
技术摘要:
本发明公开了一种基于GBP的MM方法,上述方法能解决现有技术因为没有加入主成分析,对离散数据没有做到精准预测,且没有详细对现有用户行为与购买期望商品进行匹配,匹配度不高的问题;该方法是基于模型的聚类方法,是在概率模型中寻找参数最大似然估计的算法,其中概率 全部
背景技术:
随着电子商务网站的快速发展,推荐系统已经被广泛研究和应用,推荐系统通过 提取分析用户的资料、行为、评分等信息,获得用户的喜好,来帮助电商找到特定的用户为 其推荐可能购买的产品,增加商品的销售量。 推荐系统通过收集用户的历史评分、交互(浏览、收藏、“点赞”,“踩”等交互行为)、 用户肖像(年龄、职业、性别等)、社交网络和上下文(时间、位置、活动状态、周围人员等)等 数据,对用户的历史兴趣及偏好进行分析,挖掘出用户喜欢的项目(视频、音频、书籍、菜品、 Web服务等信息),然后主动地将相关信息推荐给用户,满足用户的个性化需求。推荐算法是 推荐系统的核心,很大程度上决定了推荐系统的性能。目前主要的推荐算法包括基于内容 的推荐、基于知识的推荐、基于关联规则的推荐、协同过滤推荐和组合推荐等。 目前被广泛研究的推荐系统有的是采用基于内容的推荐算法、协同过滤推荐算法 等。基于内容的推荐算法是通过用户购买过的产品的特征,为用户推荐与其相似的产品。这 种算法的优点是可以处理冷启动问题,处理新加入的产品,并且这种算法不会受到打分稀 疏性的问题,因为它不依赖于用户对产品的评分。但是它的缺点是无法处理像图形、视频和 音乐这种难以分析提取内容特征的商品。 协同过滤算法则是利用用户-产品评分矩阵,计算用户或产品之间的相似度,利用 相似度较高的邻居对其他产品进行评分预测,并根据预测评分的高低为目标用户进行推 荐。但是每一个用户购买的产品数量通常不到产品总数的1%,所以造成用户-产品评分矩 阵非常稀疏,从而使得推荐结果不佳;而基于邻域的协同过滤推荐算法是应用最早的协同 过滤推荐技术,代表性算法为基于用户的协同过滤推荐和基于项目的协同过滤推荐。然而 随着用户规模和项目数量的快速增长,基于邻域的协同过滤推荐算法的计算量大规模增 大,同时产生了严重的评分数据稀疏性问题,即评分稀疏性问题。为了处理可扩展性和评分 稀疏性问题,一些研究学者提出采用基于矩阵分解模型的推荐算法。