
技术摘要:
本发明是一种基于多GPU的并行A*搜索方法,涉及分布式领域。当前基于GPU的A*搜索由于GPU内存和算力的限制,当数据规模达到一定量级时,会出现速度和内存的瓶颈。本发明的内容包括:图数据分割方法和A*搜索在GPU上的执行方式。针对多GPU计算架构条件下的内存异构层次问题 全部
背景技术:
A*搜索在人工智能领域有广泛的利用,其是一种利用启发式函数进行引导的最佳 优先搜索方法。A*搜索具有多种应用途径,例如路径查找,滑块拼图等。传统的A*搜索是一 种主要在CPU上进行实现的顺序结构的方法。后来,随着多核CPU的出现,相关的研究者开始 探索基于多核CPU的A*搜索的实现方式,但是计算核心数是有限的,所以对于执行效率的提 升也是有限的。 近些年来,图形处理单元(GPU)设备的不断的扩展应用领域,虽然早期主要应用在 图形渲染方面,但是后来发现对于大规模的计算任务,通过GPU来计算可以实现不错的加速 效果。例如,GPU已经被广泛的用于大规模的图计算任务。对于网路数据包的路由处理,GPU 的高性能能加速数据包的处理,减少CPU的负载,从而达到加速路由的目的。GPU也应用于 AES等加密算法这种数据敏感的领域。通过利用GPU核数众多,适合单指令多数据的大规模 运算的特点,对密文进行并发的加密操作,从而大大提升吞吐量,减少加密时间。因此,相关 的研究者也已经在GPU上实现了A*搜索。基于GPU实现的相关方式,相较于传统的A*搜索,是 通过利用GPU可并行运算的特点,将A*搜索过程并行化。相较于CPU上的顺序执行效率,GPU 上的A*搜索实现可以实现良好的运算效果。 利用GPU来运行A*搜索,与传统的基于CPU的A*搜索相比,虽然可以达到不错的运 行效果,但是也需要考虑当前方法的局限性。由于GPU计算性能和片上内存的限制,当数据 规模不断提升时,即使不断的提高并行度,GPU的运算效果依然会出现相应的瓶颈。即使是 采用当前最先进的GPU设备,可以达到几千个计算核心,也很难满足相应的需求。 因此如何解决当前不断提升的数据量以及对运算速度的提升,是在是实现A*搜索 时,需要考虑的问题
技术实现要素:
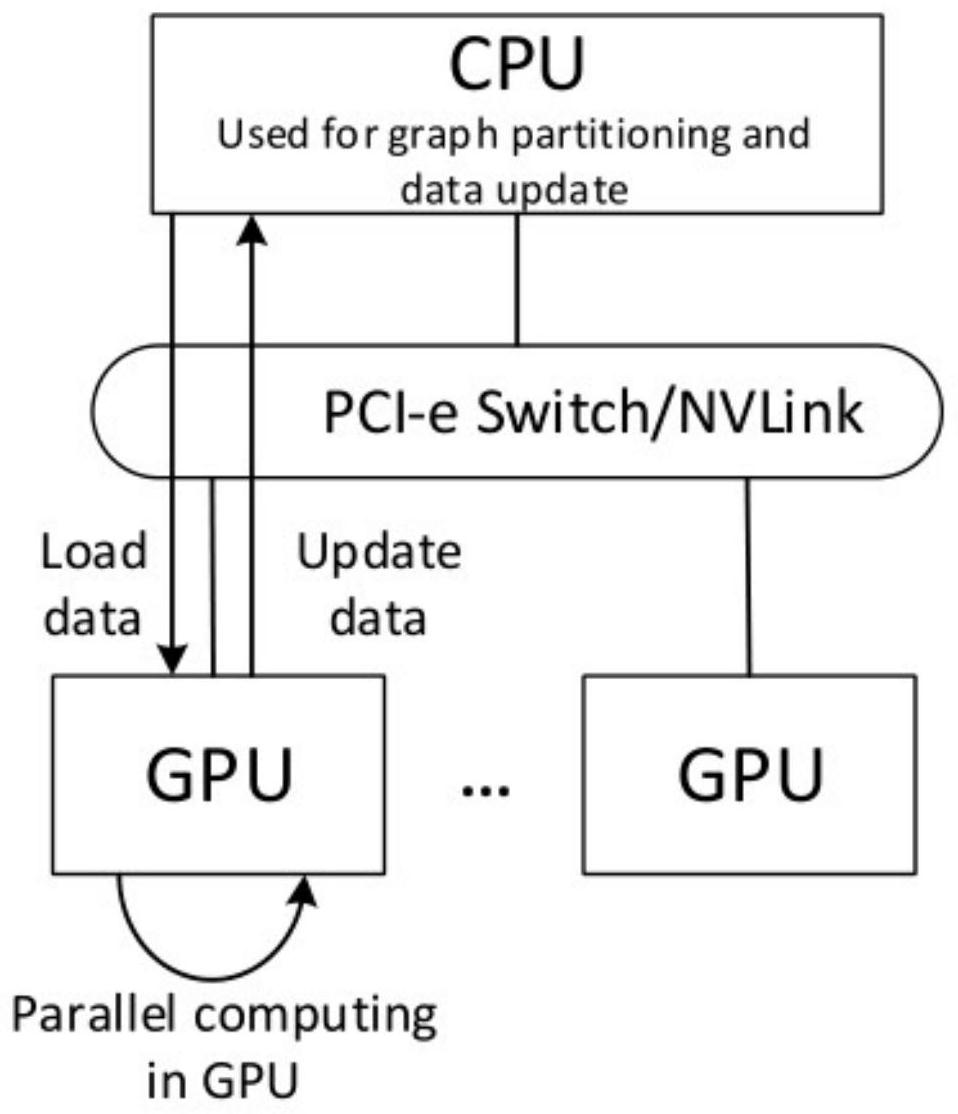
本发明是一种基于多GPU的A*搜索方法,在保证多计算设备高效运算的情况下,协 同加速A*搜索。针对多GPU计算架构条件下的内存异构层次问题,可以有效的利用计算节点 的内存体系。本发明关注于不同数据的分区方式,使之有效的实现GPU之间的负载均衡。这 些数据分别针对了不同的应用方式,分别为滑块拼图问题,网格图的随机搜索问题以及蛋 白设计问题。同时计算设备之间的数据实现高效交互,例如运算结果数据等。