
技术摘要:
本申请涉及一种基于大数据的用户画像方法、装置、计算机设备和存储介质。所述方法包括:获取待分析的用户数据,包括数值变量和非数值变量,对各非数值变量进行实体嵌入编码,将各非数值变量从语义空间映射至向量空间,从向量空间中确定与非数值变量对应的连续向量,对 全部
背景技术:
随着计算机技术的发展,以及智能终端设备在人们工作生活中的广泛应用,越来 越多用户在金融企业的消费行为发生了变化。金融企业大多根据掌握的用户属性和用户消 费行为等数据对于用户进行用户画像,来为提供更为满足用户需求的金融服务和更贴切的 金融产品。其中,用户画像主要包括用户消费行为信息和用户人口属性信息如出生地,年龄 等,利用聚类算法可将用户不同维度的信息进行组合,把行为、属性相似的用户聚在一起。 传统的用户画像方式通常为利用K-Means算法,以样本间距离为衡量标准,将所有 样本划分到K个群体,使得群体和群体之间的距离最大化,同时群体内部的样本之间的距离 最小化。由于K-Means算法对数据类型要求较高,类别变量比如受教育水平和所在城市等, 由于无法在维度空间内刻画类别之间的距离,均不适用于K-Means算法,因此很多用户画像 仅根据用户连续变量相关信息进行聚类,聚类完成之后再做统计每个簇在分类变量上的分 布信息,或者将类别变量进行独热编码处理,再进行分类。 然而经独热编码后的特征会变成强特征,对K-Means算法的聚类结果有很大的影 响,由于K-Means算法对所有聚类指标的权重均相同,会出现分类结果不符合实际业务需求 的情况,导致得到的用户画像精确度较低。
技术实现要素:
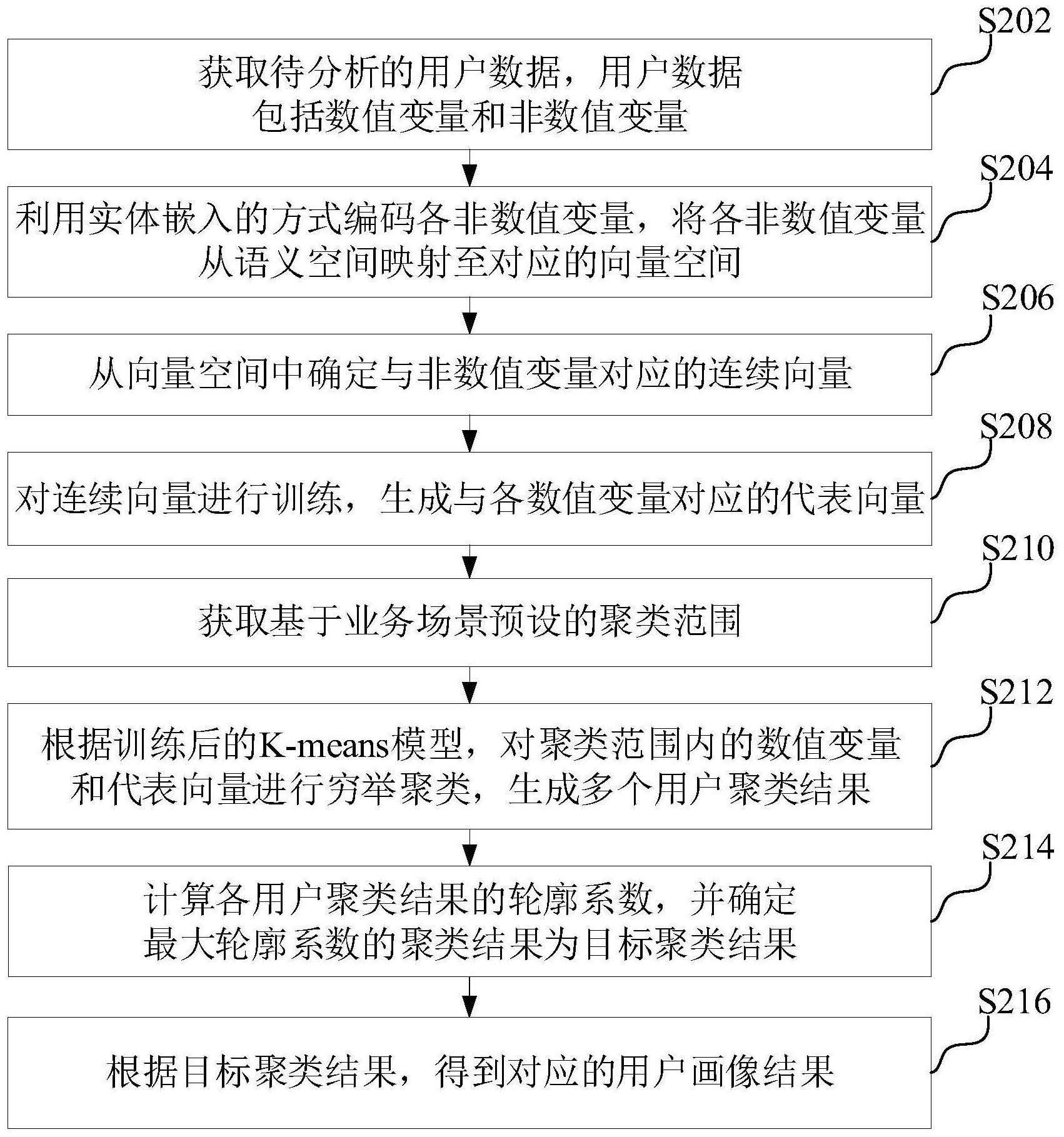
基于此,有必要针对上述技术问题,提供一种能够提高用户画像精确度的用户画 像方法、装置、计算机设备和存储介质。 一种用户画像方法,所述方法包括: 获取待分析的用户数据;所述用户数据包括数值变量和非数值变量; 利用实体嵌入的方式编码各所述非数值变量,将各所述非数值变量从语义空间映 射至对应的向量空间; 从所述向量空间中确定与所述非数值变量对应的连续向量; 对所述连续向量进行训练,生成与各所述数值变量对应的代表向量;获取基于业 务场景预设的聚类范围; 根据训练后的K-means模型,对所述聚类范围内的所述数值变量和所述代表向量 进行穷举聚类,生成多个用户聚类结果; 计算各所述用户聚类结果的轮廓系数,并确定最大轮廓系数的聚类结果为目标聚 类结果; 根据所述目标聚类结果,得到对应的用户画像结果。 在其中一个实施例中,所述方法还包括: 4 CN 111597348 A 说 明 书 2/15 页 获取各所述非数值变量的出现频次,并根据所述出现频次从所述向量空间中确定 各所述非数值变量对应的识别标识向量; 将各所述非数值变量对应的识别标识向量确定为原始K-means模型的实际标签; 根据各所述实际标签对所述原始K-means模型进行训练,得到对应的训练后的K- means模型。 