
技术摘要:
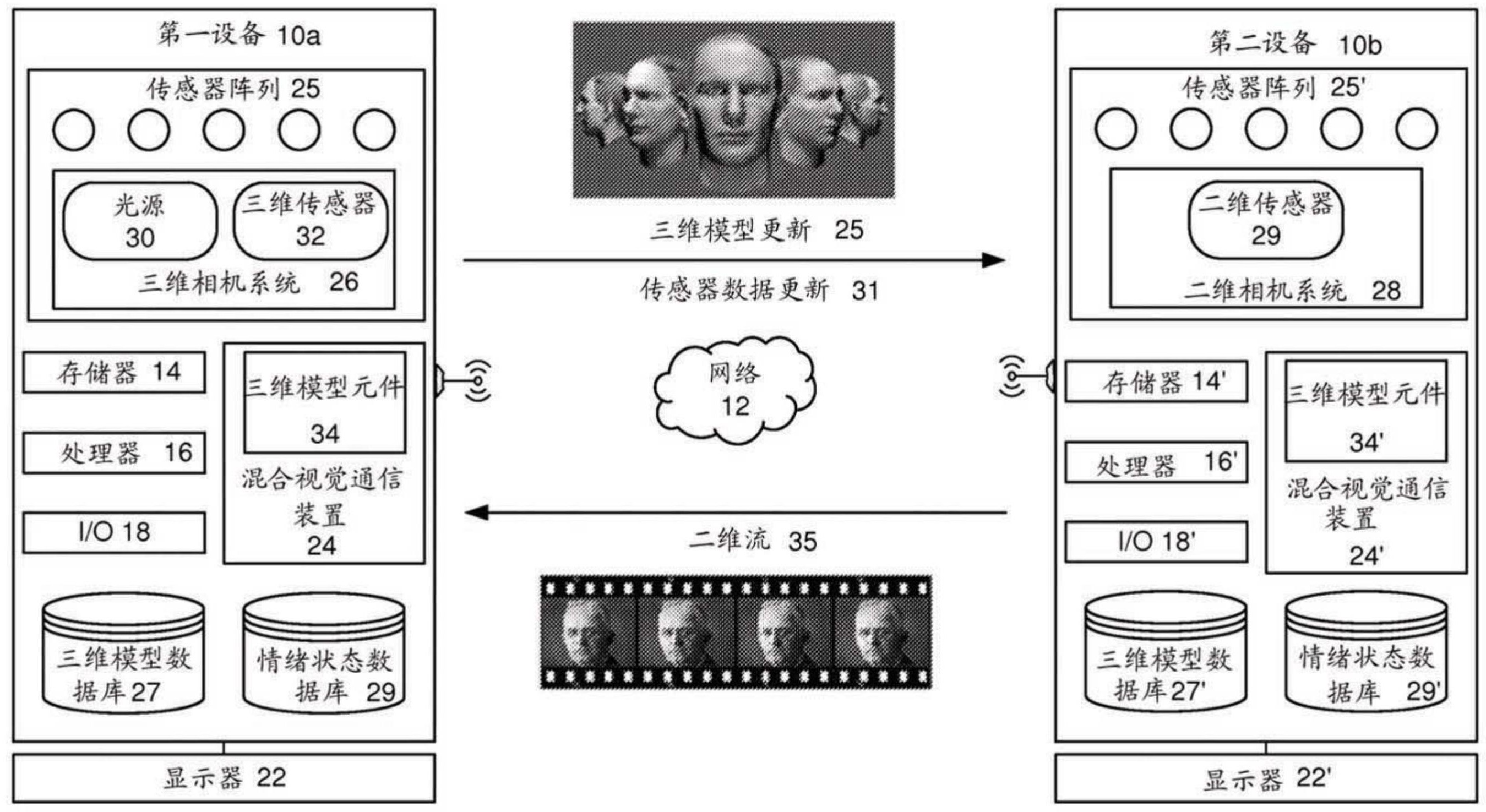
一种用于在第一设备与第二设备之间的视觉通信的方法,包括:使用来自相机系统的数据以创建第一设备用户的三维网格模型,其中所述三维网格模型被制作为可用于存储在第二设备上供随后显示在第二设备上;在第一设备与第二设备之间的视觉通信对话期间,从传感器阵列接收传 全部
背景技术:
现有视频通信系统和服务,诸如SkypeTM和Google HangoutTM,在运行玩家应用的 设备之间发送二维视频信息流。这样的视频通信系统典型地在设备之间发送与音频流配对 的压缩的连续图像的视频流。供单个用户使用的大多数视频通信系统需要在包括相机和显 示器的计算机上运行的玩家应用。计算机设备的例子可以包括具有安装在屏幕上方的相机 的台式机或者膝上型计算机,或者具有嵌入位于上方的前盖的相机的移动电话。 虽然向用户有利地提供视频能力,但是现有视频通信系统具有若干缺点。例如,现 有视频通信系统典型地需要高带宽并且是固有地高延迟,因为整个图像序列需要在发送信 号到另一设备之前被生成和压缩。另外,对于低延迟和高质量应用来说,现有视频通信系统 需要通信设备通过Wi--Fi、3G或者4G移动通信技术进行发送。 不论在台式机、膝上计算机还是移动电话上,视频通信装置中的另一个问题是,因 为用户的注视方向是在设备的显示器上,其一般低于相机安装的地方,所以用户看起来好 像在俯视它们经由视频正在通信的人。这一相机/显示器几何结构不一致使用户不能在眼 睛看着彼此的同时进行会话。相关问题是,发送包括人的二维图像序列的视频还丢失关于 他们的脸的三维深度信息。 还存在一些系统,它们可以发送用户的替身(alter ego)或者角色——通常称为 化身(avatar)的图形表示,但是化身一般无法在通信期间传达用户的实际外表、面部表情 和肢体运动。 因此,存在对于能够在降低带宽的同时显示用户实际外表、面部表情和实时运动 的电视通信系统的需要。
技术实现要素:
示范性实施例提供用于在第一设备与第二设备之间的视觉通信的方法和系统。