
技术摘要:
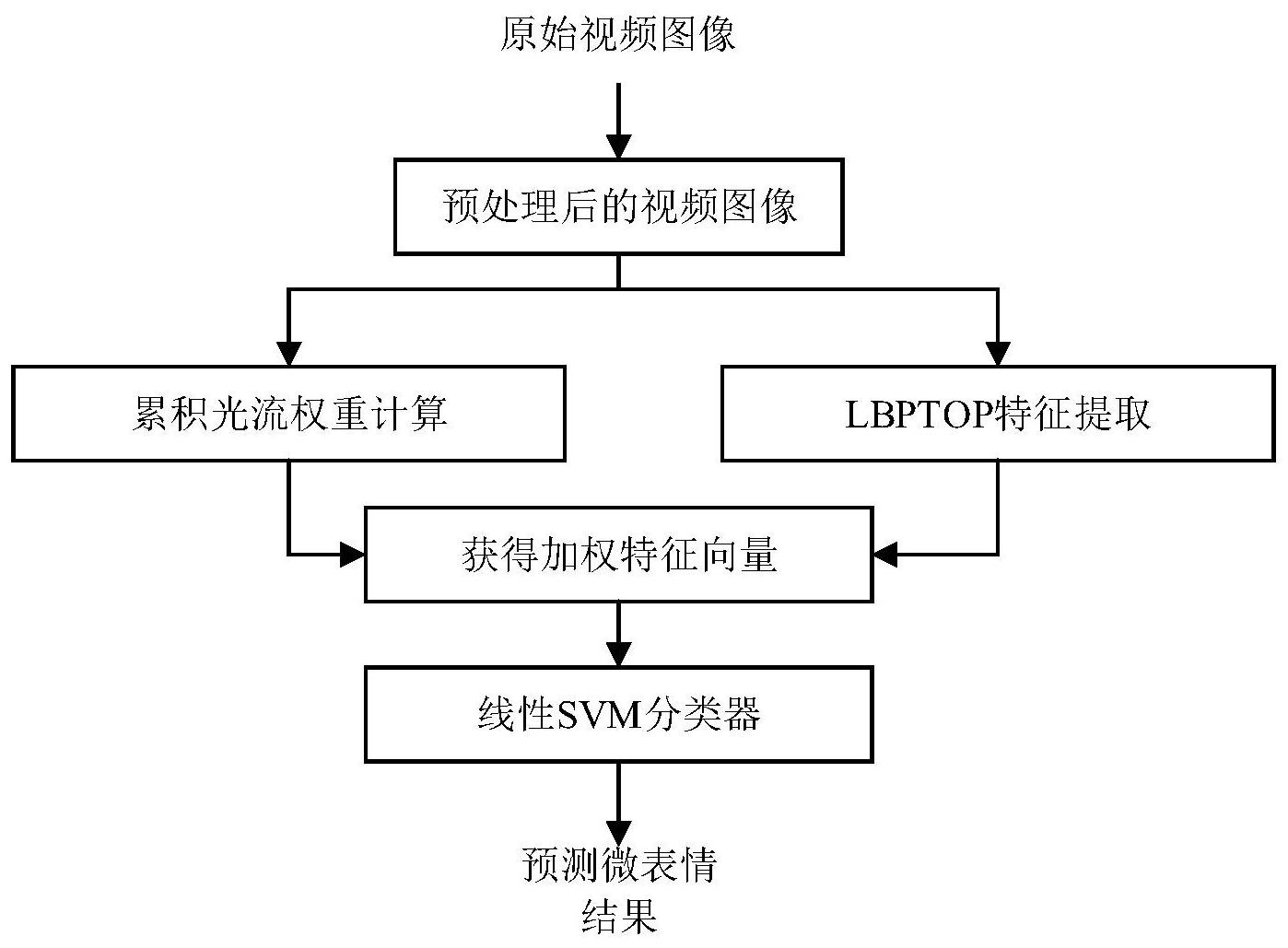
本发明公开了一种基于累积光流加权特征的微表情识别方法,包括如下步骤:步骤A:对输入视频中的各图像进行预处理;步骤B:对经过步骤A预处理的视频图像进行光流提取,并将光流进行累加以获得累积光流图;步骤C:由步骤B获得的累积光流图计算出反应面部各个区域运动强度 全部
背景技术:
微表情作为一种人类在试图隐藏某种感情时无意识做出的、短暂的面部表情。由 于其仅受潜意识控制,无法自主控制的特点,微表情在心理学、情感监测、国家安全等领域 都有巨大的潜在价值。随着计算机视觉技术的发展,使用计算机视觉技术自动识别微表情 作为一个重要课题受到很多研究者的关注。但是由于微表情的生理学特性,微表情识别中 存在很多技术挑战。微表情的运动强度低,持续时间短,发生区域小,只有经过专业训练的 人员才能良好地识别出微表情。但是人工识别微表情需要专业人员花费大量的时间成本, 同时由于微表情运动十分细微,人工识别时极易出现错误,因此,研究微表情自动识别技术 尤为重要。 目前大多微表情自动识别技术使用的是传统的图像分类技术的思路,主要是先对 图像各个区域进行时空特征提取,再将时空特征送入分类器进行分类。时空特征能够记录 视频图像中微表情的运动信息。这种微表情识别方法一般将视频图像等分成若干区域,然 后提取每个区域的特征向量拼接起来作为此图像的整体特征向量。Liong.等人根据微表情 发生区域小的特点,提出了一种区域特征加权的方法,根据视频图像中各个区域的运动强 度计算出一个权重矩阵,再利用矩阵中的权重对相应区域的特征进行加权,以加强微表情 发生区域的特征。 但是微表情的运动强度十分微弱,计算权重时很容易受到图像噪声的影响。因为 微表情的运动强度十分微弱,其发生区域的权重本身不会很大,而这时图像噪声也会是图 像上部分区域产生微弱的运动,从而使这些区域也存在较小的权重,对原本就不大的微表 情发生区域的权重会产生很大影响。所以相较于常规图像识别问题,图像噪声在微表情识 别中会造成更大的影响。 这此背景下,研究一种能够良好的抵抗噪音对微弱的微表情运动干扰的微表情识 别方法显得尤为重要。
技术实现要素:
本发明要解决的技术问题是提供一种基于累积光流加权特征的微表情识别方法, 以降低图像噪音在微表情识别时带来的干扰,从而实现更好的微表情识别效果。 本发明所采用的技术方案如下: 一种基于累积光流加权特征的微表情识别方法,该方法包括以下步骤: 首先,针对样本集中的每一个样本,即已知分类标签的原始面部视频,分别提取其 分类特征,将样本的分类特征作为分类器的输入,样本的微表情分类标签作为分类器的输 出,训练出一个用于识别微表情的分类器; 5 CN 111597864 A 说 明 书 2/8 页 然后,针对待识别的原始面部视频,先提取其分类特征,再将其特征送入训练好的 