
技术摘要:
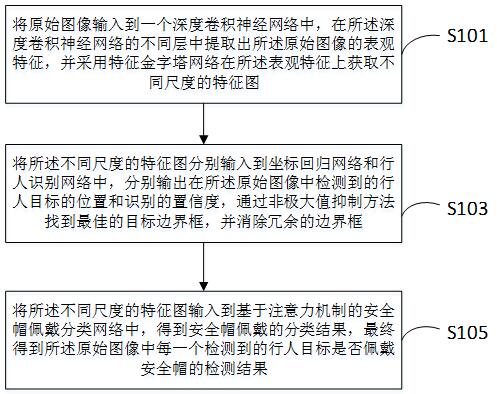
本发明公开了一种基于单模型预测的安全帽佩戴检测方法及装置,该方法包括将原始图像输入到一个深度卷积神经网络中,在深度卷积神经网络的不同层中提取出原始图像的表观特征,并采用特征金字塔网络在表观特征上获取不同尺度的特征图;将不同尺度的特征图分别输入到坐标 全部
背景技术:
安全帽佩戴在高温、供电线路、厂区和工地等作业场所中属于一项基本的安全防 范要求,与施工人员的人身安全密切相关。传统的通过人工监管的方式不仅会耗费过多的 人力,而且作业场所的复杂性使得监管难度非常大,这导致由于施工人员不佩戴安全帽而 引发的安全事故时有发生。针对这个问题,采用先进的人工智能技术来自动化识别施工人 员是否佩戴安全帽具有极大的必要性和实际价值。近些年来,基于深度卷积神经网络的目 标检测方法被应用于解决安全帽佩戴检测的问题。这类方法一般将安全帽佩戴与否作为两 种独立的目标,继而采用流行的检测方法来直接检测图像中佩戴和未佩戴安全帽的两类人 员,并以此作为每个检测出的人是否佩戴安全帽的识别结果。 现有的基于深度卷积神经网络的目标检测方法主要可分为两类:基于锚框的方法 和无锚框的方法。其中,基于锚框的方法又包括单阶段和两阶段两种类型。单阶段方法以 YOLO、SSD为代表,通过将目标检测看作回归过程直接在输入图像上预测目标类别及坐标信 息。两阶段方法以Faster RCNN最为典型,其通过区域生成网络得到候选区域,继而在此基 础上进行目标分类和坐标回归。 基于锚框的目标检测方法对所选框的尺寸、长宽比等较为敏感,且在目标形状变 化较大时检测效果不佳。针对这些问题,近年来无锚框的方法引起了众多研究人员的关注。 其中,代表性的无锚框目标检测方法有FCOS和CenterNet。这类方法不需要预设的锚框,直 接在CNN特征图上去预测角点、中心点或中心点到边界的距离来检测图像中的目标。由于没 有预设锚框,网络模型不易收敛,训练难度较大。 通过对现有技术方法的分析,发现当前的目标检测方法尽管在部分公开数据集上 有良好的效果,但其生成的检测模型还十分粗糙。在实际施工环境下,现有方法容易受到尺 度及光照变化等的影响,无法对复杂环境下目标是否佩戴安全帽的视觉语义进行有效表 达,这使得现有的检测方法在识别施工人员是否佩戴安全帽时难以取得较高的准确率。
技术实现要素:
本发明实施例的目的是提供了一种基于单模型预测的安全帽佩戴检测方法及装 置,以解决现有存在的安全帽佩戴检测精度不高的问题。 为了达到上述目的,本发明所采用的技术方案如下: 第一方面,本发明实施例提供一种基于单模型预测的安全帽佩戴检测方法,包括: 将原始图像输入到一个深度卷积神经网络中,在所述深度卷积神经网络的不同层中提 取出所述原始图像的表观特征,并采用特征金字塔网络在所述表观特征上获取不同尺度的 特征图; 5 CN 111723786 A 说 明 书 2/8 页 将所述不同尺度的特征图分别输入到坐标回归网络和行人识别网络中,分别输出在所 述原始图像中检测到的行人目标的位置和识别的置信度,通过非极大值抑制方法找到最佳 的目标边界框,并消除冗余的边界框; 将所述不同尺度的特征图输入到基于注意力机制的安全帽佩戴分类网络中,得到安全 帽佩戴的分类结果,最终得到所述原始图像中每一个检测到的行人目标是否佩戴安全帽的 检测结果。 进一步地,将原始图像输入到一个深度卷积神经网络中,在所述深度卷积神经网 络的不同层中提取出所述原始图像的表观特征,包括: 采用残差网络作为特征提取的主干网络,将所述原始图像输入到所述残差网络中,提 取出conv3、conv4、conv5层的最后一个残差block层输出的表观特征,分别记为{C3、C4、 C5}。 进一步地,采用特征金字塔网络在所述表观特征上获取不同尺度的特征图,包括: 特征金字塔网络包括四个层次,分别记为{P3、P4、P5、P6},各个层次的输入通过以下方 式得到: a) 将C5的表观特征输入到P5中; b) 将P5输出的特征图经过下采样后输入到P6中; c) 对P5输出的特征图进行上采样,通过相加的方式与C4的表观特征融合输入到P4中; d) 对P4输出的特征图进行上采样,通过相加的方式与C3的表观特征融合输入到P3中; 采用所述特征金字塔网络,经过四个层次后将输出四个不同尺度的特征图。 