步骤: (1)基础的类别打分由softmax损失指导训练,其表达式为: 式中,xk表示实际的类别标签,zm表示softmax层的输入,f(zm)表示softmax层所预 测的输出,T是训练数据集上的类别数; 基础的位置回归由smooth L1损失指导训练,其表达式为: 8 CN 111553227 A 说 明 书 4/10 页 式中,y(i)代表真实的位置标签, 代表CRFD模型预测的坐标标签信息,Ω表示先 验框为正样本的区域集合; (2)针对步骤2.3中所得到的关联锚点,定义第k个关联锚点的损失如下: 式中,k是关联锚点的编号,k=0,1,2分别表示面部、头部、身体,i是锚点的编号,λ 为分类与回归之间的平衡权重,Nk ,cls表示用于类别打分的正锚点框数目,Lk ,cls则表示人 脸、背景这两个类别的softmax损失,pk,i表示第i个锚点被预测为第k个目标的概率, 为 其对应的真实类别标签,表示如下: 式中,saa为步长,Nk,reg表示用于位置回归的正锚点框数目,Lk,reg表示smooth L1损 失,tk ,i是4维向量,表示第i个锚点被预测为第k个目标的边框坐标, 是与某一正样本相 关联的真实定位标签,表示如下: 式中, 分别表示原始真实标签框的中心横坐标、中心纵坐标、总宽 度和总高度, 则意味着只有在该锚点为正样本时,Lk ,reg才被激活,以上这两项损失 通过Nk,cls、Nk,reg进行归一化; (3)针对任务指导型策略,对选择性分类组和选择性回归组的损失分别定义如下: 将选择性分类组(SCG,Selective Classification Group)的损失定义如下: 式中,k是关联锚点的编号,k=0,1,2分别表示面部、头部、身体,i是锚点的索引, Nk,cls和N'k,cls分别表示用于类别打分的初始的、过滤后的正锚点框数目,Lk,cls则表示人脸、 背景这两个类别的softmax损失,pk,i、qk,i分别表示原先骨干网络及其经过特征整合模块后 的第i个锚点被预测为第k个目标的概率, 为其对应的真实类别标签; 将选择性分类组(SRG,Selective Regression Group)的损失定义如下: 式中,k是关联锚点的编号,k=0,1,2分别表示面部、头部、身体,i是锚点的索引, Nk,reg和N'k,reg分别表示用于位置回归的初始的、过滤后的正锚点框数目,Lk,reg表示smooth L1损失,而 则意味着只有在该锚点为正样本时,Lk,reg函数才有效,tk,i、xk,i分别表示 原先骨干网络及其经过特征整合模块后的第i个锚点被预测为第k个目标的边框坐标, 是 9 CN 111553227 A 说 明 书 5/10 页 与某一正样本相关联的真实定位标签; (4)将选择性分类组和选择性回归组的损失进行加权求和,即得到总损失函数如 下: L=αLSCG βLSRG 式中,α和β是平衡这二者的超参数。 与现有技术相比,本发明具有如下优点和有益效果: 1.本发明弥补了现有方法对人脸检测的实时性和工业级落地标准的忽略,构建轻 量级骨干网络,在有限尺度空间内尽量保留原有特征。在实时性与精确率之间权衡,引入关 联锚点,以半监督方式生成面部周围的头部、身体标签,辅助目标人脸的检测,补救了现有 方法对面部环境特征的非充分利用性。 2.本发明进一步减轻了不同层特征图之间的相互干扰,采用特征整合模块实现双 分支架构,在防止高层语义破坏低层细节的同时也精简了计算,在推理时应用任务指导型 策略,避免判别力不足的低层特征参与位置回归,将分类和回归分而治之,实现了算法模型 的高效化,缓解了现有方法中不同层特征图之间的相互干扰对精度的不利影响,取得了良 好的增益。 3.本发明可达到工业级实时性标准,可被部署于边缘与终端设备上,对计算能力 和内存大小的需求较低,且不需要预训练网络,可以从零开始训练和检测。 4.本发明在面向无约束场景下具有尺度不一、模糊不清、光照强弱、姿势各异、面 部遮挡以及化妆等这些属性的中、低检测难度的人脸时,也能保持较高的检测精确率,具有 极高的实时性和综合性。 附图说明 图1为本发明基于任务指导的轻量级人脸检测方法的流程图。 图2为本发明基于任务指导的轻量级人脸检测方法的网络模型图。 图3为人脸图像处理增强方式示意图。 图4为Inception模块(一种以密集成分近似最优的局部稀疏结构)原理图。 图5为轻量级骨干网络的结构及相关参数设置。 图6为特征整合模块实现原理示意图。 图7为关联锚点示例图。 图8为任务指导型策略原理图。 图9为用训练好的模型对WIDER FACE测试集上的人脸样本进行检测的效果图。 图10为训练好的模型在WIDER FACE的Easy、Medium、Hard验证集上的检测精度。 图11为用训练好的模型对无约束的人脸进行检测的效果图。 附图中照片原图均为彩色图片,因专利提交要求,现修改为灰度形式。