在其中一个实施例中,所述从所述向量空间中确定与所述非数值变量对应的连续 向量,包括: 获取经所述实体嵌入的方式编码后的各所述非数值变量之间的间隔距离; 按照所述间隔距离的大小,将与各所述非数值变量邻近的向量分配至与所述非数 值变量对应的类别向量; 将与所述非数值变量邻近的向量,确定为相应所述非数值变量对应的连续向量。 在其中一个实施例中,所述根据训练后的K-means模型,对所述聚类范围内的所述 数值变量和所述代表向量进行穷举聚类,生成多个用户聚类结果,包括: 根据各所述实际标签,分别确定对应的数值变量和代表向量;所述数值变量和代 表向量处于所述聚类范围; 将对应所述数值变量和所述代表向量,输入与所述实际标签对应的训练后的K- means模型; 分别获取各所述训练后的K-means模型输出的用户聚类结果,其中,所述用户聚类 结果存储在区块链中。 在其中一个实施例中,所述计算各所述用户聚类结果的轮廓系数,并确定最大轮 廓系数的聚类结果为目标聚类结果,包括: 从所述用户数据中选取任一数据样本,确定为第一样本; 获取所述第一样本所在同簇的其他数据样本,并计算所述第一样本至同簇内其他 数据样本间的平均距离,确定为所述第一样本的簇内不相似度; 从所述用户数据中选取任一簇,确定为目标簇,并获取所述目标簇内的所有数据 样本; 计算所述第一样本至所述目标簇内的所有数据样本的平均距离,确定为所述第一 样本的簇间不相似度; 根据所述簇内不相似度和所述簇间不相似度,计算所述第一样本的轮廓系数; 返回从所述用户数据中选取任一数据样本,确定为第一样本的步骤,直至确定最 大轮廓系数的聚类结果,根据所述得到最大轮廓系数的聚类结果目标聚类结果。 在其中一个实施例中,所述方法还包括:采用以下公式计算所述第一样本的轮廓 系数: 其中,s(i)为所述第一样本的轮廓系数,a(i)为所述第一样本的簇内不相似度,b 5 CN 111597348 A 说 明 书 3/15 页 (i)为所述第一样本的簇间不相似度;当所述s(i)接近1时,表明所述第一样本聚类合理,当 所述s(i)接近-1时或0时,表明所述第一样本聚类不合理。 在其中一个实施例中,在所述获取待分析的用户数据之前,所述方法还包括: 采集各个用户的属性数据和消费行为数据,生成数据样本集; 对所述数据样本集内各样本数据进行数据类型识别,确定各所述样本数据所属的 数据类型; 分别对不同数据类型的所述样本数据进行数据预处理,生成待分析的用户数据。 一种用户画像装置,所述装置包括: 用户数据获取模块,用于获取待分析的用户数据;所述用户数据包括数值变量和 非数值变量; 实体嵌入编码模块,用于利用实体嵌入的方式编码各所述非数值变量,将各所述 非数值变量从语义空间映射至对应的向量空间; 连续向量确定模块,用于从所述向量空间中确定与所述非数值变量对应的连续向 量; 代表向量生成模块,用于对所述连续向量进行训练,生成与各所述数值变量对应 的代表向量; 聚类范围获取模块,用于获取基于业务场景预设的聚类范围; 用户聚类结果生成模块,用于根据训练后的K-means模型,对所述聚类范围内的所 述数值变量和所述代表向量进行穷举聚类,生成多个用户聚类结果; 目标聚类结果确定模块,用于计算各所述用户聚类结果的轮廓系数,并确定最大 轮廓系数的聚类结果为目标聚类结果; 用户画像结果生成模块,用于根据所述目标聚类结果,得到对应的用户画像结果。 