
技术摘要:
本申请提供了一种安全监测方法、装置、服务器、终端及可读存储介质,属于计算机技术领域。该方法包括:将第一目标场所的多个第一视频图像,分别输入至少两种第一图像识别模型,基于输出的至少两个人群密度信息确定目标图像识别模型,将多个第二视频图像输入目标图像识 全部
背景技术:
现如今,病毒的种类越来越多,变异能力也越来越强。大多数病毒均可以通过呼吸 道、飞沫、唾液等进行传播,传染性极高,给人们的健康造成了极大的威胁。在公共环境中, 人们可以通过佩戴口罩、保证一定的间隔距离等方式来进行防护,进而有效抑制病毒的传 播,保证自身及他人的安全。然而,仍有很多人不注意防护,因此需要安全管理人员对公共 环境中人群的防护情况,如人群聚集情况进行监督,以便及时对异常情况进行管理。 目前在对人群聚集情况进行检测时,主要是通过神经网络模型,对监控系统所采 集的监控图像进行识别,识别出监控图像中的人头,进而根据识别出的结果确定该监控图 像中的人群密度,并根据人群密度的大小将聚集的人头显示为不同的颜色,以便安全管理 人员确定人群聚集情况,在人群聚集较多时及时进行疏导。 在上述实现过程中,通过对人头进行检测来确定人群密度,很可能出现遮挡问题, 被遮挡的人头无法被识别到,进而导致确定出的人群密度不准确,安全监测的准确性较低。
技术实现要素:
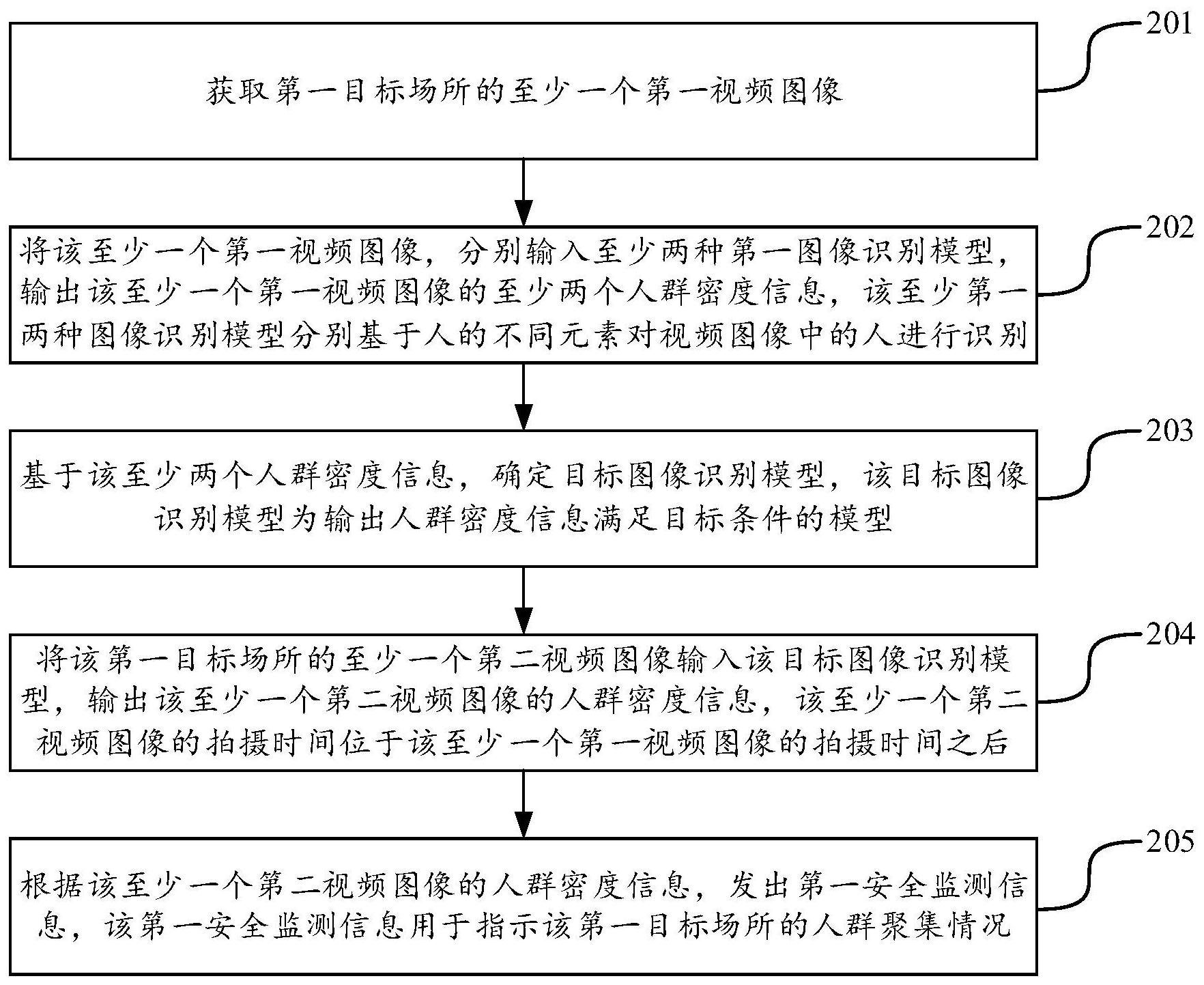
本申请实施例提供了一种安全监测方法、装置、服务器、终端及可读存储介质,可 以提高安全监测的准确性。该技术方案如下: 一方面,提供了一种安全监测方法,该方法包括: 获取第一目标场所的至少一个第一视频图像; 将该至少一个第一视频图像,分别输入至少两种第一图像识别模型,输出该至少 一个第一视频图像的至少两个人群密度信息,该至少两种第一图像识别模型分别基于人的 不同元素对视频图像中的人进行识别; 基于该至少两个人群密度信息,确定目标图像识别模型,该目标图像识别模型为 输出人群密度信息满足目标条件的模型; 将该第一目标场所的至少一个第二视频图像输入该目标图像识别模型,输出该至 少一个第二视频图像的人群密度信息,该至少一个第二视频图像的拍摄时间位于该至少一 个第一视频图像的拍摄时间之后; 根据该至少一个第二视频图像的人群密度信息,确定第一安全监测信息,该第一 安全监测信息用于指示该第一目标场所的人群聚集情况。 一方面,提供了一种安全监测方法,该方法包括: 显示安全监测界面,该安全监测界面包括人群聚集展示选项,该人群聚集展示选 项用于提供至少一个场所的人群聚集展示功能; 响应于对该人群聚集展示选项的触发操作,获取该至少一个场所的第一图像,该 6 CN 111556294 A 说 明 书 2/29 页 第一图像通过不同标注方式区分显示该场所的人群密度信息; 显示该至少一个场所的第一图像。 一方面,提供了一种安全监测装置,该装置包括: 第一获取模块,用于获取第一目标场所的至少一个第一视频图像; 模型处理模块,用于将该至少一个第一视频图像,分别输入至少两种第一图像识 别模型,输出该至少一个第一视频图像的至少两个人群密度信息,该至少两种第一图像识 别模型分别基于人的不同元素对视频图像中的人进行识别; 模型确定模块,用于基于该至少两个人群密度信息,确定目标图像识别模型,该目 标图像识别模型为输出人群密度信息满足目标条件的模型; 该模型处理模块,还用于将该第一目标场所的至少一个第二视频图像输入该目标 图像识别模型,输出该至少一个第二视频图像的人群密度信息,该至少一个第二视频图像 的拍摄时间位于该至少一个第一视频图像的拍摄时间之后; 第一信息确定模块,用于根据该至少一个第二视频图像的人群密度信息,确定第 一安全监测信息,该第一安全监测信息用于指示该第一目标场所的人群聚集情况。 