
技术摘要:
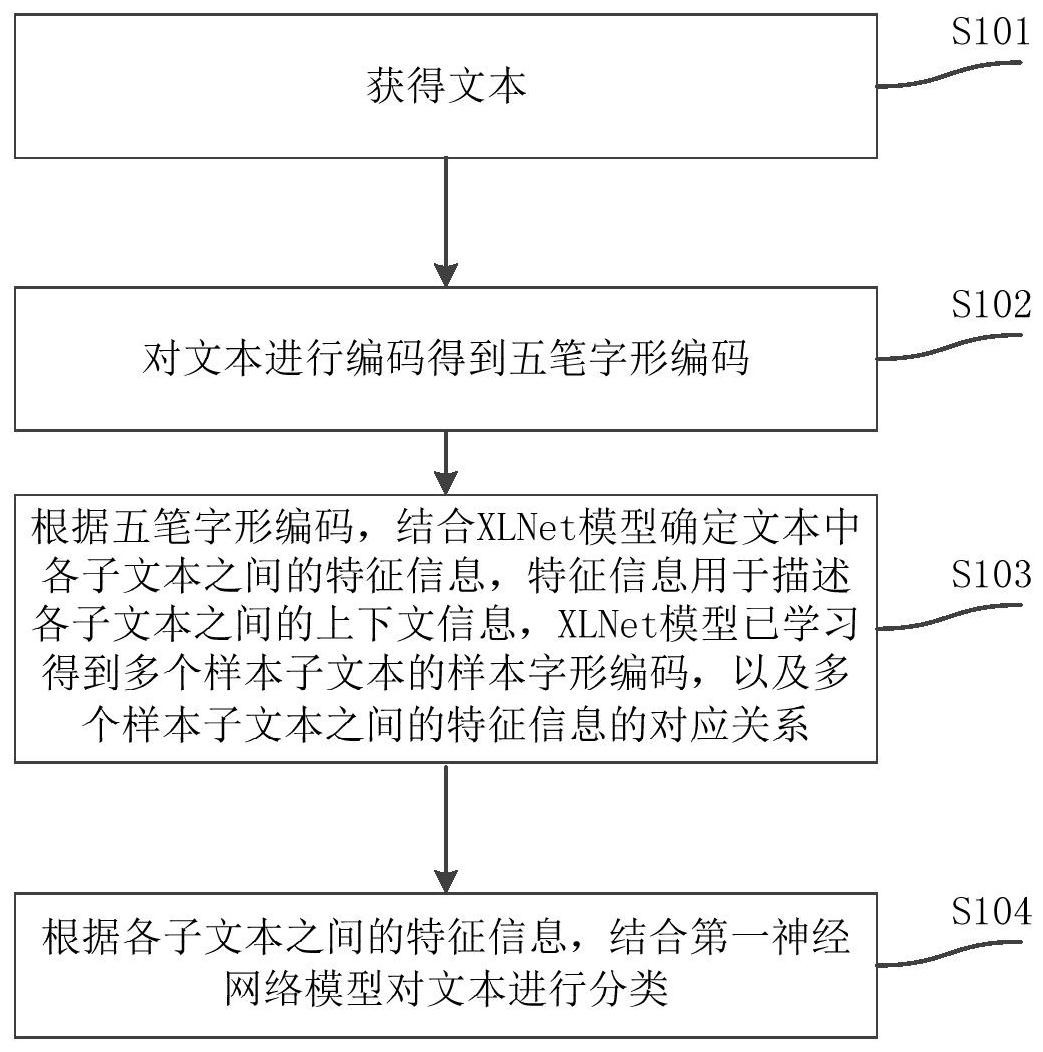
本发明提出一种文本分类方法、装置、存储介质及计算机设备,文本为中文文本,该方法包括获得文本;对文本进行编码得到五笔字形编码;根据五笔字形编码,结合XLNet模型确定文本中各子文本之间的特征信息,特征信息用于描述各子文本之间的上下文信息,XLNet模型已学习得 全部
背景技术:
在自然语言处理技术领域中,通常会执行一些文本分类任务从而辅助如信息检 索,新闻主题分类,垃圾邮件分类、情感分析、自动问答系统中的问句分类等。而文本分类通 常包括三种分类类型:二分类问题,多分类问题以及多标签问题,比如判断邮件是否为垃圾 邮件,属于一个二分类问题;比如判断新闻主题是娱乐、体育、还是社会,属于一个多分类问 题;比如基于案件事实描述文本的法条分类,属于多标签分类问题。 相关技术中,通常采用TF-IDF、词嵌入池化,或者是CNN(Convolutional Neural Networks,神经卷积网络)模型等对文本进行分类。 这种方式下,并不适用于中文文本的分类,分类效果不佳。
技术实现要素:
本发明旨在至少在一定程度上解决相关技术中的技术问题之一。 为此,本发明的目的在于提出一种文本分类方法、装置、存储介质及计算机设备, 由于在分类的过程中采用五笔字形编码描述中文文本的五笔字根之间的特征,由此能够在 对中文文本进行分类时获得较好的适用性以及中文文本分类效果。 本发明第一方面实施例提出的文本分类方法,所述文本为中文文本,包括:获得文 本;对所述文本进行编码得到五笔字形编码;根据所述五笔字形编码,结合所述XLNet模型 确定所述文本中各子文本之间的特征信息,所述特征信息用于描述各子文本之间的上下文 信息,所述XLNet模型已学习得到多个样本子文本的样本字形编码,以及所述多个样本子文 本之间的特征信息的对应关系;根据所述各子文本之间的特征信息,结合第一神经网络模 型对所述文本进行分类。 本发明第一方面实施例提出的文本分类方法,通过获得文本,对文本进行编码得 到五笔字形编码,并根据五笔字形编码,结合XLNet模型确定文本中各子文本之间的特征信 息,特征信息用于描述各子文本之间的上下文信息,XLNet模型已学习得到多个样本子文本 的样本字形编码,以及多个样本子文本之间的特征信息的对应关系,以及根据各子文本之 间的特征信息,结合第一神经网络模型对文本进行分类,由于在分类的过程中采用五笔字 形编码描述中文文本的五笔字根之间的特征,由此能够在对中文文本进行分类时获得较好 的适用性以及中文文本分类效果。 本发明第二方面实施例提出的文本分类装置,所述文本为中文文本,包括:获取模 块,用于获得文本;编码模块,用于对所述文本进行编码得到五笔字形编码;识别模块,用于 根据所述五笔字形编码,结合所述XLNet模型确定所述文本中各子文本之间的特征信息,所 述特征信息用于描述各子文本之间的上下文信息,所述XLNet模型已学习得到多个样本子 4 CN 111581377 A 说 明 书 2/10 页 文本的样本字形编码,以及所述多个样本子文本之间的特征信息的对应关系;分类模块,用 于根据所述各子文本之间的特征信息,结合第一神经网络模型对所述文本进行分类。 