
技术摘要:
本文所呈现的是用于训练听力假体以将接收到的声音信号分类/归类为包括接受者的自身语音(即,听力假体的接受者的语音或话音)或外部语音(即,接受者以外的一个或多个人的语音或话音)的技术。本文所呈现的技术使用接受者捕获的语音(话音)来训练听力假体,以执行将声音信号 全部
背景技术:
可能由于多种不同原因引起的听力损失通常为传导性和/或感觉神经性两种类 型。当外耳和/或中耳的正常机械通路受到阻碍(例如,对听小骨链或耳道的损坏)时,发生 传导性听力损失。当内耳或从内耳到大脑的神经通路受损时,发生感觉神经性听力损失。 患有传导性听力损失的个体通常会有某种形式的残余听力,因为耳蜗中的毛细胞 未受损。这样,患有传导性听力损失的个体通常接纳生成耳蜗液的运动的听觉假体。这样的 听觉假体包括例如声学助听器、骨传导设备和直接声学刺激器。 然而,在许多严重耳聋的人员中,他们耳聋的原因是感觉神经性听力损失。那些患 有某种形式的感觉神经性听力损失的人员不能从生成耳蜗液的机械运动的听觉假体中获 得适当的益处。这样的个体可以从植入性听觉假体中受益,植入性听力假体以其他方式(例 如,电学、光学等)刺激接受者的听觉系统的神经细胞。当感觉神经性听力损失是由于耳蜗 毛细胞的缺失或破坏而引起的,通常会建议耳蜗植入体,其将声音信号转化为神经冲动。听 觉脑干刺激器是另一类型的刺激听觉假体,当接受者由于听觉神经受损而遭受感觉神经性 听力损失时也可能建议听觉脑干刺激器。 某些个体仅患有部分感觉神经性听力损失,并且因此至少保留了一些残余听力。 这些个体可能是针对电声听力假体的候选人。
技术实现要素:
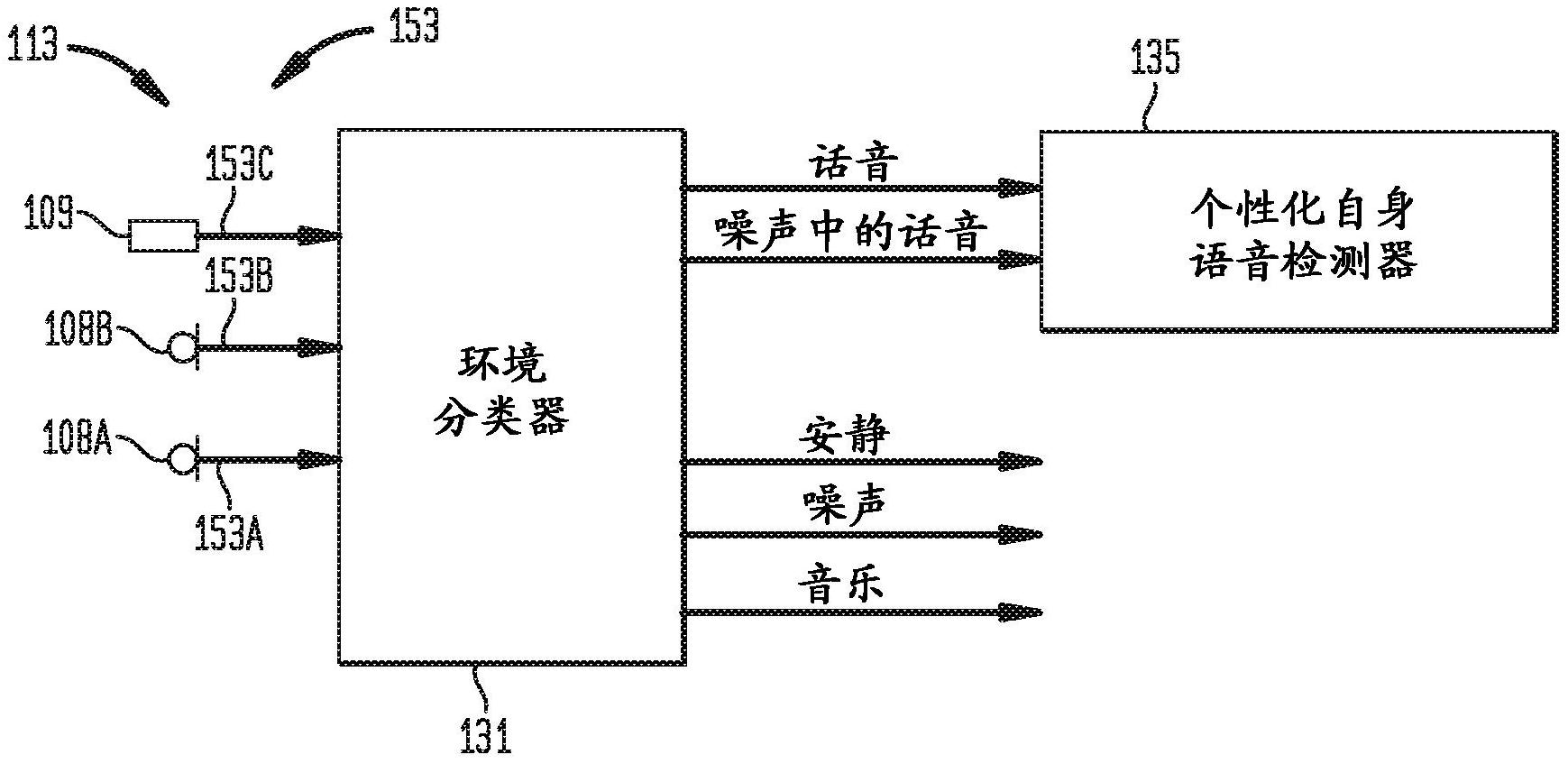
在一方面,提供了一种方法。该方法包括:在听力假体的一个或多个麦克风处,捕 获包括听力假体的接受者的语音的输入音频信号;在听力假体上从输入音频信号计算时变 特征;并且基于对多个时变特征的分析,更新听力假体的自身语音检测决策树的操作。 在另一方面,提供了一种方法。