分区后,将在 GPU上采用了多个优先队列的方法实现A*搜索方法,并且针对多GPU的架构实现了相应的优 化。最后,针对GPU上运算可能出现的重复结点查找问题,选取了替换式的并行哈希方法。而 3 CN 111580969 A 说 明 书 2/4 页 针对一些应用的搜索空间呈指数增长可能出现的内存溢出问题,则采用边缘搜索的方法, 并用到了Scan Primitive和GPU radix sort的相关技术。以上所述方法如图1,包括: 1.图数据分区 针对A*搜索中常见的三种应用方向,分别为有向图,无向图和排列组合问题,实现 了相应的图划分方法,具体实现如下: a)有向图:针对有向图数据,为了实现GPU之间的负载均衡同时减少分区导致的时 间开销,采用了划分边的方法来进行划分,图数据中的顶点数量|V|和边的数量|E|被均匀 的进行划分,同时会选取特定的顶点用于分区数据之间的交互使用。 b)无向图:采用的无向图为网格图,由于网格图的特点,顶点的数量和边的成比例 以及边的无向性。因此,采用了划分顶点的方法。将顶点的数量|V|依据GPU的数量进行均等 的划分,边也会依据与顶点的数量自动的进行分配。分区时产生的分区间的重合结点将会 组成更新节点集,用于分区之间的数据更新。 c)排列组合问题:该问题使用到的数据为滑块拼图问题,其的数据量是未知的,由 于该类问题的数据量是随着滑块的移动而不断产生的,并且呈现指数级别的增长。因此初 始阶段是在CPU上进行运行,当产的是相关state数量S大于等于GPU的个数G时,相应的子任 务就会自动的划分到相应的GPU设备中。 2.GPU上的运行方式 相较于传统的A*搜索顺序执行流程,本发明中为了提升A*搜索的并行度,进而提 升执行效率。主要操作如下: a)open list:open list是A*搜索中的一种重要数据结构,控制着A*搜索中扩展 结点的插入和提取。为了实现并行化,本发明中使用了多级优先队列的方法来实现open list,来实现结点的提取个数,进而提升整体的并行度。 b)closed list:closed list在A*搜素中负责搜索路径的保存以及重复结点检测 的任务。在本发明中,采用了hash table进行实现,以便进行相关操作。 c)重复检测:针对A*图搜索出现的重复检测问题,采用了“替换式并行哈希”方法, 其是一种轻量级的概率数据结构,旨在在多GPU环境中简化操作。主要优点是在检测期间可 以忽略少量重复节点,可以快速,简单地实现。 d)内存受限操作:当遇到排列组合类问题时,由于该类问题的搜索空间呈指数级 增长,因此,极易出现内存问题。本发明采用了“边界搜索”的方法来处理,当内存不足时,会 选择牺牲搜索的最优性。 附图说明 图1:系统流程示意图 图2:基于多GPU的三种内存结构示意图