在一种可能的实现方式中,该模型处理模块,用于将该至少一个第一视频图像,输 入至人头检测模型,通过该人头检测模型确定该至少一个第一视频图像中的人头位置,根 据该人头位置,确定该至少一个第一视频图像中的人群密度信息; 该模型处理模块,用于将该至少一个第一视频图像,输入至行人检测模型,通过该 行人监测模型确定该至少一个第一视频图像中的行人位置,根据该行人位置,确定该至少 一个第一视频图像中的人群密度信息; 该模型处理模块,用于将该至少一个第一视频图像,输入至人群密度估计模型,通 过该人群密度估计模型,确定该至少一个第一视频图像的人群密度图,根据该人群密度图, 确定该至少一个第一视频图像中的人群密度信息。 在一种可能的实现方式中,该模型处理模块,用于若至少两个人头位置对应的人 群密度信息满足预设条件,则输出该至少两个人头位置对应的人群密度信息,若该至少两 个人头位置对应的人群密度信息不满足预设条件,则基于与该至少两个人头位置满足预设 距离条件的下一个人头位置,确定该至少两个人头位置和该下一个人头位置对应的人群密 度信息。 在一种可能的实现方式中,该模型处理模块,用于若至少两个行人位置对应的人 群密度信息满足预设条件,则输出该至少两个行人位置对应的人群密度信息,若该至少两 个行人位置对应的人群密度信息不满足预设条件,则基于与该至少两个行人位置满足预设 距离条件的下一个行人位置,确定该至少两个行人位置和该下一个行人位置对应的人群密 度信息。 在一种可能的实现方式中,该至少一个第一视频图像携带校验标签; 该装置还包括: 第一检测模块,用于对获取到的视频图像携带的标签进行检测; 第一图像确定模块,用于若检测到获取到的视频图像携带该校验标签,则确定获 取到的视频图像为该第一视频图像,执行将该至少一个第一视频图像,分别输入至少两种 第一图像识别模型,输出该至少一个第一视频图像的至少两个人群密度信息的步骤。 7 CN 111556294 A 说 明 书 3/29 页 在一种可能的实现方式中,该装置还包括: 第二图像确定模块,用于若检测到获取到的视频图像未携带该校验标签,则确定 获取到的视频图像为该第二视频图像,执行将该第一目标场所的至少一个第二视频图像输 入该目标图像识别模型,输出该至少一个第二视频图像的人群密度信息的步骤。 在一种可能的实现方式中,该装置还包括: 解析模块,用于对接收到的视频图像进行解析; 添加模块,用于对解析得到的第一数量的视频图像添加校验标签,得到该至少一 个第一视频图像,对时序上位于该第一数量的视频图像之后的第二数量的视频图像不添加 校验标签,得到该至少一个第二视频图像。 在一种可能的实现方式中,该装置还包括: 第二检测模块,用于对该第一安全监测信息进行检测; 第一发出模块,用于若检测到该第一安全监测信息满足第一告警条件,则发出第 一告警信息,该第一告警信息用于指示该第一目标场所发生人群聚集。 在一种可能的实现方式中,该装置还包括: 第二获取模块,用于获取第二目标场所的视频图像; 第一识别模块,用于若该第二目标场所为目标类型场所,通过第二图像识别模型 对该视频图像进行识别,确定该视频图像中未佩戴口罩的人; 标注模块,用于对该视频图像中未佩戴口罩的人进行标注; 第二信息确定模块,用于根据该视频图像未佩戴口罩的人的数量,确定第二安全 监测信息,该第二安全监测信息用于指示该第二目标场未佩戴口罩的人的数量。 