分类器中进行分类,得到微表情识别结果; 对任一原始面部视频,提取其分类特征的方法包括以下步骤: 步骤A:对该原始面部视频进行预处理; 步骤B:对预处理后的视频提取光流,并对光流进行累加以获得累积光流图; 步骤C:由步骤B获得的累积光流图计算出反应面部各个区域运动强度的权重矩 阵; 步骤D:对该原始面部视频提取LBPTOP特征;使用步骤C计算出的权重矩阵对相应 位置的LBPTOP特征进行加权,加权后的LBPTOP特征即为原始面部视频的特征。 进一步地,所述步骤A包括对原始面部视频进行对齐、剪切等预处理操作,以消除 不同原始面部视频中的面部尺度差异和头部运动等因素带来的视频间的差异因素。所述对 齐处理是使用图像变换方程对各个原始面部视频图像进行变换,使其与同一模板图像对 齐,从而使所有面部视频图像对齐;对于任一原始面部视频,其对齐处理包括以下步骤: A5)使用ASM(Active Shape Models,主动形状模型)方法对模板图像Pmod的68个面 部特征点进行检测,检测结果记为ψ(Pmod); A6)使用ASM方法对该原始面部视频的第一帧图像P1进行68个面部特征点检测,检 测结果记为ψ(P1); A7)使用局部加权平均算法(LWM)计算出P1与模板图像Imod之间的变换矩阵TRAN, 计算公式如下: TRAN=LWM(ψ(Pmod) ,ψ(P1)); A8)对该原始面部视频中的每一帧图像分别使用步骤3)中计算出的变换矩阵TRAN 进行处理,处理公式如下: Pj′=TRAN×Pj,j=1,2,...,J 其中,Pj表示该原始面部视频中的第j帧图像,Pj′表示Pj经过变换矩阵TRAN处理后 得到的图像,J为该原始面部视频中包含的图像的帧数。 进一步地,所述剪切处理为:对Pj′,根据其中眼睛的位置定义一个特定大小的矩 形将面部区域截取下来,截取下来的面部区域用到后续步骤中。 进一步地,选取某个样本的第一帧面部图像作为模板图像Pmod。 进一步地,所述步骤B通过将光流表达的运动信息累加,使运动方向随机的图像噪 音相互抵消从而减弱,而运动方向一致的面部运动则会得到加强,其具体步骤如下: B3)对归一化后的视频中的各帧图像,计算其对应的光流F(x,y),用于表示视频图 像中的运动信息; 光流计算中为了保证计算出的是图像中的运动信息,有以下三个假设:亮度不变 性、无剧烈运动、临近点速度一致;在这三个条件的约束下建立并求解光流的梯度方程(光 流约束方程): Ixu Iyv It=0 其中, 分别是光流F(x,y)沿x和y方向的分量,F(x,y)=(u,v);I(x, 6 CN 111597864 A 说 明 书 3/8 页 y ,t)是图像上像素点(x,y)在时刻t的亮度, 分别是亮度I对x、y 和t的偏导数(梯度);对于视频中的第j帧图像,其对应的各个参数值可通过它和它后一帧 