
技术摘要:
本发明属于自然语言处理技术领域,公开了一种行为训练对话控制方法、系统、存储介质、程序、终端,用户的自然语言输入并解析其意图,输出{intent:value,slot:value,…}结构化数据;根据结构化数据对知识库中的内容进行查找,将返回的结果输入对话策略管理子模块决定下 全部
背景技术:
目前,当前的对话系统按照应用场景可以分为三类,分别是任务型对话系统、问答 型对话系统和闲聊型对话系统。任务型对话系统有明确的目标,侧重点在于完成用户指定 的任务,如电影票预订系统。问答型对话系统是针对用户提出的问题给出答案,如专家咨询 系统。闲聊型对话系统没有明确的目的和任务,与用户能够顺畅的进行交互即可,如微软的 小冰。最近几年,在对话系统相关任务中引入深度强化学习的方法也越来越受到相关研究 者的关注,深度强化学习是利用深度神经网络来表示强化学习基本算法Q函数,以便从原始 对话输入中自动学习合理的对话策略。于此同时,注意力模型的提出在深度神经网络中引 入了一种动态赋权的机制,模拟人脑处理外部输入信息时关注某些重要信息并进行有意识 思索的高级认知机制。父母行为管理训练被认为是目前儿童多动症治疗的最佳方法。多动 症儿童的父母渴望获得有效的指导以便来处理多动症儿童的行为问题,但通常父母和医师 的交流方式为线下的面对面交流,这就需要父母投入更多的时间和精力,并且当父母面对 孩子的不理智举动时得不到及时有效的指导。基于这种需求,我们构建的对话系统可以辅 助父母做出正确且恰当的应对方法。 儿童多动症行为表现出频发性、多因性、时空随意性,以及干预治疗时效性等特 点,对传统基于线下的多动症行为训练造成了极大的困难。传统对话系统一般由自然语言 理解、对话管理、自然语言生成三个模块组成,自然语言理解在给定用户表述的情况下负责 识别用户意图;对话管理负责追踪用户状态和采取系统行为;自然语言生成负责将系统行 为转换为人类语言。为了能够对对话系统采取端到端的训练,引入了用户模拟器来模拟人 和系统之间的对话。现有技术中,使对话系统性能不佳的两个主要问题是:将自然语言解析 成结构化语义并理解其句子含义的能力不强,对话过程中的前后流畅度低导致用户体验不 好,这阻碍了对话系统在各个实际场景下的推广和使用。 通过上述分析,现有技术存在的问题及缺陷为: (1)传统对话系统将自然语言解析成结构化语义并理解其句子含义的能力不强, 训练数据稀疏,导致模型不能学习到有效的词语向量表征,进而不能合理表征语句的语义。 (2)传统对话系统对话过程中的前后流畅度低导致用户体验不好,阻碍了对话系 统在各个实际场景下的推广和使用。 解决以上问题及缺陷的难度为: (1)训练数据获取难度大。数据稀疏导致模型不能获取自然词汇的有效向量表征, 进而影响语义解析。 (2)传统对话系统依赖场景的设计来提高人机对话流畅度,但多数封闭域对话任 务并非完全封闭,例如本发明关注的多动症行为训练对话任务中可出现的场景与对话模式 4 CN 111611378 A 说 明 书 2/8 页 难以枚举。 解决以上问题及缺陷的意义为: (1)数据稀疏是阻碍机器学习模型性能进一步提升的最大瓶颈。高效、自动化的数 据获取技术是模型迭代升级、可持续智能化的保障。 (2)摆脱静态的场景设计,通过强化学习、对抗学习等技术构建自适应的对话策略 将提高人机对话成功率及用户体验,是多轮对话系统实现落地的重要因素。