矩阵分解模型假定“用 户—项目”评分矩阵可以被分解为低维的潜在特征矩阵的乘积,其中潜在特征用于表示用 户偏好或项目特征,如在电影推荐中,这些特征可能为喜剧、悬疑剧、爱情剧因素等。多次国 际性比赛和大量研究都验证了矩阵分解模型具有抗数据稀疏性、易编程、较低的时空复杂 度、较高的推荐精度和良好的可扩展性等优点。 虽然上述推荐方法各有优势,但是,上述推荐方法因为没有加入主成分析,对离散 数据没有做到精准预测;没有详细对现有用户行为与购买期望商品进行匹配,匹配度不高; 导致需要大量的硬匹配,没有形成完成回路;计算量巨大,占用大量服务器资源;需要二次 核对,同时匹配准确度有待加强。 3 CN 111581528 A 说 明 书 2/4 页
技术实现要素:
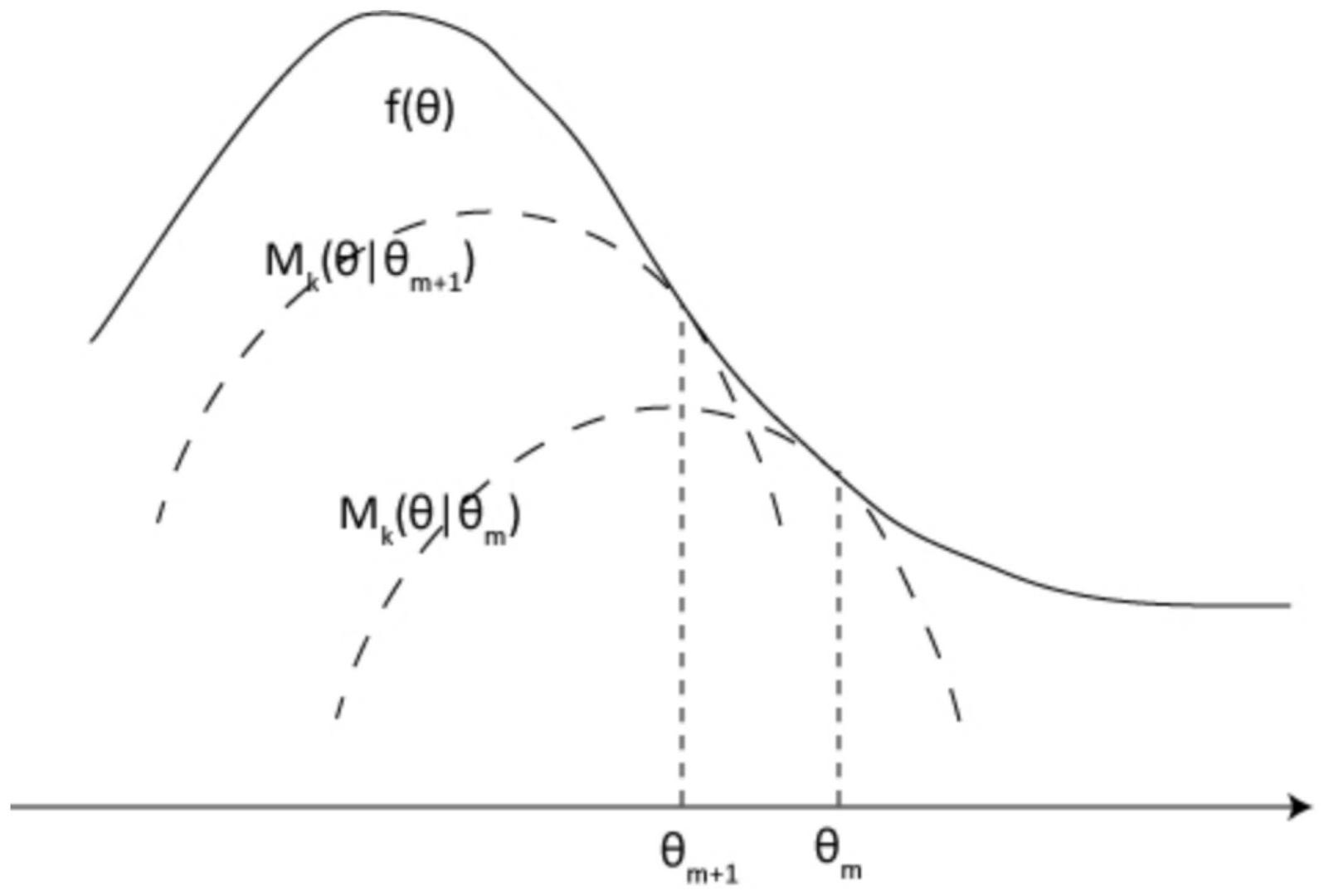
本发明所要解决的技术问题在于针对上述现有技术中的不足,提供一种基于GBP 的迭代优化推荐方法,上述推荐方法能解决现有技术因为没有加入主成分析,对离散数据 没有做到精准预测,且没有详细对现有用户行为与购买期望商品进行匹配,匹配度不高的 问题,该算法在迭代优化方法的基础上,通过将用户的基因(Gene),行为(Behavior),表型 (Phenotypic)这三类信息称之为用户的GBP数据,将这些数据进行标签化,进而形成以用户 为基础的GBP标签;将用户的GBP信息进行标签化后,再将内容(商品、文章、视频、图片等)信 息进行标签化,进而将用户的GBP标签和内容的标签进行算法层面的匹配;本发明中将上述 算法称为基于GBP的MM算法推荐,MM算法是一种迭代优化方法,利用函数的凸性来寻找它们 的最大值或最小值;MM表示“majorize-minimizeMM算法”或“minorizemaximizeMM算法”,取 决于需要的优化是最大化还是最小化;结合GBP进行MM算法优化,寻找到用户推荐的最大相 关性。 为实现上述发明目的,本发明采用如下的技术方案: 一种基于GBP的迭代优化推荐方法,包含以下步骤: 1)根据用户的GBP数据对用户进行标签化,每个用户就都拥有了各自的GBP标签, 每个标签代表一个不同的item; 2)对内容进行手动打标签,使内容也拥有了一个或多个标签: 3)根据用户的标签和内容标签进行初步的匹配,经过用户使用、反馈和算法校准, 用户已经对一些item做出了喜好判断,喜欢其中的一部分item,不喜欢其中的另一部分; 