图像的灰度信息计算得到;光流F(x,y)的计算为现有技术; 将视频中第j帧图像对应的光流记为Fj(x,y),其中j=2,3,…,J; B4)将视频中各帧图像对应的光流进行分段累加,获得累积光流图: 其中,Ck(x,y)表示第k个分段的累积光流图;k=1,2,…,S,S为视频的总分段数, 由原始面部视频中包含的图像的帧数决定;D代表每个分段的长度;将带有运动信息的光流 累积(即向量相加),噪声造成的随机方向运动有一部分会相互抵消,而表情造成的方向一 致的运动则会相互叠加产生更大的值。 进一步地,步骤C根据步骤B中得到的累积光流图Ck(x,y)计算出用于加权LBPTOP 特征的权重矩阵。具体步骤如下: C5)首先将累积光流图Ck(x,y)平均分成N×M个小块,每个小块的大小为H×W,其 中H为平均分出的小块的高,其大小为视频图像的高除以N;W为平均分出小块的宽,其大小 为视频图像的宽除以M; C6)计算出每一个小块中所有像素的光流强度之和: 其中, 和 分别为Ck(x,y)的水平运动量和垂直运动量,即 Mn,m表示累积光流图上坐标为(n,m)的小块中所有像素的光流强度之和,n=1,2,…,N,m= 1,2,…,M; C7)对Mn,m进行归一化处理,得到每个小块的权重: 其中,Wn,m图像上坐标为(n,m)的小块的权重,max( )是最大值函数;通过归一化处 理,将Mn,m的值归一化到[0,1]之内; C8)将Wn,m作为权重矩阵W的(n,m)元,构建权重矩阵W。 进一步地,步骤D提取LBPTOP特征,再乘以权重以获得最后的加权特征。具体步骤 如下: D1)对原始面部视频进行处理,使其包含的图像的帧数为设定帧数Z;若原始面部 视频中包含的图像的帧数小于Z,则采用时间插值算法增加图像帧,若原始面部视频中包含 的图像的帧数超过Z,则对其图像帧进行删减,使其包含的图像帧数等于Z; D2)将步骤D1)得到的视频在空间上分成对应于权重矩阵大小的N×M个视频小块, 每个视频小块的大小为H×W×T,其中T为视频小块包含的图像帧数;对于每个视频小块,从 中提取LBPTOP特征;LBPTOP特征是LBP从二维空间到三维空间的拓展,LBPTOP的全称为: local binary patterns from three orthogonal planes ,这里的three orthogonal 7 CN 111597864 A 说 明 书 4/8 页 planes指的就是三个正交平面,即xy平面、xt平面和yt平面。