在一种可能的实现方式中,该识别模块,用于通过该第二图像识别模型中的人脸 检测模型,确定该视频图像中的人脸区域,截取该视频图像中的人脸区域,得到至少一个人 脸图像,通过该第二图像识别模型中的分类模型对该至少一个人脸图像进行识别,确定该 人脸图像对应的人是否佩戴口罩。 在一种可能的实现方式中,该装置还包括: 第三检测模块,用于对该第二安全监测信息进行检测; 第二发出模块,用于若检测到该第二安全监测信息满足第二告警条件,则发出第 二告警信息,该第二告警信息用于指示该第二目标场所有人未佩戴口罩。 在一种可能的实现方式中,该装置还包括: 第三获取模块,用于获取第三目标场所的视频图像; 第二识别模块,用于对该第三目标场所的视频图像进行识别,得到该第三目标场 所中不同场所单元的排队信息。 在一种可能的实现方式中,该装置还包括: 第四获取模块,用于获取第三目标场所中不同场所单元的视频图像; 第三识别模块,用于对该不同场所单元的视频图像进行识别,得到该第三目标场 所中不同场所单元的已承载比例信息。 一方面,提供了一种安全监测装置,该装置包括: 界面显示模块,用于显示安全监测界面,该安全监测界面包括人群聚集展示选项, 该人群聚集展示选项用于提供至少一个场所的人群聚集展示功能; 8 CN 111556294 A 说 明 书 4/29 页 第一获取模块,用于响应于对该人群聚集展示选项的触发操作,获取该至少一个 场所的第一图像,该第一图像通过不同标注方式区分显示该场所的人群密度信息; 第一图像显示模块,用于显示该至少一个场所的第一图像。 在一种可能的实现方式中,该第一获取模块,用于向服务器发送第一图像获取请 求,该第一图像获取请求携带该至少一个场所的场所标识,接收该服务器发送的该第一图 像。 在一种可能的实现方式中,该安全监测界面还包括口罩检测选项,该口罩检测选 项用于提供至少一个场所的人员口罩佩戴情况展示功能; 该装置还包括: 第二获取模块,用于响应于对该人群聚集展示选项的触发操作,获取该至少一个 场所的第二图像,该第二图像通过不同标注方式区分显示该场所中人是否佩戴口罩; 第二图像显示模块,用于显示该至少一个场所的第二图像。 在一种可能的实现方式中,该第二获取模块,用于向服务器发送第二图像获取请 求,该第二图像获取请求携带该至少一个场所的场所标识,接收该服务器发送的该第二图 像。 在一种可能的实现方式中,该装置还包括: 第一信息显示模块,用于响应于对第三目标场所的人群聚集展示指令,显示该第 三目标场所中不同场所单元的排队信息,该排队信息用于表示该场所单元中排队人员的聚 集情况。 在一种可能的实现方式中,该装置还包括: 第一发送模块,用于向服务器发送排队信息获取请求,该排队信息获取请求携带 该第三目标场所的场所标识; 第一接收模块,用于接收该服务器发送的该排队信息。 在一种可能的实现方式中,该装置还包括: 第二信息显示模块,用于响应于对第三目标场所的人群聚集展示指令,显示该第 三目标场所中不同场所单元内的已承载比例信息,该已承载比例信息用于表示该场所单元 的已承载人数占可承载人数总数的比例。 在一种可能的实现方式中,该装置还包括: 第二发送模块,用于向服务器发送已承载比例信息获取请求,该已承载比例信息 获取请求携带该第三目标场所的场所标识; 第二接收模块,用于接收该服务器发送的该已承载比例信息。 