技术实现要素:
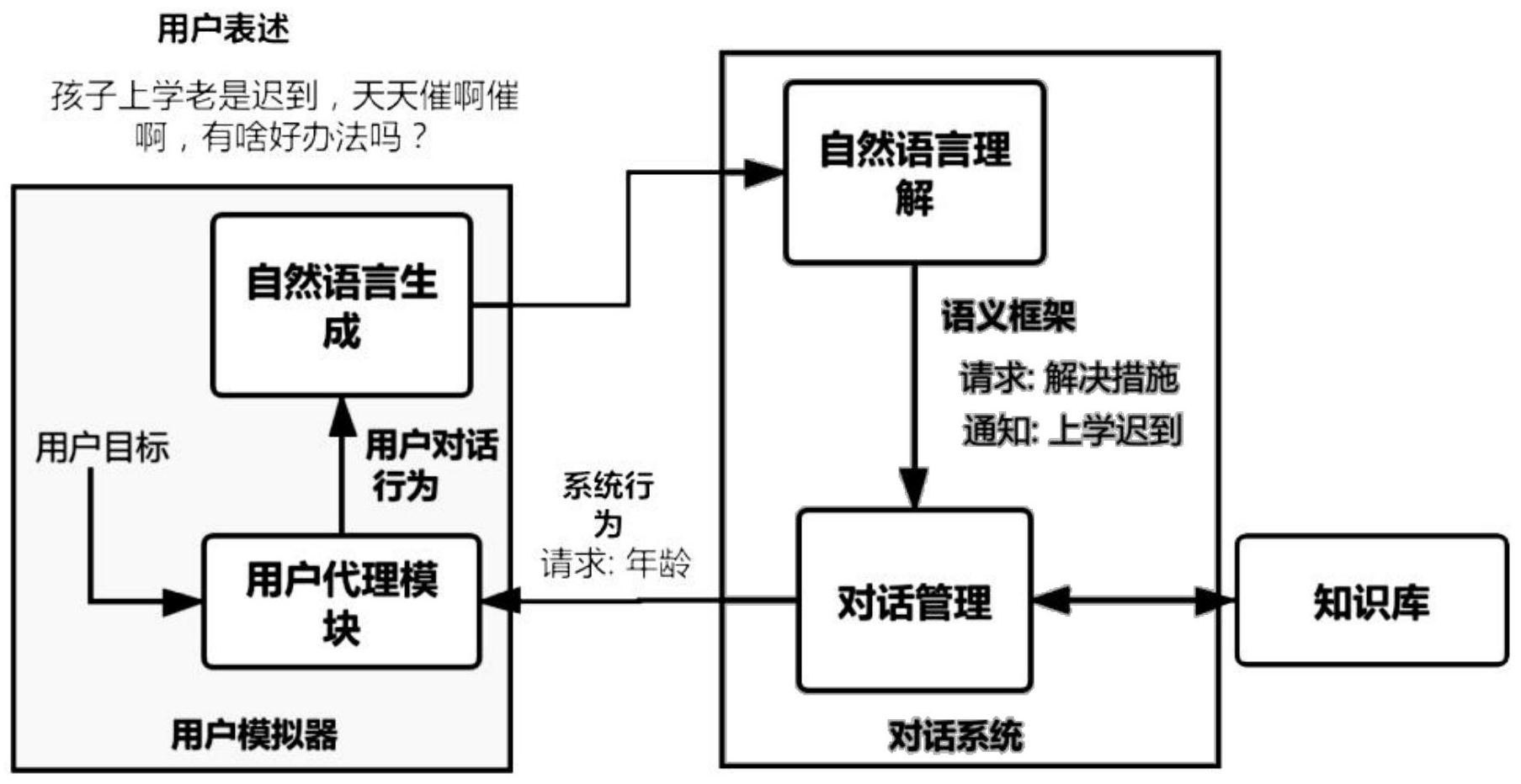
针对现有技术存在的问题,本发明提供了一种行为训练对话控制方法、系统、存储 介质、程序、终端。 本发明是这样实现的,一种行为训练对话控制方法,所述行为训练对话控制方法 包括: 第一步,用户的自然语言输入并解析其意图,输出{intent:value ,slot: value,…}结构化数据;输入数据的格式是序列,如一句话‘带孩子去医院验血,孩子坚决不 肯’,对这句话进行三个任务,分别是领域分类、意图识别、槽填充。领域分类的结果是医疗 领域,意图识别的结果是验血,槽填充的结果是{‘地点’:医院,‘行为’:验血,‘状态’:拒 绝}。形成结构化数据后输入到对话管理模块,在对话管理模块首先进行状态的更新,即根 据传入的结构化数据更新当前状态,如传入了地点、行为、状态值,当前的对话状态新增这 几个槽位。然后根据新的对话状态做出决策,如是询问新的信息,还是确认输入,或者给出 答复。这一动作需要对知识库进行查询,在知识库中如果预定义的槽位已经获得相应的值, 则返回匹配的答案,如果有槽位的值没有确定,则询问相应的值; 第二步,根据结构化数据对知识库中的内容进行查找,将返回的结果输入对话策 略管理子模块决定下一时刻对话系统的输出; 第三步,根据用户目标数据结构中预定义内容生成下一个问句。 进一步,所述行为训练对话控制方法收集多轮对话获取父母自描述之外的信息。 进一步,所述行为训练对话控制方法还包括:基于强化学习技术对话管理、基于深 度神经网络的自然语言理解、在一个专业对话数据集之上建立的规则库。 进一步,所述行为训练对话控制方法使用机器学习技术对多动症儿童的行为表现 建模,并根据日常使用中的用户反馈动态地调整对话策略和问题响应机制。 进一步,所述行为训练对话控制方法还包括: 步骤一、使用文字、语音、影像方式收集多动症儿童、父母和医师之间关于多动症 问题的询问和指导方法的记录数据,并将数据结构化为可支持问答系统查询的知识库形 式; 步骤二、将深度神经网络技术、强化学习技术分别应用于对话系统的自然语言理 解模块和对话管理模块; 步骤三、采用在线模式,验证知识库中对于多动症儿童行为问题的指导方案在父 母实际使用中的有效性,并通过父母的反馈动态的优化方案。 进一步,所述行为训练对话控制方法收集后的数据基于经过领域专家验证过的自 动化程序,包括: 5 CN 111611378 A 说 明 书 3/8 页 行为标注:对于行为的识别,采用BIO模式,对话语料中的每个中文字符都分配一 个B、I或O标签; 行为分类:在标注行为之后,将得到的行为模式进行手动的分类,类别的确定也由 领域专家依据标注一致性原则执行。 