示 范性实施例的方面包括:使用来自相机系统的数据创建第一设备用户的三维网格模型,其 中所述三维网格模型被制作为可用于存储在第二设备上以供随后显示在第二设备上;在第 一设备与第二设备之间的视觉通信对话期间,从传感器阵列接收传感器数据,该传感器数 据包括捕获改变第一设备用户的面部表情和运动的图像数据;使用图像数据确定三维网格 6 CN 111599012 A 说 明 书 2/10 页 模型更新;发送三维网格模型更新到第二设备以用于第二设备更新第一设备用户的三维网 格模型的显示;以及从第二设备接收二维视频流或者对第二设备用户的三维网格模型的更 新中的至少一个以显示在第一设备上。 根据此处公开的方法和系统,考虑在带宽受限的环境中流畅的通信,发送三维网 格模型更新需要比发送图像序列小很多的带宽。另外,在第一设备上,在解释对于三维网格 模型的改变和发送更新比捕获新的图像和压缩图像为图像序列方面存在低延迟。在第二设 备上,与必须等待整个图像编码/压缩/发送/解压缩循环相反,三维网格模型或者混和形状 的单个节点能够被一次更新。并且即使第二设备不支持三维视频通信,第二设备仍能够在 通过传统的二维视频发送通信到第一设备的同时显示第一设备用户的三维网格模型。 更具体地,示范性实施例提供一种用于在第一设备与第二设备之间的视觉通信的 方法,包括:使用来自相机系统的数据以创建第一设备用户的三维网格模型,其中所述三维 网格模型被制作为可用于存储在第二设备上供随后显示在第二设备上;在第一设备与第二 设备之间的视觉通信对话期间,从传感器阵列接收传感器数据,该传感器数据包括捕获改 变的第一设备用户的面部表情和运动的图像数据;使用图像数据确定三维网格模型更新; 发送三维网格模型更新到第二设备供第二设备更新第一设备用户的三维网格模型的显示, 其中表示三维网格模型更新为以下其中之一:a)对于从检测到的第一设备用户的位置变化 计算的三维网格模型的相对顶点位置的改变,和b)所选择的混和形状系数或者一个或多个 所选择的混和形状的其它列举;以及从第二设备接收用于显示在第一设备上的二维视频流 或者对第二设备用户的三维网格模型的更新中的至少一个 附图说明 本发明的总体发明构思的一些和/或其它特征和效用将从以下结合附图的详细说 明中变得更加明显以及更加容易理解,附图中: 图1是示出混合视觉通信系统的示范性实施例的框图; 图2是示出提供在两个或多个设备之间的混合视觉通信的过程的框图; 图3是示出由三维模型元件创建用户的脸和头的3D网格模型的表示的框图; 图4是示出一系列所存储的表示面部表情的混和形状的图;和 图5是示出在第一设备与第二设备之间的三维和二维视觉模式的不同组合期间由 混合视频通信装置执行的过程的图。











