
技术摘要:
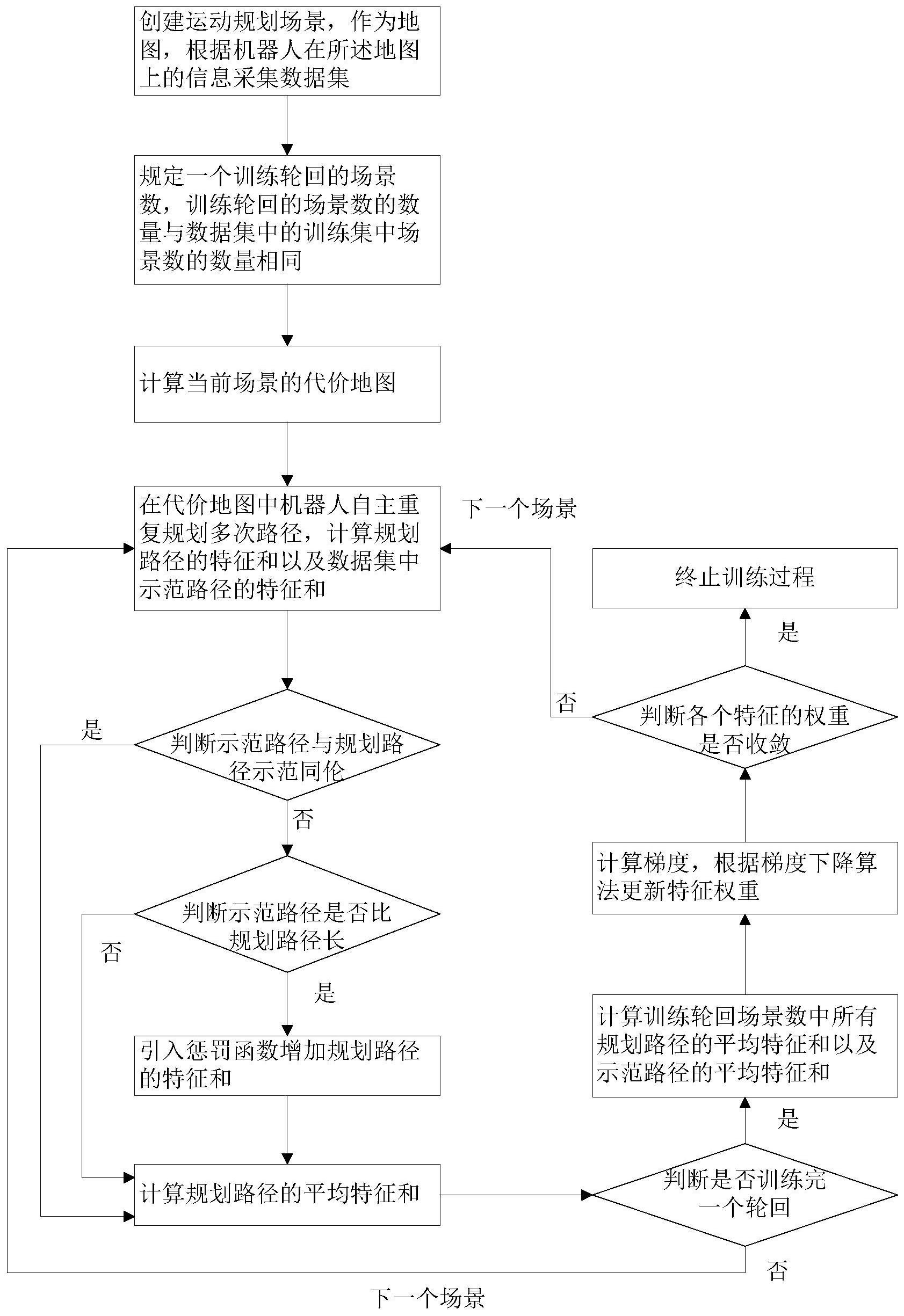
本发明涉及一种基于逆向强化学习的移动机器人拟人化路径规划方法,包括:创建运动规划场景,作为地图,根据机器人在所述地图上的信息采集数据集;规定一个训练轮回的场景数,所述训练轮回的场景数的数量与所述数据集中的训练集中场景数的数量相同;计算当前场景的代价 全部
背景技术:
人工智能技术的突破给移动型服务机器人研究带来了巨大的机遇,目前,引导机 器人、扫地机器人、导购机器人、货物搬运机器人等移动型服务机器人已经成功应用到了机 场、超市、博物馆、家庭等多种环境。移动型机器人路径规划是指在无人干预的条件下,在给 定的初始和目标点之间找到一条无碰撞且满足规定的各种约束的路径。相比于工业机器 人,人机共融环境下的移动机器人工作环境更加复杂,如何在复杂的动态人机共存环境中 高效快速地找到拟人化的最优运动轨迹是移动机器人要研究的重要问题之一。 然而,目前的大多数路径规划算法仅仅将周围行人看作动态障碍物,使得机器人 缺乏社会意识,忽视行人的感受,无法像人一样和其他行人交互,容易打断人们的交谈。因 此如何在路径规划过程中引入行人运动规则是拟人化路径规划算法要研究的重要问题,通 过专家示范路径学习行人运动规则是解决这一问题的有效手段。通过结合逆向强化学习与 路径规划器(path planner),实现行人运动特征的提取,进一步指导机器人路径规划。 当前,主要的路径规划算法可以大致分为以下五类:基于前向搜索的路径规划算 法、基于势场的路径规划算法、基于人工智能的路径规划算法、基于机器学习的路径规划算 法和基于随机采样的运动规划算法。其中,基于随机采样的路径规划算法避免了对状态空 间的建模,极大地减少了规划时间和内存成本,更适用于解决动态环境的路径规划问题。因 此逆向强化学习结合基于采样的路径规划算法能够更好地将行人的社会规范与路径规划 算法有机结合,准确高效地应用于动态人机共融环境中。 对于较为简单以及部分的复杂场景,逆向强化学习能够训练出一组收敛的权重指 导RRTS规划出与示范路径较为相符的路径。如图1a所示两个行人在相互接近,示范路径和 通过学习之后规划出的路径都能够避开行人,不打断行人之间的社交活动。 然而,随着场景中行人数量的增多、行人间运动情况更为复杂时,通过大规模场景 数量训练得到的权重规划出的路径会打断行人的行走和行人之间的社交活动,无法适用于 部分复杂场景。如图1b所示,行人1在向行人2前进的过程中,会被机器人规划出的路径所阻 碍,打断两人接近,而示范路径虽然较长,但是能够确保行人的行动不被干扰。相比而言,如 图1b所示,规划路径的表现较为僵硬,缺乏社会意识,忽视行人的感受,无法像人一样和其 他行人交互,容易打断人们的交谈,干扰行人原有的运动轨迹,行人往往需要对机器人的运 动进行妥协,缺乏自然舒适的交互体验。
技术实现要素:
为此,本发明所要解决的技术问题在于克服现有技术中易干扰行人正常行走与活 动,导致形成的轨迹路径不安全及舒适的问题,从而提供一种形成的轨迹路径安全及舒适 4 CN 111596668 A 说 明 书 2/8 页 的基于逆向强化学习的移动机器人拟人化路径规划方法。 