
技术摘要:
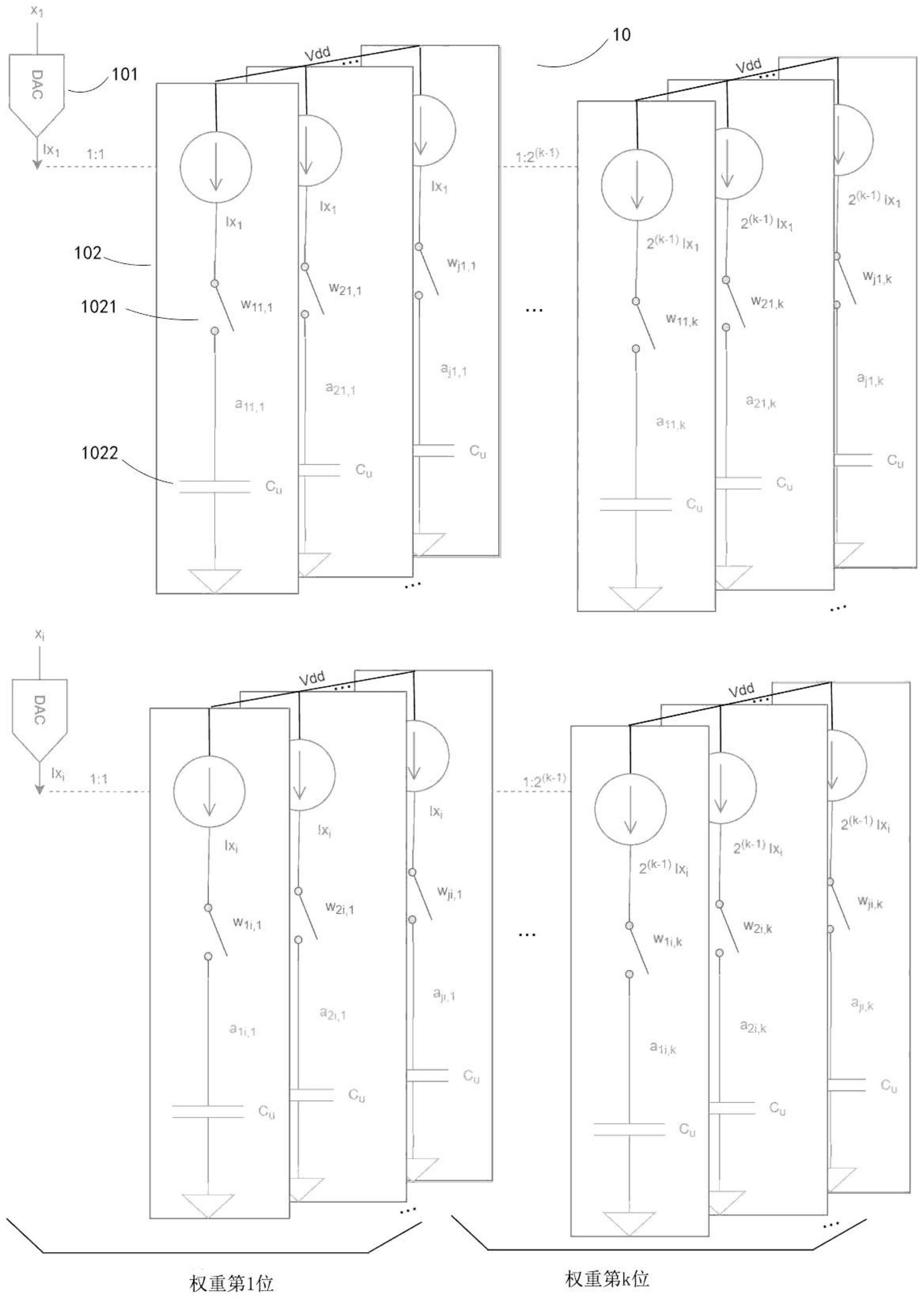
本发明涉及一种模拟运算模组,尤其涉及一种关于卷积运算的模拟运算模组,提出了一组模拟乘法器和累加器(MAC)。其中,电容器中的电流积分用于两个多位二进制数卷积过程的乘法运算的实现,而电容器间的电荷共享实现加法过程。权重位wji,k位数升高的方向的卷积运算单元内 全部
背景技术:
对低信噪比的量化,模拟运算比传统数字运算具有更高的功效,因此,通常将数字 量转化为模拟量再进行运算。尤其对于神经网络,相较其运算能耗在神经网络的中、大型硬 件实现中,由于传统的数据存储在磁盘中,进行运算时需要将数据提取到内存中,此过程需 要大量的I/O连接传统存储器的存储往往占用了更多的功耗。而基于模拟内存和近内存运 算则可以将运算过程发送到数据本地执行,极大地提升了运算速度、节约了存储面积、降低 了数据传输以及运算功耗。本发明提出了一种超低功耗模拟内存或近内存运算的有效实现 方法。 近期论文“A Mixed-Signal Binarized Convolutional-Neural-Network Accelerator Integrating Dense weight Storage and Multiplication for Reduced Data Movement”Symp.VLSI Circuits,pp.141-142,2018,提出的基于二进制的内存或近内 存的对1比特二进制数乘法的模拟运算展现了高效的表现,通过静态随机存取存储器 (Static Random-Access Memory,SRAM)单元存储1位的权重与输入的混合信号做卷积运 算,极大地提高了运算能力以及降低了存储面积,该方法涉及的结构注重一位的乘法运算 在神经网络中传递的过程,即输入层到卷积层再到池化层,最后输出。但是该
技术实现要素:
文 件,其模拟运算电路的实现没有涉及乘数或被乘数权位变化的情况,局限于1位的乘法运算 在第一次层的输入,不能用于多位二进制数的卷积模拟运算。 极少数的多位运算涉及乘数或被乘数的权位的变化,如论文: (1)“In-Memory Computation of a Machine-Learning Classifier in a Standard 6T SRAM Array”,JSSC ,pp .915-924 ,2017;(2)“A 481pJ/decision 3 .4M decision/s multifunctional deep inmemory inference processor using standard 6T SRAM array”,arXiv:1610.07501,2016;(3)“A Microprocessor implemented in 65nm CMOS with Configurable and Bit-scalable Accelerator for Programmable In- memory Computing”,arXiv:1811 .04047 ,2018;(4)“A Twin-8T SRAM Computation-In- Memory Macro for Multiple-Bit CNN-Based Machine Learning,”,ISSCC,pp.396-398, 2018,(5)“A 42pJ/Decision 3 .12TOPS/W Robust In-Memory Machine Learning Classifier with On-Chip Training ,”ISSCC,pp.490-491,2018;但是这些多位运算都是 通过利用调制当前域中的控制总线、电容电荷共享、脉冲宽度调制(Pulse-width- modulated ,PWM)、修改SRAM单元,或者用近存储器运算的复杂数字矩阵矢量处理等方式实 现的。这些多位运算的实施方法中,多位模拟乘法器和累加器一直采用非常复杂的数字处 理控制,但是在低信噪比的量化方面,传统的数字运算相较模拟运算耗费大量功效,因此这 些数字处理控制下的多位运算会产生很大的运算耗能。 4 CN 111611528 A 说 明 书 2/8 页 CN201910068644提出的二值化的卷积,进行异或运算阶段是通过调制SRAM内控制 总线从而实现电位的变化,但是该专利给出的技术方案和教导是要求采取复杂的数字处理 控制,对控制模块的要求高,消耗过多的能耗。因此,本领域亟需一种对低信噪比的信号采 用模拟运算实现超低功耗的解决方案。











