
技术摘要:
本发明公开了一种基于深度迁移学习模型的蘑菇识别方法,将基于深度学习的迁移学习与蘑菇识别相融合,通过迁移学习经典模型后,挑选精确率最高模型并对其进行模型调整,提取图像数据中的向量特征得到识别结果。本发明保留图像背景等环境因素实验得到95.1%的精确率,同 全部
背景技术:
蘑菇在很多省份都占据着农业的一定比例,像蘑菇大省山东省、黑龙江省等。因此 蘑菇识别有其必要性,该研究的完成有利于蘑菇产业的发展,惠及大量的菇农、菌类研究者 以及相关专业学生。从另外一种角度来说,每年因为误食毒蘑菇的人数逐步增加。 对于识别蘑菇种类现一般采用传统经验法,通常依赖于菌类研究者通过观察蘑菇 的菌丝、形态等多方面特征进行鉴别。此识别方法对识别者要求高,需要有相应的经验作为 知识支撑,并且不同蘑菇的特征各有差异,判断准确率受识别者主观影响,且误判率高。对 于过往的传统机器学习,特征提取过程中由于需要人工不断的进行实验与调整模型微参 数,实验趋势往往具有很大不确定性,需要花耗较大的时间计算成本。同时,目前许多现有 的智能识别方法仅停留在实验阶段,缺乏与用户进行交互的应用设计。 近年来,深度学习在图像识别、语音处理等多个研究方向上有许多新的突破。从近 年研究上可以看出,深度卷积神经网络可以从图像中学习出具有判别力的纹理特征,相较 于传统机器学习,深度学习模型的高效性与泛化性使其成为图像识别的一种有效方法。
技术实现要素:
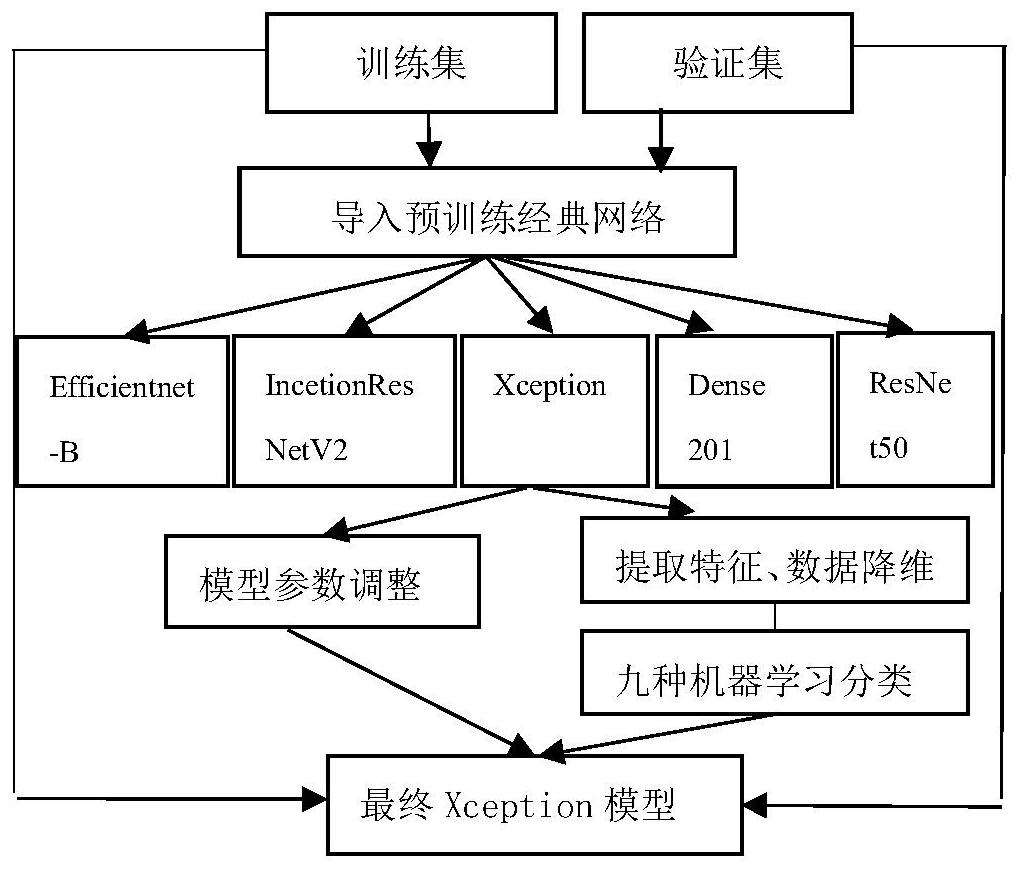
为了使判断者更加快速、简单、客观的得知结果,本发明提供了一种基于深度迁移 学习模型的蘑菇识别方法。该方法可以实现通过识别不同蘑菇的图片,达到蘑菇种类识别 的作用。 本发明的目的是通过以下技术方案实现的: 一种基于深度迁移学习模型的蘑菇识别方法,包括如下步骤: 步骤一、蘑菇数据集获取及其预处理: (1)根据数据集大小选择图像数据集中训练集与验证集的比例划分; (2)采用图像数据增强的方法对蘑菇图像数据进行处理,增加原始图像数据的样 本量; 步骤二、迁移学习: (1)选择在ImageNet大规模数据上预训练的Xception、 InceptionResNetV2、 Efficientnet-B3、Dense-201和ResNet50五种经典模型,将原始图像数据依次传入五个预 训练的网络中,寻找到最后验证集精度最高的一个网络作为实验基准模型; (2)网络迁移过程中,保持原模型及其权重参数不变,建立 BatchNormalization, 对模型输出进行归一化处理,之后建立不同大小全连接层,激活函数设为Relu函数; (3)搭建分类层,激活函数为Softmax函数,设置输出神经元个数; 步骤三、模型调整: 4 CN 111611924 A 说 明 书 2/9 页 (1)添加全连接层:对步骤二中通过初步实验得到的验证集精度最高的模型进行 微参数与结构调整处理,将其原最后一层对1000 种类进行分类替换为全连接层,并设置输 