
技术摘要:
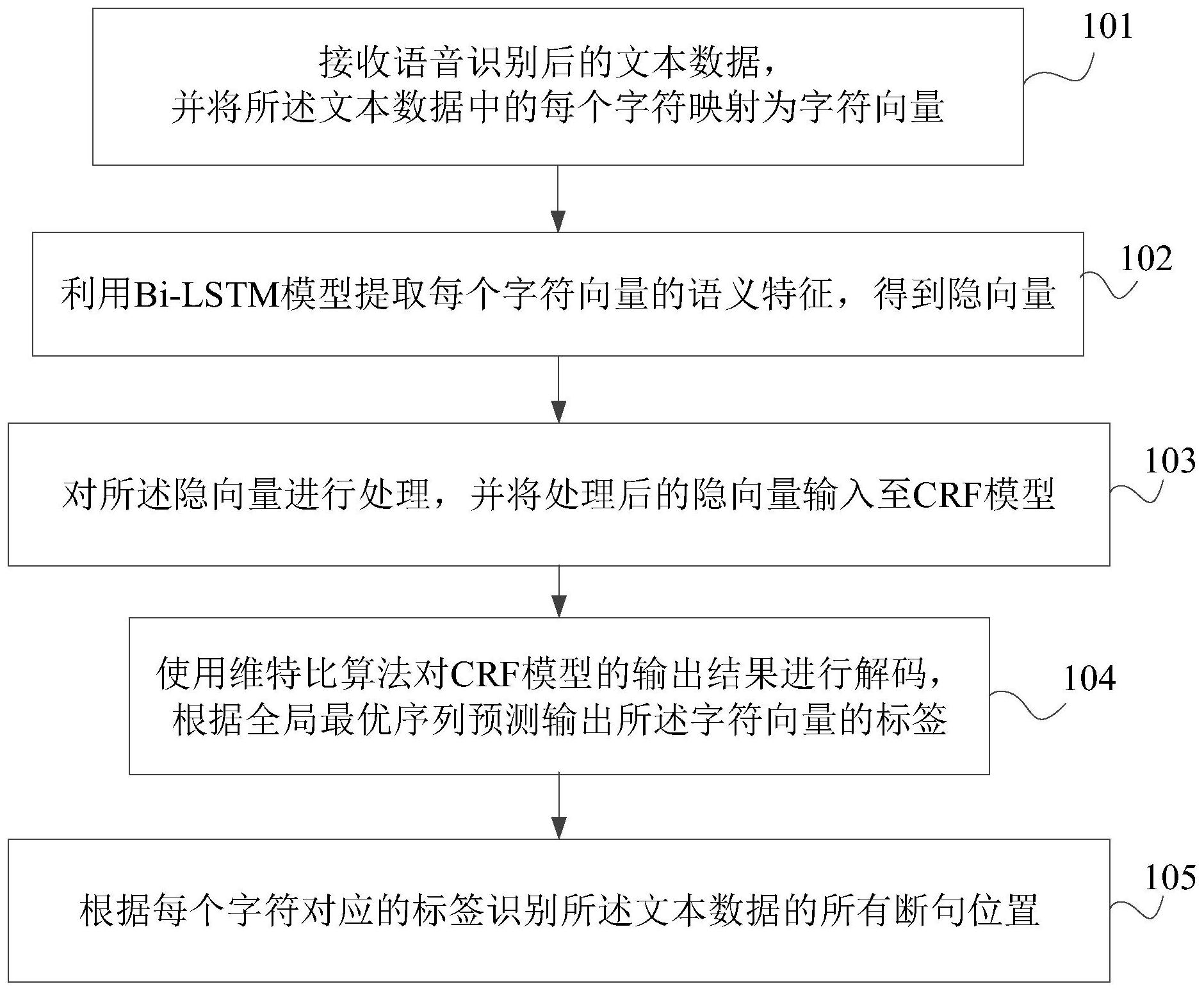
本发明公开了文本断句位置的识别方法及系统、电子设备及存储介质,其中,文本断句位置的识别方法包括以下步骤:接收语音识别后的文本数据,并将所述文本数据中的每个字符映射为字符向量;利用Bi‑LSTM模型提取每个字符向量的语义特征,得到隐向量;对所述隐向量进行处 全部
背景技术:
随着人工智能技术的发展,很多重复性的工作将交由机器完成,客服机器人就是 一种实例。要使客服机器人更好的服务于客户和下游任务,比如客户说的话的意图识别、命 名实体识别等的准确率是至关重要的。断句功能在上述过程中起到一个桥梁作用。当客户 说的话因为长度过长,无法进行正确的意图识别或者分类时,将长句截断,即将长句变成短 句,以提升后续意图识别、命名实体识别、分类任务等的准确率。 当前,深度学习在人工智能领域应用广泛,基于深度学习的模型,随着层数的加宽 和加深,能够很好地实现特征提取的作用,相较于传统的机器学习方法,利用深度学习做工 程应用时,省去了人工提取特征的步骤,往往还能取得更好的效果。因此,深度学习在文本、 图像、音频等领域都被广泛地使用。
技术实现要素:
本发明要解决的技术问题是为了克服现有技术中语音识别得到的文本数据由于 未断句导致后续意图识别、命名实体识别、分类任务等下游任务准确率低下的缺陷,提供一 种文本断句位置的识别方法及系统、电子设备及存储介质。 本发明是通过下述技术方案来解决上述技术问题: 本发明提供一种文本断句位置的识别方法,包括以下步骤: 接收语音识别后的文本数据,并将所述文本数据中的每个字符映射为字符向量; 利用Bi-LSTM(Bidirectional Long Short-Term Memory,双向长短期记忆网络) 模型提取每个字符向量的语义特征,得到隐向量; 对所述隐向量进行处理,并将处理后的隐向量输入至CRF(conditional random field,条件随机场)模型; 使用维特比算法对CRF模型的输出结果进行解码,根据全局最优序列预测输出所 述字符向量的标签,其中,所述标签用于表征所述字符后面是否为断句位置; 根据每个字符对应的标签识别所述文本数据的所有断句位置。 较佳地,所述根据每个字符对应的标签识别所述文本数据的所有断句位置,具体 包括以下步骤: 若目标字符对应的标签表征所述目标字符后面为断句位置,则判断所述目标字符 与下一个位置的字符组成的字符串是否为单词; 若否,则识别所述目标字符后面为断句位置。 较佳地,所述根据每个字符对应的标签识别所述文本数据的所有断句位置,具体 包括以下步骤: 4 CN 111737991 A 说 明 书 2/7 页 若目标字符对应的标签表征所述目标字符后面为断句位置,且所述目标字符为英 文字符,则判断所述目标字符的下一个位置是否为英文字符; 若否,则识别所述目标字符后面为断句位置。 