
技术摘要:
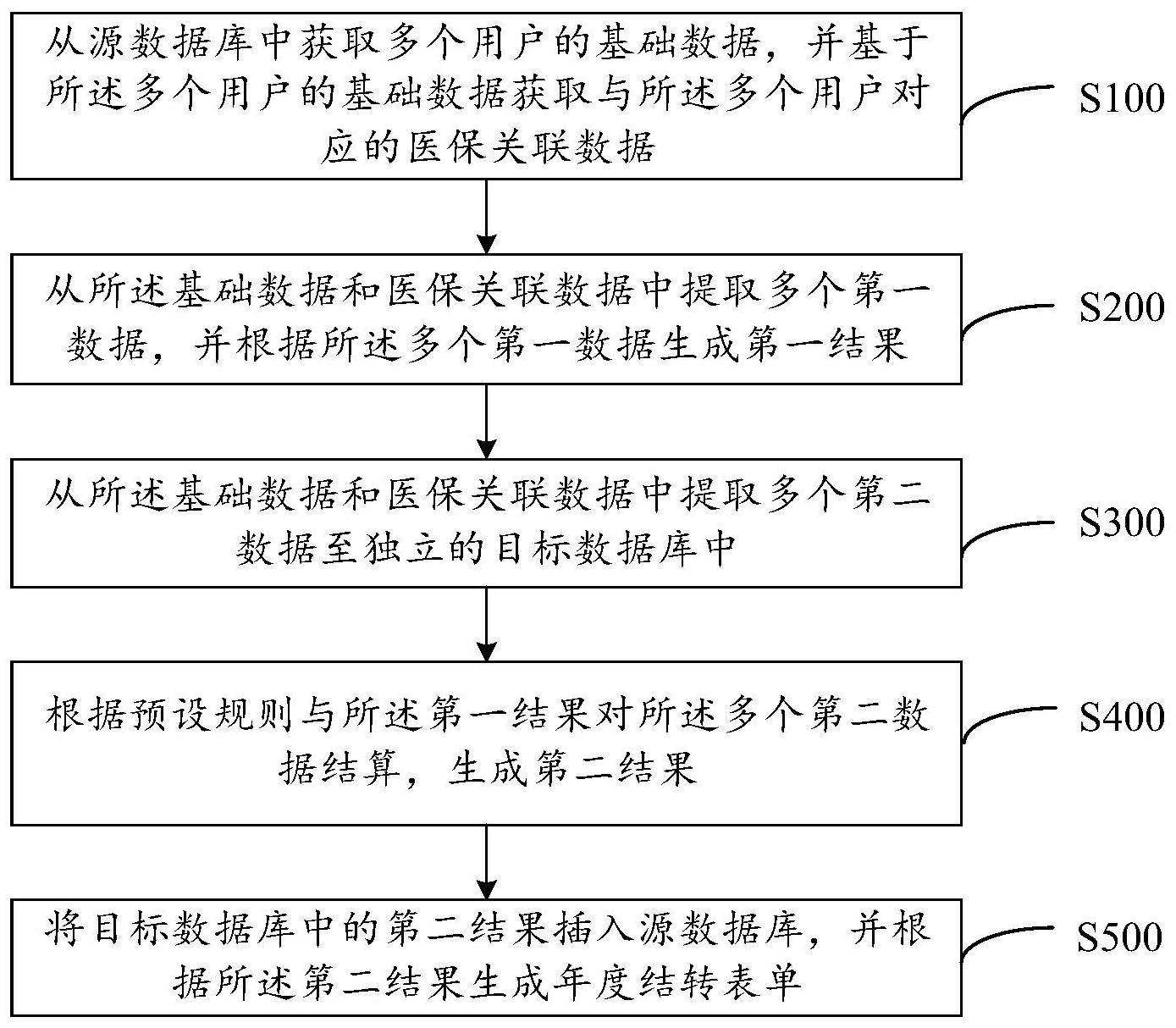
本发明实施例提供一种基于医保数据的数据处理方法,包括:从源数据库中获取多个用户的基础数据,并基于所述基础数据获取对应的医保关联数据;从所述基础数据和医保关联数据中提取多个第一数据,并根据所述多个第一数据生成第一结果;从所述基础数据和医保关联数据中提 全部
背景技术:
随着社会医疗服务的发展以及医保制度在全国范围的广泛开展,医保对于人们来 说越来越重要。而正是由于医保的重要性,需要对医保数据进行相应的处理。 但是,大批量的数据处理会造成数据库性能的消耗,甚至是造成系统卡顿、运行缓 慢等问题。例如,在跨年度的时候,各地医保部门在进行医保年度结转时,由于需要对大批 量的参保人的数据进行处理,会造成数据库及应用程序的性能大量消耗,导致实时就医交 易时间变慢,甚至会造成医保的累计信息表及用户医疗账户表死锁,而影响到整个医保核 心系统服务。
技术实现要素:
有鉴于此,本发明实施例提供了一种基于医保数据的数据处理方法、系统、计算机 设备及计算机可读存储介质,用于解决大批量数据处理导致数据库性能消耗高、医疗系统 卡顿、运行慢的问题。 本发明实施例是通过下述技术方案来解决上述技术问题: 一种基于医保数据的数据处理方法,包括: 从源数据库中获取多个用户的基础数据,并基于所述多个用户的基础数据获取与 所述多个用户对应的医保关联数据; 从所述基础数据和医保关联数据中提取多个第一数据,并根据所述多个第一数据 生成第一结果; 从所述基础数据和医保关联数据中提取多个第二数据至独立的目标数据库中; 根据预设规则与所述第一结果对所述多个第二数据结算,生成第二结果; 将目标数据库中的第二结果插入源数据库,并根据所述第二结果生成年度结转表 单。 进一步地,所述多个第一数据包括:第一类数据、第二类数据以及第三类数据; 所述从所述基础数据和医保关联数据中提取多个第一数据包括: 根据所述基础数据获取对应的第一类表单、独立的第二类表单和独立的第三类表 单; 根据预设结算时间在第一类表单上生成累计年度值,根据所述累计年度值获取目 标第一类表单; 从所述目标第一类表单中提取多个第一类数据,从所述独立的第二类表单中获取 多个第二类数据,以及从所述独立的第三类表单中获取多个第三类数据。 进一步地,所述目标第一类表单包括当前年度第一类表单和新年度第一类表单; 4 CN 111553799 A 说 明 书 2/9 页 所述根据预设结算时间在第一类表单上生成累计年度值,根据所述累计年度值获取目标第 一类表单还包括: 从所述医保关联数据中按照时序获取目标第一时间数据和目标第二时间数据; 当所述第一时间数据早于所述预设结算时间,且所述第二时间数据晚于所述结算 时间时,生成当前年度值以及新年度值; 根据所述当前年度值获取当前年度第一类表单,以及根据所述新年度值获取新年 度第一类表单。 进一步地,第二数据包括第四类数据和第五类数据; 所述从所述基础数据和医保关联数据中提取多个第二数据至目标数据库中还包 括: 从所述基础数据中提取对应的医保类型数据; 并基于所述医保类型数据对用户分类,得到至少一个用户集合,所述用户集合包 括至少一个医保类型相同的用户; 根据所述用户集合对应的医保类型提取对应的医保关联数据中的第四类数据和 第五类数据至目标数据库中。 进一步地,所述第一结果包括医保账户划入划出结果,所述第二结果包括新年度 预划结果;所述根据预设规则与所述第一结果对所述多个第二数据结算,生成第二结果还 包括: 根据所述用户集合对应的医保类型获取相应的第一预设规则; 基于所述医保账户划入划出结果对所述多个第二数据结算,生成新年度预划结 果。 