其计算方法如下: 其中,Hn,m ,b,p表示视频中坐标为(l,m)的视频小块的LBPTOP特征,其维度为(nb 1) ×3,fp(x,y,t)表示像素点(x,y,t)在第p个平面中的LBP值,b=0,1,...,nb,nb是LBP值的最 大值,LBP值的种类数为nb 1;p=0,1 ,2分别对应xy平面、xt平面和yt平面;I{A}为判断函 数: D3)将Hn,m,b,p乘以对应的权重Mn,m,获得加权特征Gn,m,b,p; D4)将Gn ,m ,b,p作为特征G的(n,m,b,p)元,得到最后的特征G,即为原始面部视频的 分类特征,其维度为N×M×(nb 1)×3。 进一步地,所述步骤D2)中,采用等价模式的LBP值,即对各像素点,先采用圆形邻 域半径为R,采样点个数为P的LBP算子计算得到其二进制LBP编码;为降低LBP特征的维度, 再采用等价模式对LBP编码进行转换,得到其对应的等价模式的LBP值,本方法做出了如下 的参数选择:采样点个数P设置为8,xy平面中圆形邻域半径R设置为1,xt平面和yt平面中圆 形邻域半径R设置为2,模式种类数=P(P-1) 2=58,将58种等价模式分别编码为1-58,除了 等价模式类之外的混合模式类编码为0,得到LBP值的种类数为59,每个小块的LBPTOP特征 维度为177。 进一步地,由于分类特征维数较高,本方法选择线性SVM作为分类器。 本发明利用面部运动产生的位移的运动方向一致而图像噪音产生的位移方向随 机这一原理,设计了一种基于累积光流的权重计算方法,使用该权重对LBPTOP特征加权后 降低了噪音在特征表现微表情运动时产生的影响,增强了特征对于微表情的鉴别性,从而 提高了微表情自动识别的准确率。 有益效果 本发明公开了一种基于累积光流加权特征的微表情识别方法,包括如下步骤:步 骤A:对输入视频中的各图像进行预处理以去除面部大小差异等因素对识别的影响;步骤B: 对经过步骤A预处理的视频图像进行光流提取,并将光流进行累加以获得累积光流图;步骤 C:由步骤B获得的累积光流图计算出反应面部各个区域运动强度的权重矩阵;步骤D:对原 始视频提取LBPTOP时空特征。使用步骤C计算出的权重矩阵对相应位置的LBPTOP特征直方 图进行加权已获得最后的加权特征向量;步骤E:以步骤D中得到的加权后的特征向量作为 输入,使用线性SVM训练出一个用于识别微表情的分类器;该方法可以有效的进行微表情自 动识别,不需要心理学专业人士来进行微表情识别。该方法通过光流的时序累加,使微表情 运动产生的一致性运动与图像噪音产生的随机运动区分开来,从而使得在进行基于运动强 度的权重计算时减少了噪音的干扰,以获得更精确的描述运动强度的权重,使特征向量中 产生微表情的部分得到更好的加强。经过加权后的向量对微表情有更好的鉴别性。 8 CN 111597864 A 说 明 书 5/8 页 附图说明 图1为本发明流程图; 图2为本发明实施例中获取累积光流权重矩阵的流程图; 图3为实施例1得到的部分光流图; 图4为实施例1的某一累积光流图; 图5为实施例1的累积光流强度图; 图6为实施例1的的权重矩阵图;