较佳地,基于以下步骤训练所述Bi-LSTM模型和所述CRF模型: 对人工标记的目标文本数据添加用于表征是否为断句位置的标签; 将所述目标文本数据中的每个字符映射为字符向量; 利用Bi-LSTM模型提取每个字符向量的语义特征,得到隐向量; 对所述隐向量进行处理,并将处理后的隐向量输入至CRF模型; 使用维特比算法对CRF模型的输出结果进行解码,根据全局最优序列预测输出所 述字符向量的标签; 根据人工标注的断句位置与预测得到的标签调整所述Bi-LSTM模型和所述CRF模 型的参数,直至预测得到的标签所对应的损失值达到收敛。 较佳地,所述对所述隐向量进行处理包括以下步骤:按照最后一个维度对所述隐 向量进行拼接。 本发明还提供一种文本断句位置的识别系统,包括: 接收模块,用于接收语音识别后的文本数据,并将所述文本数据中的每个字符映 射为字符向量; 提取模块,用于利用Bi-LSTM模型提取每个字符向量的语义特征,得到隐向量; 处理模块,用于对所述隐向量进行处理,并将处理后的隐向量输入至CRF模型; 预测模块,用于使用维特比算法对CRF模型的输出结果进行解码,根据全局最优序 列预测输出所述字符向量的标签,其中,所述标签用于表征所述字符后面是否为断句位置; 识别模块,用于根据每个字符对应的标签识别所述文本数据的所有断句位置。 较佳地,所述识别模块具体用于在目标字符对应的标签表征所述目标字符后面为 断句位置的情况下,判断所述目标字符与下一个位置的字符组成的字符串是否为单词,若 否,则识别所述目标字符后面为断句位置。 较佳地,所述识别模块具体用于在目标字符对应的标签表征所述目标字符后面为 断句位置且所述目标字符为英文字符的情况下,判断所述目标字符的下一个位置是否为英 文字符,若否,则识别所述目标字符后面为断句位置。 本发明还提供了一种电子设备,包括存储器、处理器及存储在存储器上并可在处 理器上运行的计算机程序,所述处理器执行所述计算机程序时实现上述任一项所述的文本 断句位置的识别方法。 本发明还提供了一种计算机可读存储介质,其上存储有计算机程序,所述计算机 程序被处理器执行时实现上述任一项所述的文本断句位置的识别方法的步骤。 本发明的积极进步效果在于:通过将接收的文本数据中的每个字符映射为字符向 量,利用Bi-LSTM模型提取每个字符向量的语义特征,得到隐向量,并对所述隐向量进行处 理后输入至CRF模型,以及使用维特比算法对CRF模型的输出结果进行解码,根据全局最优 序列预测输出所述字符向量的标签,最后根据每个字符对应的标签识别所述文本数据的所 有断句位置。与现有技术中未对语音识别得到的文本数据进行断句相比,通过Bi-LSTM模型 提取语义特征,并利用CRF模型作为输出层,实现了文本断句位置的识别,进而提高了后续 5 CN 111737991 A 说 明 书 3/7 页 意图识别、命名实体识别、分类任务等下游任务的准确率。 附图说明 图1为本发明实施例1提供的一种文本断句位置的识别方法的流程图。 图2为本发明实施例1提供的一种文本断句位置的识别方法的框架图。 图3为本发明实施例2提供的一种文本断句位置的识别系统的结构框图。 图4为本发明实施例3的电子设备的结构示意图。