本发明的另一目的在于提供一种计算机设备,所述计算机设备包括存储器和处理 器,所述存储器存储有计算机程序,所述计算机程序被所述处理器执行时,使得所述处理器 执行如下步骤: 第一步,用户的自然语言输入并解析其意图,输出{intent:value ,slot: value,…}结构化数据; 第二步,根据结构化数据对知识库中的内容进行查找,将返回的结果输入对话策 略管理子模块决定下一时刻对话系统的输出; 第三步,根据用户目标数据结构中预定义内容生成下一个问句。 本发明的另一目的在于提供一种计算机可读存储介质,存储有计算机程序,所述 计算机程序被处理器执行时,使得所述处理器执行如下步骤: 第一步,用户的自然语言输入并解析其意图,输出{intent:value ,slot: value,…}结构化数据; 第二步,根据结构化数据对知识库中的内容进行查找,将返回的结果输入对话策 略管理子模块决定下一时刻对话系统的输出; 第三步,根据用户目标数据结构中预定义内容生成下一个问句。 本发明的另一目的在于提供一种运行所述行为训练对话控制方法的行为训练对 话控制系统,所述行为训练对话控制系统包括: 自然语言处理模块,用于接受用户的自然语言输入并解析其意图,输出{intent: value,slot:value,…}结构化数据; 对话管理模块,用于接受自然语言处理模块的输出,根据结构化数据对知识库中 的内容进行查找,将返回的结果输入对话策略管理子模块决定下一时刻对话系统的输出; 用户模拟器,用于接受对话系统的输出,并根据用户目标数据结构中预定义内容 生成下一个问句。 本发明的另一目的在于提供一种终端,所述终端搭载所述的行为训练对话控制系 统。 结合上述的所有技术方案,本发明所具备的优点及积极效果为:本发明的对话系 统的训练基于一个领域专家标注的多动症儿童治疗方案对话数据集,该数据集由两个部分 组成:一个是多动症儿童父母关于孩子行为表现的自报告;另一个是父母与行为训练专家 关于此类问题的治疗方案分享对话记录,所有数据的采集和使用经过了所有方的授权与数 据脱敏工作。 本发明构建了一个基于强化学习的对话系统,该系统针对多动症儿童的行为问题 给出父母相应的指导措施。在真实情景下的实验结果表明应用强化学习提高了对话的成功 率同时也能够为儿童行为训练提供解决方法。 本发明方法与现有技术在儿童多动症对话测试集上的性能对比如表1所示。 表1 6 CN 111611378 A 说 明 书 4/8 页 附图说明 为了更清楚地说明本申请实施例的技术方案,下面将对本申请实施例中所需要使 用的附图做简单的介绍,显而易见地,下面所描述的附图仅仅是本申请的一些实施例,对于 本领域普通技术人员来讲,在不付出创造性劳动的前提下还可以根据这些附图获得其他的 附图。 图1是本发明实施例提供的行为训练对话控制方法流程图。 图2是本发明实施例提供的行为训练对话控制系统的结构示意图; 图中:1、自然语言处理模块;2、对话管理模块;3、用户模拟器。 图3是本发明实施例提供的行为训练对话控制系统的原理图。 图4是本发明实施提供的自然语言理解模块结构图。 图5是本发明实施提供的对话管理模块结构图。 图6是本发明实施提供的自然语言生成结构图。