4)通过用户过去的喜好判断,为用户形成一个通用模型,后续根据用户的实习操 作的数据反馈进行标签权重系数的调整进而优化推荐系统的推荐机制: 5)商品推荐,通过上述通用模型,就可以判断用户是否会喜欢一个新的item,最终 得到推荐结果; 其中,所述的内容为文章、视频、商品、图片等; 其中,通用模型的目标函数f(θ)较难优化时,算法不直接对目标函数求最优化解, 转而寻找一个易于优化的目标函数g(θ)替代,然后对这个替代函数求解,g(θ)的最优解逼 近于f(θ)的最优解,每迭代一次,根据所求解构造用于下一次迭代的新的替代函数,然后对 新的替代函数最优化求解得到下一次迭代的求解。通过多次迭代,可以得到越来越接近目 标函数最优解的解。从而从根本数据分析角度,解决现有人与物的推荐问题; 其中,在算法的第m(m=0,1...)步,若满足以下条件,则目标函数f(θm)可用构造 函数gm(θm)代替;(1)gm(θ)≤f(θm),(2)θgm(θ)≤f(θm);(3)θgm(θm)=f(θm)gm(θm)=f(θ m); 步骤1.使m=1m=1,并初始化θ0; 步骤2.构造gm(θ)满足条件(1)和(2); 步骤3.令θm 1=argminθgm(θ); 步骤4使m=m 1,返回步骤2; 由上可以推到出:f(θm 1)≥gm(θm 1)≥g(θm|θm)=f(θm); 本发明与现有技术相比具有以下优点:本发明解决了现有技术中的推荐方法因为 没有加入主成分析,对离散数据没有做到精准预测;没有详细对现有用户行为与购买期望 4 CN 111581528 A 说 明 书 3/4 页 商品进行匹配,匹配度不高;导致需要大量的硬匹配,没有形成完成回路;计算量巨大,占用 大量服务器资源;需要二次核对,同时匹配准确度有待加强的问题;该推荐方法是一种基于 模型的聚类方法,是在概率模型中寻找参数最大似然估计方法,其中概率模型依赖于无法 观测的隐藏变量;该方法比一般k-mean算法准确、稳定;能完全独立于查询,只依赖于网页 链接结构,可以离线计算;非常灵活,可以允许有部分错分成本,还可指定先验概率分布,可 使用自动的成本复杂性剪枝来得到归纳性更强。 附图说明 图1为本发明中的目标函数f(θm)的优化示意图; 图2为本发明中的推荐方法示意图。











