
技术摘要:
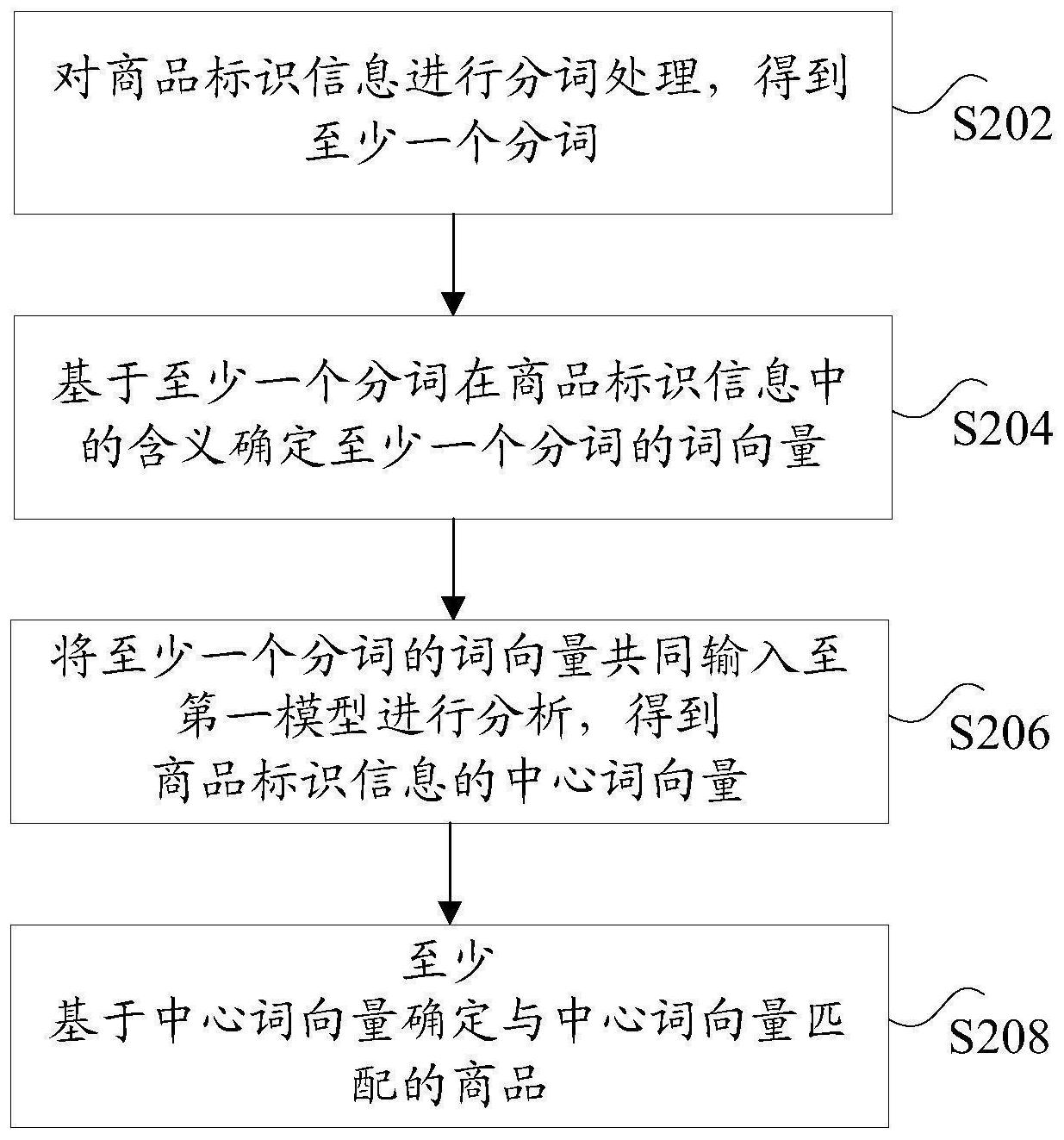
本申请公开了一种商品数据的处理方法、装置和系统。其中,该方法包括:对商品标识信息进行分词处理,得到至少一个分词;基于至少一个分词在商品标识信息中的含义确定至少一个分词的词向量;将至少一个分词的词向量共同输入至第一模型进行分析,得到商品标识信息的中心 全部
背景技术:
随着计算机技术的发展,人们可以通过互联网实现远程购物。计算机技术不仅为 人们的日常购物提供了方便,还使得电商能够了解到客户的需求,为客户的需求提供更好 的服务。例如,对于电商平台,当客户输入“Mini Bluetooth Speaker”是搜索词之后,电商 平台能够准确的为客户提供的蓝牙音箱。 通过中心词提取可实现对用户输入的搜索词进行关联,进而确定用户需求的目 的。通过提取搜索信息和商品标题的中心词,进而完成中心词的匹配,匹配的分数决定了搜 索词与商品的相关程度。在电商的特定场景,存在着大量的商品数据,这些数据全部来自于 卖家自己填写。电商平台通过利用这些大规模的语料数据预训练模型,进而提升有监督模 型中心词任务的效果,其中,大规模语料的预训练模型使用的是word2vec或随机初始化模 型,该预训练模型未考虑到搜索词在不同上下文环境中可能有不同的含义。 另外,由上述内容可知,现有的大规模语料的预训练模型完全借助人工标注数据, 对于电商平台的搜索信息以及商品标题各提取一部分,然后通过人工标注的方式进行标 注,直接在此基础上进行学习得到一个模型,该预训练模型的标注数据依赖人工生成,成本 高,数据迁移代价高,如果出现新的场景则需要重新进行标注和生产。另外如果电商平台的 商品集合和搜索信息集合发生变化,标注数据则需要重新进行标注,代价较高,如果后期需 要继续提升效果,所需标注数据量会呈指数集增加,边际成本较高。 针对上述的问题,目前尚未提出有效的解决方案。
技术实现要素:
本申请实施例提供了一种商品数据的处理方法、装置和系统,以至少解决现有技 术未考虑到商品标识信息的上下文含义,从而导致商品匹配度低的技术问题。 根据本申请实施例的一个方面,提供了一种商品数据的处理方法,包括:对商品标 识信息进行分词处理,得到至少一个分词;基于至少一个分词在商品标识信息中的含义确 定至少一个分词的词向量;将至少一个分词的词向量共同输入至第一模型进行分析,得到 商品标识信息的中心词向量,其中,通过多组数据对第一模型进行训练,多组数据中的每组 数据中均包括:样本词向量和用于标识样本词向量为中心词的标签;至少基于中心词向量 确定与中心词向量匹配的商品。 