
技术摘要:
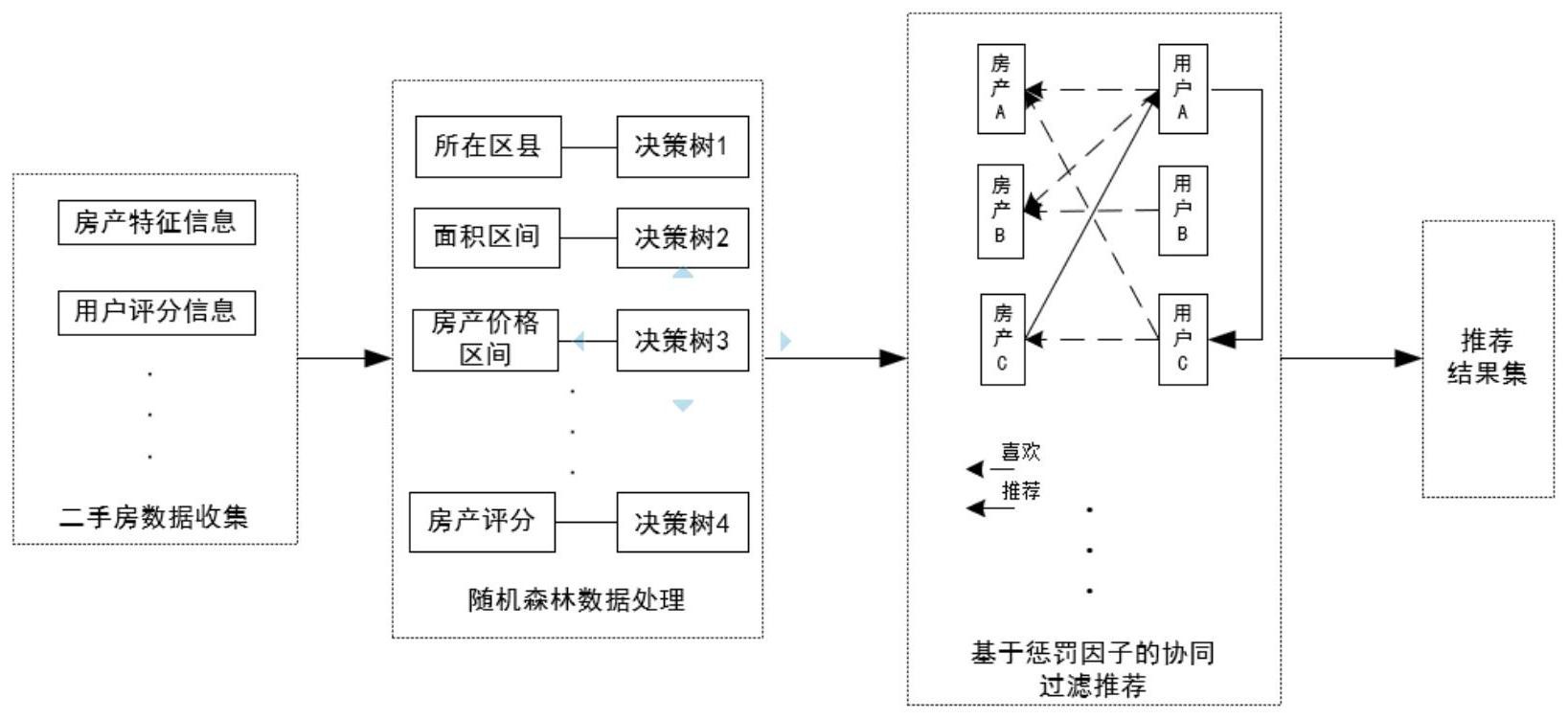
一种融合随机森林与协同过滤二手房推荐方法,包括二手房数据收集、随机森林数据处理、基于惩罚因子的协同过滤推荐及推荐结果集;从多个二手房房产网站获取二手房产数据和用户评分数据;然后,通过随机森林算法分类处理、清洗和汇总,得到有效的二手房数据和二手房打分 全部
背景技术:
随着众多的城市进行新房限购令和摇号等新房政策出现,二手房自主选择的优势 被越来越多的买房需求用户所关注。随着互联网技术的发展,二手房需求用户逐渐依赖二 手房中介网站提供二手房信息。然而随着二手房数据的逐年增加,需求用户获取到有效的 二手房信息更加困难。目前,大部分二手房中介网站基于需求用户搜索内容进行匹配推荐, 推荐准确率低,推荐体验效果不佳。而有效的二手房推荐能使需求用户及时和准确获取二 手房信息,具有很高的研究意义。由于二手房数据和用户行为数据是房产中介公司的核心 数据,因此可参考二手房推荐实例较少。而二手房推荐的主要矛盾就是如何在复杂的二手 房数据中找到需求用户感兴趣的二手房。 毛凤华提出一种基于聚类分析的二手房推荐方法,从各属性相似的族挑选出价格 更低的房源推荐,但是该方法只是考虑到价格在各类型二手房中的影响。没有从推荐算法 精确度的提高做出要求。目前受到广泛认可的推荐算法主要是三种,分别是基于内容的推 荐算法、协同过滤算法(CF)和混合推荐等,其中协同过滤算法被受推崇推荐技术之一。协同 过滤算法也存在缺陷,如协同过滤推荐系统中的冷启动问题,多分类中的数据稀疏性问题 和推荐精度问题,会造成推荐误差,也会影响推荐结果的精确性和稳定性。基于协同过滤算 法出现不足,李澎林等使用基于兴趣度与类型因子的推荐算法来提高推荐效果。吴海金等 使用融合分类与协同过滤的情境感知来对音乐进行分类推荐,但是存在分类方法过于简单 直接,在分类量较多的情况下已经不能适用;李浩等提出融合循环知识图谱和协同过滤电 影推荐算法,在充分考虑物品、用户、评分之间的相关性后,利用基于物品和用户的协同过 滤进行Top-K电影推荐;林耀进等提出基于用户群体影响的协同过滤推荐算法,不但考虑了 用户个体之间的相似性,而且考虑了用户所处群体之间的相似性,增强了推荐系统的鲁棒 性和准确性;徐立明等提出带有惩罚因子的余弦相似度的修正公式。可以提高低活跃度项 目对推荐影响;张宜浩等提出基于用户评论的深度情感分析和多视图协同融合的混合推荐 方法,解决了混合推荐系统中不同兴趣偏好的多推荐视图难以融合的问题,同时在一定程 度上解决了推荐系统建模中缺乏足够的有标签数据问题。使用协同过滤算法找到用户具有 较高的相似度是的应用基点,数据存在稀疏性,让推荐效果不佳。当然,也有不少算法模型 是对数据分类处理来解决数据稀疏性问题。