为解决上述技术问题,本发明的一种基于逆向强化学习的移动机器人拟人化路径 规划方法,包括如下步骤:步骤S1:创建运动规划场景,作为地图,根据机器人在所述地图上 的信息采集数据集;步骤S2:规定一个训练轮回的场景数,所述训练轮回的场景数的数量与 所述数据集中的训练集中场景数的数量相同;步骤S3:计算当前场景的代价地图;步骤S4: 在所述代价地图中机器人自主重复规划多次路径,计算规划路径的特征和以及所述数据集 中示范路径的特征和;步骤S5:判断示范路径与规划路径是否同伦,若同伦,进入步骤S7,若 否,则继续判断示范路径是否比规划路径长,若是,进入步骤S6,若否,进入步骤S7;步骤S6: 引入惩罚函数增加规划路径的特征和;步骤S7:计算规划路径的平均特征和;步骤S8:判断 是否训练完一个轮回,若是,计算所述训练轮回场景数中所有规划路径的平均特征和以及 示范路径的平均特征和,进入步骤S9;若否,计算下一个场景的代价地图,返回步骤S4;步骤 S9:计算梯度,根据梯度下降算法更新特征权重,判断各个特征的权重是否收敛,若是,终止 训练过程,返回逆向强化学习最终学习到的特征权重,若否,计算下一个场景的代价地图, 返回步骤S4。 在本发明的一个实施例中,所述场景包括静态地图和行人位置、机器人的出发点 以及目标点、行人运动方向。 在本发明的一个实施例中,根据机器人在所述地图上的信息采集数据集的方法 为:在所述地图中设定机器人的起点和终点坐标,将终点坐标标注在地图上;控制机器人从 起点运行到终点,并记录机器人在运行过程中的数据。 在本发明的一个实施例中,所述数据包括传感器采集的环境信息、行人的坐标与 方向、机器人的初始位置、目标点的坐标。 在本发明的一个实施例中,所述传感器为激光雷达。 在本发明的一个实施例中,所述数据集还包括验证集。 在本发明的一个实施例中,所述代价地图的计算方法为:计算地图中每一个点的 各个特征对应的特征值,包括该点到目标点距离、该点到最近障碍物的距离、该点在行人模 型的位置对应的高斯模型代价值,遍历地图,计算得到特征代价地图。 在本发明的一个实施例中,机器人自主重复规划多次路径的方法为:每个场景重 复用RRT*算法产生多条规划路径。 在本发明的一个实施例中,所述惩罚函数为: ldemo、lmakeplan分别表示示范路径和规划路径 的长度。 在本发明的一个实施例中,终止训练过程,返回逆向强化学习最终学习到的特征 权重后,根据获得的特征权重进行路径规划,验证机器人在人机共融环境中的导航效果。 本发明的上述技术方案相比现有技术具有以下优点: 本发明所述的基于逆向强化学习的移动机器人拟人化路径规划方法,在逆向强化 学习的梯度计算中引入了惩罚函数对特征和之差进行惩罚,使训练得到的权重能够正确地 综合衡量路径长度、行人舒适度模型、到最近障碍物的距离,减少由于原本有所偏置的权重 产生干扰行人正常行走与活动的轨迹,形成更为安全可靠、自然舒适的路径。 5 CN 111596668 A 说 明 书 3/8 页 附图说明 为了使本发明的内容更容易被清楚的理解,下面根据本发明的具体实施例并结合 附图,对本发明作进一步详细的说明,其中 图1a是两条路径关于行人同伦的示意图; 图1b是两条路径关于行人不同伦的示意图; 图2是本发明基于逆向强化学习的移动机器人拟人化路径规划方法流程图; 图3a是静态环境地图示意图; 图3b是添加行人、起点(机器人所在的位置)、终点之后的训练用图; 图4是本发明数据集的采集示意图; 图5是人机共融环境模型的示意图; 图6a是导入逆向强化学习的原始数据集的示意图; 图6b是代价地图的示意图; 图7是非同伦检测原理示意图; 图8a是引入惩罚函数前的特征权重的收敛情况; 图8b是引入惩罚函数后的特征权重的收敛情况; 图9是引入惩罚函数改进后的通过逆向强化学习生成的路径。