根据本申请实施例的另一方面,还提供了一种商品数据的处理方法,包括:对商品 标识信息进行分词处理,得到至少一个分词;基于至少一个分词在商品标识信息中的含义 确定至少一个分词的词向量;将至少一个分词的词向量共同确定商品标识信息的中心词向 量;至少基于中心词向量确定与中心词向量匹配的商品。 5 CN 111597296 A 说 明 书 2/15 页 根据本申请实施例的另一方面,还提供了一种商品数据的处理装置,包括:分词模 块,用于对商品标识信息进行分词处理,得到至少一个分词;第一确定模块,用于基于至少 一个分词在商品标识信息中的含义确定至少一个分词的词向量;分析模块,用于将至少一 个分词的词向量共同输入至第一模型进行分析,得到商品标识信息的中心词向量,其中,通 过多组数据对第一模型进行训练,多组数据中的每组数据中均包括:样本词向量和用于标 识样本词向量为中心词的标签;第二确定模块,用于至少基于中心词向量确定与中心词向 量匹配的商品。 根据本申请实施例的另一方面,还提供了一种商品数据的处理系统,包括:服务 器,用于接收查询请求,并从查询请求中提取商品标识信息;对商品标识信息进行分词处 理,得到至少一个分词;基于至少一个分词在商品标识信息中的含义确定至少一个分词的 词向量;将至少一个分词的词向量共同输入至第一模型进行分析,得到商品标识信息的中 心词向量,其中,通过多组数据对第一模型进行训练,多组数据中的每组数据中均包括:样 本词向量和用于标识样本词向量为中心词的标签;至少基于中心词向量确定与中心词向量 匹配的商品;客户端设备,用于向服务器发送查询请求,其中,该查询请求中携带有待检索 的商品标识信息。 根据本申请实施例的另一方面,还提供了一种存储介质,该存储介质包括存储的 程序,其中,在程序运行时控制存储介质所在设备执行上述的商品数据的处理方法。 根据本申请实施例的另一方面,还提供了一种处理器,该处理器用于运行程序,其 中,程序运行时执行上述的商品数据的处理方法。 根据本申请实施例的另一方面,还提供了一种计算机设备,包括:处理器;以及存 储器,与处理器连接,用于为处理器提供处理以下处理步骤的指令:对商品标识信息进行分 词处理,得到至少一个分词;基于至少一个分词在商品标识信息中的含义确定至少一个分 词的词向量;将至少一个分词的词向量共同输入至第一模型进行分析,得到商品标识信息 的中心词向量,其中,通过多组数据对第一模型进行训练,多组数据中的每组数据中均包 括:样本词向量和用于标识样本词向量为中心词的标签;至少基于中心词向量确定与中心 词向量匹配的商品。 