2001年Breiman等结合多个分类器组合的思想, 由多个决策树生成随机森林,从而让其有更好的分类效果。在此基础上,宣琦等[设计一种 多个视图提取特征构建支持向量机分类器,实现二分类,分类精度达到87.73%;韦泽鲲等 为了解决网络流量分类中提取特征的多样化和复杂化问题,提出基于随机森林的流量多特 征与分类算法,实验结果表明该算法能够更加高效和精确进行分类提取;李欢等提出融合 因子分析的随机森林模型采用因子分析法构建特征组,再按特征个数比随机抽取特征形成 4 CN 111598645 A 说 明 书 2/7 页 每个分裂节点的候选子集,提高了模型的准确率和收敛速度,泛化性更强,更加有利于高维 大数据,可行有效。还有魏正韬等提出非平衡数据的随机森林分类算法去区分正类和负类; 而孟利民等基于用户协同过滤的改进推荐模型,通过分析用户的历史评分数据集,预测需 求用户对新二手房的评分。
技术实现要素:
为了克服现有技术的不足,对于多分类且杂乱二手房数据和需求用户的二手房数 据来说,随机森林算法具有更优的分类数据能力,而协同过滤算法在能够提供高效的推荐 效果。因此,本发明提出融合随机森林与协同过滤二手房推荐模型,提供一种融合随机森林 与协同过滤二手房推荐方法。 为了解决上述技术问题本发明提供如下的技术方案: 一种融合随机森林与协同过滤二手房推荐方法,从多个二手房房产网站获取二手 房产数据和用户评分数据;然后,通过随机森林算法分类处理、清洗和汇总,得到有效的二 手房数据和二手房打分数据;最后,输入基于惩罚因子的协同过滤算法中完成推荐。 所述方法包括以下步骤: 1)二手房数据收集 获取二手房数据和对应的评分数据,通过对数据集的分析,发现二手房特征数据 具有数据稀疏性,需要进行分类处理;随机森林具有很强的分类效果和数据稀疏性解决能 力,通过对二手房多个特征调查研究,选取代表特征包括区域,面积区间,总价格区间,楼 层,房产布局,装修情况,卧室朝向和房产周边交通; 2)随机森林数据处理 将所有的房产特征数字化,通过将二手房数据用随机森林算法使用规则表处理成 标签数据集,将获取的评分数据与二手房标签数据相结合,并通过随机森林进行打分处理 评价,得到打分数据集,其中,打分值区间为1-5,分值越大,所代表的评价越高; 经过随机森林处理后的有效数据,打分数据表导入到打分数据集,而标签数据表 导入到特征数据集,将打分数据集与特征数据集作为实验数据集,使用实验数据集进行二 手房推荐; 3)输入基于惩罚因子的协同过滤算法中完成推荐,过程如下: 二手房i和二手房j的评分相似性表示为公式(1),如下: 将引入惩罚因子的皮尔逊相似性函数,提高计算用户间相似度的准确性,w(i,j) 表示相关性惩罚因子,其计算公式(2),如下: 5 CN 111598645 A 说 明 书 3/7 页 其中,act(u)表示用户u的活跃度,diff(i,j)表示二手房i和二手房j流行度的差 