进一步地,将所述不同尺度的特征图分别输入到坐标回归网络和行人识别网络 中,分别输出在所述原始图像中检测到的行人目标的位置和识别的置信度,包括: 坐标回归网络包含若干个级联的卷积层,在训练过程中采用IOU loss作为回归损失 指导所述坐标回归网络的学习,计算公式如下: 其中, 与 分别表示预测及真值的目标框坐标, 为以e为底的对数函数, 表示所述目标框的面积; 将所述不同尺度的特征图输入到所述坐标回归网络中,输出在所述原始图像中检测到 的行人目标的位置; 行人识别网络包含若干个级联的卷积层,在训练过程中采用Focal loss作为分类损失 指导所述行人识别网络的学习,计算公式如下: 其中, 表示在 坐标位置输出的识别置信度(0-1之间), 表示所述坐标位置 上行人目标所属的类别标签; 将所述不同尺度的特征图输入到所述行人识别网络中,输出在所述原始图像中行人目 6 CN 111723786 A 说 明 书 3/8 页 标的识别的置信度。 进一步地,将所述不同尺度的特征图输入到基于注意力机制的安全帽佩戴分类网 络中,得到安全帽佩戴的分类结果,包括: a) 基于注意力机制的安全帽佩戴分类网络包含若干个级联的卷积层和注意力计算 层,在训练过程中,采用交叉熵损失作为安全帽佩戴分类损失 指导所述安全帽佩戴分 类网络的学习,计算公式如下: 其中, 表示所述安全帽佩戴分类网络在 坐标位置的预测结果, 表示所述 坐标位置上行人目标属于佩戴或未佩戴安全帽的类别标签, 为以自然常数e为底的指数 函数, 为以e为底的对数函数; b) 将所述不同尺度的特征图输入所述安全帽佩戴分类网络的卷积层中,提取出针对 安全帽分类的特征图,记为 ; c) 将所述不同尺度的特征图输入所述安全帽佩戴分类网络的注意力计算层中,得到 针对安全帽的注意力掩模,记为 ,通过如下方式将所述注意力掩模与所述一般特征图进 行融合,得到融合后的注意力特征图 : 其中, 表示逐元素点乘操作,是逐元素求和操作; d) 将所述注意力特征图 输入到一个2维卷积层中,输出安全帽佩戴的分类结果。 进一步地,最终得到所述原始图像中每一个检测到的行人目标是否佩戴安全帽的 预测结果,包括: 在训练阶段,所述安全帽佩戴检测网络共包含3个损失,即 、 和 ,通过加权 求和的方式得到最终的损失: 其中, 表示正样本的个数, 是一个指示函数,当 时为1,反之则为0, 基于计算得到的损失 ,对网络进行反向传播操作,并通过梯度下降算法来不断 更新网络参数,从而最终让网络的预测值逼近真实值; 在预测阶段,将所述原始图像输入到所述安全帽佩戴检测网络中,输出在所述原始图 像中检测到的行人目标的位置、识别的置信度和安全帽佩戴的分类结果,最终得到所述原 始图像中每一个检测到的行人目标是否佩戴安全帽的预测结果。 7 CN 111723786 A 说 明 书 4/8 页 第二方面,本发明实施例提供一种基于单模型预测的安全帽佩戴检测装置,包括: 提取模块,用于将原始图像输入到一个深度卷积神经网络中,在所述深度卷积神经网 络的不同层中提取出所述原始图像的表观特征,并采用特征金字塔网络在所述表观特征上 获取不同尺度的特征图; 输入输出模块,用于将所述不同尺度的特征图分别输入到坐标回归网络和行人识别网 络中,分别输出在所述原始图像中检测到的行人目标的位置和识别的置信度,通过非极大 值抑制方法找到最佳的目标边界框,并消除冗余的边界框; 检测模块,用于将所述不同尺度的特征图输入到基于注意力机制的安全帽佩戴分类网 络中,得到安全帽佩戴的分类结果,最终得到所述原始图像中每一个检测到的行人目标是 否佩戴安全帽的检测结果。 与现有技术相比,采用本发明所述的设计方案,能够取得以下有益效果: 1. 本发明基于单模型预测方法,能够在保证行人目标的检测精度的同时,对行人是否 佩戴安全帽进行准确地判断,兼顾了模型在推理过程中对速度和精度的要求。 2. 将安全帽佩戴分类与行人检测独立出来,通过不同的网络分支来完成对应的 任务,二者互不干扰,相比于直接检测佩戴和不佩戴安全帽的两类行人目标的方式,能够显 著提高安全帽佩戴识别的准确性。 3. 在安全帽佩戴分类网络中,利用注意力机制来更好地关注到安全帽相关的特 征区域,能够有效地提高安全帽佩戴分类的准确率。 附图说明 此处所说明的附图用来提供对本发明的进一步理解,构成本发明的一部分,本发 明的示意性实施例及其说明用于解释本发明,并不构成对本发明的不当限定。在附图中: 图1为本发明实施例提供的一种基于单模型预测的安全帽佩戴检测方法的流程图; 图2是本发明实施例中基于单模型预测的安全帽佩戴检测网络结构图; 图3是本发明实施例中基于注意力机制的安全帽佩戴分类网络结构图; 图4为本发明实施例提供的一种基于单模型预测的安全帽佩戴检测装置的结构示意 图。