一方面,提供了一种服务器,该服务器包括一个或多个处理器和一个或多个存储 器,该一个或多个存储器中存储有至少一条程序代码,该程序代码由该一个或多个处理器 加载并执行以实现该安全监测方法所执行的操作。 一方面,提供了一种终端,该终端包括一个或多个处理器和一个或多个存储器,该 一个或多个存储器中存储有至少一条程序代码,该程序代码由该一个或多个处理器加载并 执行以实现该安全监测方法所执行的操作。 一方面,提供了一种计算机可读存储介质,该计算机可读存储介质中存储有至少 一条程序代码,该程序代码由处理器加载并执行以实现该安全监测方法所执行的操作。 9 CN 111556294 A 说 明 书 5/29 页 本申请提供的方案将获取到的第一目标场所的多个第一视频图像,分别输入至少 两种第一图像识别模型,基于输出的至少两个人群密度信息确定目标图像识别模型,将第 一目标场所的多个第二视频图像输入目标图像识别模型,输出多个第二视频图像的人群密 度信息,根据该至少一个第二视频图像的人群密度信息,确定第一安全监测信息。本申请通 过根据至少两种第一图像识别模型对监测初期所获取到的视频图像进行处理,以得到多个 模型所确定的人群密度信息,并基于上述确定的人群密度信息来进行目标图像识别模型的 选择,可以为后续监测过程选择更适合第一目标场所的模型,进而可以自适应的提高人群 密度信息的准确性,提高安全性。 附图说明 为了更清楚地说明本申请实施例中的技术方案,下面将对实施例描述中所需要使 用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本申请的一些实施例,对于 本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他 的附图。 图1是本申请实施例提供的一种安全监测方法的实施环境示意图; 图2是本申请实施例提供的一种安全监测方法的流程图; 图3是本申请实施例提供的一种安全监测方法的流程图; 图4是本申请实施例提供的一种安全监测方法的流程图; 图5是本申请实施例提供的一种视频图像的标签添加结果示意图; 图6是本申请实施例提供的一种确定人群密度信息的算法流程图; 图7是本申请实施例提供的一种安全监测方法的流程图; 图8是本申请实施例提供的一种口罩检测过程的技术流程图; 图9是本申请实施例提供的一种安全监测方法的流程图; 图10是本申请实施例提供的一种安全监测界面的示意图; 图11是本申请实施例提供的一种安全监测方法的流程图; 图12是本申请实施例提供的一种口罩佩戴情况总览界面的示意图; 图13是本申请实施例提供的一种口罩佩戴情况展示界面的示意图; 图14是本申请实施例提供的一种口罩佩戴情况展示界面的示意图; 图15是本申请实施例提供的一种安全监测方法的流程图; 图16是本申请实施例提供的一种排队情况总览界面的示意图; 图17是本申请实施例提供的一种排队情况展示界面的示意图; 图18是本申请实施例提供的一种安全监测方法的流程图; 图19是本申请实施例提供的一种电梯拥挤情况展示界面的示意图; 图20是本申请实施例提供的一种安全监测系统的架构图; 图21是本申请实施例提供的一种系统实现流程图; 图22是本申请实施例提供的一种安全监测装置的结构示意图; 图23是本申请实施例提供的一种安全监测装置的结构示意图; 图24是本申请实施例提供的一种终端的结构示意图; 图25是本申请实施例提供的一种服务器的结构示意图。 10 CN 111556294 A 说 明 书 6/29 页