入与输出节点参数; (2)在全连接层中建立Dropout层,对数据进行过拟合处理,增加模型的泛化性; (3)模型编译时,采用余弦退火函数CosineAnnealingLR调整学习率; 步骤四、模型调整实验步骤: (1)调整模型微参数,以优化器种类、初始学习率为自变量分别进行实验; (2)对最优模型与搭建的全连接层设置不同初始学习率进行实验; (3)全新训练选中模型检测全新学习下实验的准确率,比较采用迁移学习模型参 数的优劣性; (4)特征降维、调整分类器:采用PCA/KPCA方式对最优模型的某层输出特征进行数 据降维处理,同时引入多种机器学习方法作为分类器对经过降维处理的特征进行训练,最 后采用K折交叉验证方法对机器学习分类模型的性能进行模型评价; (5)将蘑菇图像数据进行数据增强处理,并按照上述步骤三、步骤四内容依次进行 实验,寻找使得模型验证集精度最高的实验方案,同时对不同方案结果进行基于训练模型 时间参数和图像验证集精度参数的对比分析; 步骤五、模型结果预测与分析 (1)绘制混淆矩阵:利用混淆矩阵对验证集数据结果进行分析,并以此为条件进行 数据集的筛查与清理,同时观察不同种类数据之间的数据相关性情况; (2)计算每种蘑菇验证集图片平均识别速度,查看最优调整后的模型对数据集中 每一张图片的识别速度,并进行分类统计。 相比于现有技术,本发明具有如下优点: 1、本发明保留图像背景等环境因素实验得到95.1%的精确率,同时通过混合矩阵 图像说明了对于每类蘑菇识别率均达到了较高的水平,可以说明迁移学习对不同复杂环境 处理,模型鲁棒性强的优势。 2、本发明在识别蘑菇图像中,每类蘑菇平均识别时间均为0.013s,可以看出迁移 学习在图像识别速度上也具有相应的优势,在识别速度上有一定的进步。 3、对于过往的传统算法,特征提取过程中由于需要人工不断的进行实验与调整模 型微参数,实验趋势往往具有很大不确定性,需要花耗较大的时间计算成本。而迁移学习采 用已在大型数据集上预先训练好的模型参数作为模型训练初始参数代替随机初始化参数, 同时在此基础上再人工进行模型与参数调整,则可以较快速且有效的提高准确率,在有限 时间内可以训练出泛化性强的模型。 4、本发明对提取特征进行不同维度的数据降维处理,同时引入多种机器学习方法 进行分类。从训练模型时间参数与验证集精确率参数对结果进行对比分析,保证了实验对 比的多样性与图像识别的可靠性。 附图说明 图1为九类蘑菇图像与预处理图像对比图; 图2为Xception单网络初步实验结果; 5 CN 111611924 A 说 明 书 3/9 页 图3为Xception调整参数后实验图; 图4为PCA不同维度降维结果; 图5为混淆矩阵图;a、迁移学习,b、PCA_128 逻辑回归; 图6为系统整体框架; 图7为APP界面显示图,a、用户信息,b、上传图片,c、裁剪图片,d、返回信息; 图8为Xception完整网络结构图; 图9为实验过程。