一种计算机设备,包括存储器和处理器,所述存储器存储有计算机程序,所述处理 器执行所述计算机程序时实现以下步骤: 获取待分析的用户数据;所述用户数据包括数值变量和非数值变量; 利用实体嵌入的方式编码各所述非数值变量,将各所述非数值变量从语义空间映 射至对应的向量空间; 从所述向量空间中确定与所述非数值变量对应的连续向量; 对所述连续向量进行训练,生成与各所述数值变量对应的代表向量;获取基于业 务场景预设的聚类范围; 根据训练后的K-means模型,对所述聚类范围内的所述数值变量和所述代表向量 进行穷举聚类,生成多个用户聚类结果; 计算各所述用户聚类结果的轮廓系数,并确定最大轮廓系数的聚类结果为目标聚 类结果; 根据所述目标聚类结果,得到对应的用户画像结果。 一种计算机可读存储介质,其上存储有计算机程序,所述计算机程序被处理器执 行时实现以下步骤: 获取待分析的用户数据;所述用户数据包括数值变量和非数值变量; 利用实体嵌入的方式编码各所述非数值变量,将各所述非数值变量从语义空间映 6 CN 111597348 A 说 明 书 4/15 页 射至对应的向量空间; 从所述向量空间中确定与所述非数值变量对应的连续向量; 对所述连续向量进行训练,生成与各所述数值变量对应的代表向量;获取基于业 务场景预设的聚类范围; 根据训练后的K-means模型,对所述聚类范围内的所述数值变量和所述代表向量 进行穷举聚类,生成多个用户聚类结果; 计算各所述用户聚类结果的轮廓系数,并确定最大轮廓系数的聚类结果为目标聚 类结果; 根据所述目标聚类结果,得到对应的用户画像结果。 上述用户画像方法、装置、计算机设备和存储介质,通过获取待分析的用户数据, 包括数值变量和非数值变量,利用实体嵌入的方式编码各非数值变量,将各非数值变量从 语义空间映射至对应的向量空间,并从向量空间中确定与非数值变量对应的连续向量,通 过对连续向量进行训练,生成与各数值变量对应的代表向量,解决了传统K-Means模型无法 处理类别变量的问题。通过获取基于业务场景预设的聚类范围,并根据训练后的K-means模 型,对聚类范围内的数值变量和代表向量进行穷举聚类,生成多个用户聚类结果。通过计算 各用户聚类结果的轮廓系数,确定最大轮廓系数的聚类结果为目标聚类结果,根据目标聚 类结果,以提高针对不同用户的用户画像精确度,得到符合业务需求的用户画像结果。 附图说明 图1为一个实施例中用户画像方法的应用环境图; 图2为一个实施例中用户画像方法的流程示意图; 图3为一个实施例中计算各用户聚类结果的轮廓系数的流程示意图; 图4为一个实施例中预设的聚类范围下各用户聚类结果的轮廓系数分布示意图; 图5为一个实施例中用户聚类结果详细示意图; 图6为一个实施例中生成待分析的用户数据的流程示意图; 图7为一个实施例中数据类型识别逻辑示意图; 图8为一个实施例中用户画像装置的结构框图; 图9为一个实施例中计算机设备的内部结构图。