根据本申请实施例的另一方面,还提供了一种计算机设备,用于提供人机交互界 面,人机交互界面包括:第一控件,用于展示对商品标识信息进行分词处理得到的至少一个 分词;第二控件,用于展示基于至少一个分词在商品标识信息中的含义确定的至少一个分 词的词向量;第三控件,用于展示将至少一个分词的词向量共同输入至第一模型进行分析, 得到的商品标识信息的中心词向量,其中,通过多组数据对第一模型进行训练,多组数据中 的每组数据中均包括:样本词向量和用于标识样本词向量为中心词的标签;第四控件,用于 展示至少基于中心词向量确定与中心词向量匹配的商品。 在本申请实施例中,采用分词在商品标识信息中的含义对商品数据进行处理的方 式,在对商品标识信息进行分词处理,得到至少一个分词之后,服务器基于至少一个分词在 商品标识信息中的含义确定至少一个分词的词向量,并将至少一个分词的词向量输入至第 一模型进行分析,以得到商品标识信息的中心词向量,最后,基于中心词向量确定与中心词 向量匹配的商品。 在上述过程中,在确定与商品标识信息匹配的商品的过程中,通过对分词在商品 6 CN 111597296 A 说 明 书 3/15 页 标识信息中的含义来确定词向量,并根据词向量来确定中心词向量。由于考虑到了分词在 商品标识信息中的上下文含义,达到了对商品标识信息进行识别的目的,解决了一词多义 的问题,使得商品标识信息的中心词向量的确定更加准确,从而实现了提高商品匹配度的 技术效果。 由此可见,本申请所提供的方案解决了现有技术未考虑到商品标识信息的上下文 含义,从而导致商品匹配度低的技术问题。 附图说明 此处所说明的附图用来提供对本申请的进一步理解,构成本申请的一部分,本申 请的示意性实施例及其说明用于解释本申请,并不构成对本申请的不当限定。在附图中: 图1是根据本申请实施例的一种可选的计算机终端的硬件结构框图; 图2是根据本申请实施例的一种商品数据的处理方法的流程图; 图3是根据本申请实施例的一种可选的商品数据的处理方法的系统框架图; 图4是根据本申请实施例的一种商品数据的处理方法的流程图; 图5是根据本申请实施例的一种商品数据的处理装置的示意图; 图6是根据本申请实施例的一种商品数据的处理系统的示意图;以及 图7是根据本申请实施例的一种计算机终端的结构框图。