值,β表示项目流行度的阈值,α表示惩罚因子; 计算用户i和用户j之间的相似度,I(ij)是代表用户i和用户j共同评价过的二手 房,R(i,x)代表用户i对二手房x的评分, 代表用户i评分的平均分,因为用户评分标准有差 异减去平均分,归一化以避免差异影响,得出公式(3),如下: 其中Ui和Uj分别代表对二手房i和二手房j评分用户的集合,Ui∩Uj表示对二手房i 和j共同评分用户的集合。Ru,i和Ru,j分别表示用户u对二手房i和二手房j的平均评分。 进一步,所述步骤2)中,随机森林的数据清理步骤如下: 2 .1、清理二手房脏数据和评分脏数据,从二手房数据中选出容量为N的训练集T 中,采用自助抽样法,即有放回地抽取K个二手房样本,作为一个二手房训练子集Tk; 2.2、对于二手房训练子集Tk,从二手房特征集F中随机选取8个二手房特征,作为 决策树上每个节点分裂的依据,从根结点开始,自上而下生成一个完整二手房的决策树Sk, 不需要剪枝; 2.3、重复多次步骤2.1和步骤2.2,得到w个二手房训练子集T1,T2,…,Tw,并生成二 手房决策树d1,d2,…,dυ,将υ个二手房决策树组合起来,形成随机森林; 2.4、将二手房测试集D的样本Sn进行决策,然后采用多数投票法对决策结果投票, 最终决定Sn的分类; 2.5、重复λ次步骤2.4直到二手房测试集D分类完成,得到标签数据表,如表2; 2.6、获取二手房房产用户对二手房进行的评分数据,然后清洗少于三次评分的用 户评分,得到初步的二手房房产用户打分数据; 2.7、依据随机森林算法分类数据集标签,对初步的二手房房产用户打分结果进行 评价,如果出现同一类别的打分共Q条数据,出现Q/2以上的数据不一致,则判定为该用户的 打分为脏数据,如果该用户同一类别的打分结果只有少数不同,则将打分结果差异较小的 一方判定为脏数据,清洗,得到打分数据表。 本发明的有益效果为:将实验数据集和测试用户房产特征集导入基于惩罚因子的 协同过滤算法中,基于惩罚因子的协同过滤算法改善经典的皮尔逊相似性计算会出现用户 数据稀疏而造成误差较大和低流行度的二手房被推荐率较低等问题,提高了推荐的准确 率。 6 CN 111598645 A 说 明 书 4/7 页 随机森林处理分类数据后,剔除脏数据,获得有效的二手房分类数据和打分数据。 解决了多分类二手房存在的二手房数据稀疏问题。再引入基于惩罚因子的协同过滤算法 中,改善经典的皮尔逊相似性计算会出现用户数据稀疏而造成误差较大和二手房低流行度 被推荐率较低等问题,来提升二手房需求用户间相似度的准确率。 附图说明 图1是融合随机森林和协同过滤推荐模型结构图。 图2是RF结构图。 图3是评分预测示例图。 图4是不同算法对比(精确率、召回率、F1_Score)