本发明第二方面实施例提出的文本分类装置,通过获得文本,对文本进行编码得 到五笔字形编码,并根据五笔字形编码,结合XLNet模型确定文本中各子文本之间的特征信 息,特征信息用于描述各子文本之间的上下文信息,XLNet模型已学习得到多个样本子文本 的样本字形编码,以及多个样本子文本之间的特征信息的对应关系,以及根据各子文本之 间的特征信息,结合第一神经网络模型对文本进行分类,由于在分类的过程中采用五笔字 形编码描述中文文本的五笔字根之间的特征,由此能够在对中文文本进行分类时获得较好 的适用性以及中文文本分类效果。 本发明第三方面实施例提出的计算机可读存储介质,其上存储有计算机程序,该 程序被处理器执行时实现本发明第一方面实施例提出的文本分类方法。 本发明第三方面实施例提出的计算机可读存储介质,通过获得文本,对文本进行 编码得到五笔字形编码,并根据五笔字形编码,结合XLNet模型确定文本中各子文本之间的 特征信息,特征信息用于描述各子文本之间的上下文信息,XLNet模型已学习得到多个样本 子文本的样本字形编码,以及多个样本子文本之间的特征信息的对应关系,以及根据各子 文本之间的特征信息,结合第一神经网络模型对文本进行分类,由于在分类的过程中采用 五笔字形编码描述中文文本的五笔字根之间的特征,由此能够在对中文文本进行分类时获 得较好的适用性以及中文文本分类效果。 本发明第四方面实施例提出的计算机设备,包括壳体、处理器、存储器、电路板和 电源电路,其中,所述电路板安置在所述壳体围成的空间内部,所述处理器和所述存储器设 置在所述电路板上;所述电源电路,用于为所述计算机设备的各个电路或器件供电;所述存 储器用于存储可执行程序代码;所述处理器通过读取所述存储器中存储的可执行程序代码 来运行与所述可执行程序代码对应的程序,以用于执行:获得文本;对所述文本进行编码得 到五笔字形编码;根据所述五笔字形编码,结合所述XLNet模型确定所述文本中各子文本之 间的特征信息,所述特征信息用于描述各子文本之间的上下文信息,所述XLNet模型已学习 得到多个样本子文本的样本字形编码,以及所述多个样本子文本之间的特征信息的对应关 系;根据所述各子文本之间的特征信息,结合第一神经网络模型对所述文本进行分类。 本发明第四方面实施例提出的计算机设备,通过获得文本,对文本进行编码得到 五笔字形编码,并根据五笔字形编码,结合XLNet模型确定文本中各子文本之间的特征信 息,特征信息用于描述各子文本之间的上下文信息,XLNet模型已学习得到多个样本子文本 的样本字形编码,以及多个样本子文本之间的特征信息的对应关系,以及根据各子文本之 间的特征信息,结合第一神经网络模型对文本进行分类,由于在分类的过程中采用五笔字 形编码描述中文文本的五笔字根之间的特征,由此能够在对中文文本进行分类时获得较好 的适用性以及中文文本分类效果。 本发明附加的方面和优点将在下面的描述中部分给出,部分将从下面的描述中变 得明显,或通过本发明的实践了解到。 附图说明 本发明上述的和/或附加的方面和优点从下面结合附图对实施例的描述中将变得 5 CN 111581377 A 说 明 书 3/10 页 明显和容易理解,其中: 图1是本发明一实施例提出的文本分类方法的流程示意图; 图2为本发明实施例中的基于双流自注意力机制的排序XLNet模型的示意图; 图3是本发明另一实施例提出的文本分类方法的流程示意图; 图4为本发明实施例中五笔字根表的示意图; 图5是本发明实施例中确定五笔字形编码的流程示意图; 图6为本发明实施例中文本分类流程示意图; 图7是本发明一实施例提出的文本分类装置的结构示意图; 图8是本发明一实施例提出的计算机设备的结构示意图。