该方法包括:在听力假体处接收输入音频信号,其 中输入音频信号包括听力假体的接受者的话音;在听力假体上从输入音频信号计算时变特 征;在听力假体上利用自身语音检测决策树分析多个时变特征;接收与输入音频信号相关 联的标签数据,其中标签数据指示输入音频信号的哪些时间分段包括接受者的语音;分析 多个时变特征和标签数据,以针对自身语音检测决策树生成更新后的权重;并且利用更新 后的权重来更新自身语音检测决策树。 在另一方面,提供了一种方法。该方法包括:接收输入音频信号生成的时变特征, 该输入音频信号从在听力假体的一个或多个麦克风处被捕获,其中输入音频信号包括听力 假体的接受者的语音;接收与输入音频信号相关联的标签数据,其中标签数据指示输入音 频信号的多个时间分段中的哪些时间分段包括接受者的语音;分析多个时变特征和标签数 据,以针对听力假体上的自身语音检测决策树生成更新后的权重;利用更新后的权重来更 新自身语音检测决策树,以生成更新后的自身语音检测决策树。 6 CN 111615833 A 说 明 书 2/13 页 附图说明 在本文中结合附图描述本发明的实施例,其中: 图1A是图示了根据本文所呈现的某些实施例的耳蜗植入体的示意图; 图1B是图1A的耳蜗植入体的框图; 图2是根据本文所呈现的某些实施例的完全可植入的耳蜗植入体的框图; 图3是图示了根据本文所呈现的某些实施例的环境分类器和个性化自身语音检测 器的操作的示意框图; 图4A是图示了根据本文所呈现的某些实施例的更新个性化自身语音检测决策树 的示意框图。 图4B是图示了图4A的布置的一种实现的进一步细节的示意框图; 图5是图示了根据本文所呈现的某些实施例的用于动态更新听力假体上的环境分 类决策树的技术的示意框图; 图6是图示了根据本文所呈现的某些实施例的用于动态更新听力假体上的环境分 类决策树和自身语音检测树的技术的示意框图; 图7是图示了根据本文所呈现的某些实施例的在环境分类中的补充信号特征的使 用的示意框图; 图8是图示了根据本文所呈现的某些实施例的用于动态更新自身语音检测树的基 于云的布置的框图; 图9是用于实现本文所呈现的某些技术的适配系统的框图; 图10是根据本文所呈现的实施例的方法的流程图; 图11是根据本文所呈现的实施例的另一方法的流程图;并且 图12是根据本文所呈现的实施例的另一方法的流程图。