进一步地,所述从所述基础数据和医保关联数据中提取多个第二数据至目标数据 库中之前还包括: 获取当前时间,并基于所述当前时间为所述医保关联数据生成对应的当前流水号 数据; 将目标数据库中的第二结果插入源数据库,并根据所述第二结果生成年度结转表 单之前还包括: 获取医保关联数据对应的当前流水号数据; 在所述当前流水号数据末尾添加随机码,以生成在线流水号数据。 进一步地,所述源数据库中的基础数据和医保关联数据存储于区块链节点,所述 从源数据库中获取多个用户的基础数据之前还包括: 从所述区块链节点中的源数据库获取目标统筹地区数据,并基于所述目标统筹地 区数据获取多个用户的基础数据。 为了实现上述目的,本发明实施例还提供一种基于医保数据的数据处理系统,包 括: 获取模块,用于从源数据库中获取多个用户的多个基础数据,并基于所述多个用 户的基础数据获取与所述多个用户对应的医保关联数据; 第一生成模块,用于从所述基础数据和医保关联数据中提取多个第一数据,并根 据所述多个第一数据生成第一结果; 5 CN 111553799 A 说 明 书 3/9 页 提取模块,用于从所述基础数据和医保关联数据中提取多个第二数据至独立的目 标数据库中; 第二生成模块,用于根据预设规则与所述第一结果对所述多个第二数据结算,生 成第二结果; 第三生成模块,用于将目标数据库中的第二结果插入源数据库,并根据所述第二 结果生成年度结转表单。 为了实现上述目的,本发明实施例还提供一种计算机设备,所述计算机设备包括 存储器、处理器以及存储在所述存储器上并可在处理器上运行的计算机程序,所述处理器 执行所述计算机程序时实现如上所述基于医保数据的数据处理方法的步骤。 为了实现上述目的,本发明实施例还提供一种计算机可读存储介质,所述计算机 可读存储介质内存储有计算机程序,所述计算机程序可被至少一个处理器所执行,以使所 述至少一个处理器执行如上所述的基于医保数据的数据处理方法的步骤。 本发明实施例提供的基于医保数据的数据处理方法、系统、计算机设备及计算机 可读存储介质,通过从源数据库中获取多个用户的基础数据和医保关联数据;根据基础数 据和医保关联数据中的多个第一数据生成第一结果;将所述基础数据和医保关联数据中的 多个第二数据提取至独立的目标数据库中;在目标数据库中,根据预设规则与所述第一结 果对所述多个第二数据结算得到第二结果;最后将目标数据库中的第二结果插入源数据库 并生成年度结转表单;本发明实施例通过源数据库和目标数据库实现读写分离处理,以使 得在进行医保年度结转时,能够有效地减少数据库性能的消耗,提高资源的利用率,提高效 率;有助于医保核心系统服务地正常运行。 以下结合附图和具体实施例对本发明进行详细描述,但不作为对本发明的限定。 附图说明 图1为本发明实施例一之基于医保数据的数据处理方法的步骤流程图; 图2为本发明实施例一之基于医保数据的数据处理方法中提取多个第一数据的步 骤流程图; 图3为本发明实施例一之基于医保数据的数据处理方法中获取目标第一类表单的 步骤流程图; 图4为本发明实施例一之基于医保数据的数据处理方法中提取多个第二数据至目 标数据库中的步骤流程图; 图5为本发明实施例一之基于医保数据的数据处理方法中生成第二结果的步骤流 程图; 图6为本发明实施例一之基于医保数据的数据处理方法中生成在线流水号数据的 步骤流程图; 图7为本发明实施例二之基于医保数据的数据处理系统的程序模块示意图; 图8为本发明实施例三之计算机设备的硬件结构示意图。











