
技术摘要:
本发明提供了一种信息处理方法,包括:获取与名称预测模型的使用环境相匹配的第一训练样本,确定名称预测模型中的第一神经网络的初始参数和第二神经网络的初始参数;通过名称预测模型对特征集合进行处理,确定名称预测模型的不同神经网络对应的更新参数;根据名称预测 全部
背景技术:
传统技术中,在通过社交软件产品对联系人进行备注的时候,仅能够由用户手动 输入备注名称,或者通过群昵称(群名片)推荐备注名称的方式完成备注,不但不利于用户 对数量较多的联系人同时进行名称备注,同时手工进行名称备注的速率与准确度都影响了 用户的使用体验,为此,人工智能技术(AI,Artificial Intelligence)提供了适当的文本 处理进程的运行机制来支持上述应用的方案。其中,人工智能是利用数字计算机或者数字 计算机控制的机器模拟、延伸和扩展人的智能,感知环境、获取知识并使用知识获得最佳结 果的理论、方法和技术及应用系统人工智能也就是研究各种智能机器的设计原理与实现方 法,使机器具有感知、推理与决策的功能,在语音处理领域中,也就是通过利用数字计算机 或者数字计算机控制的机器实现对自动化的对备注对象进行名称备注。
技术实现要素:
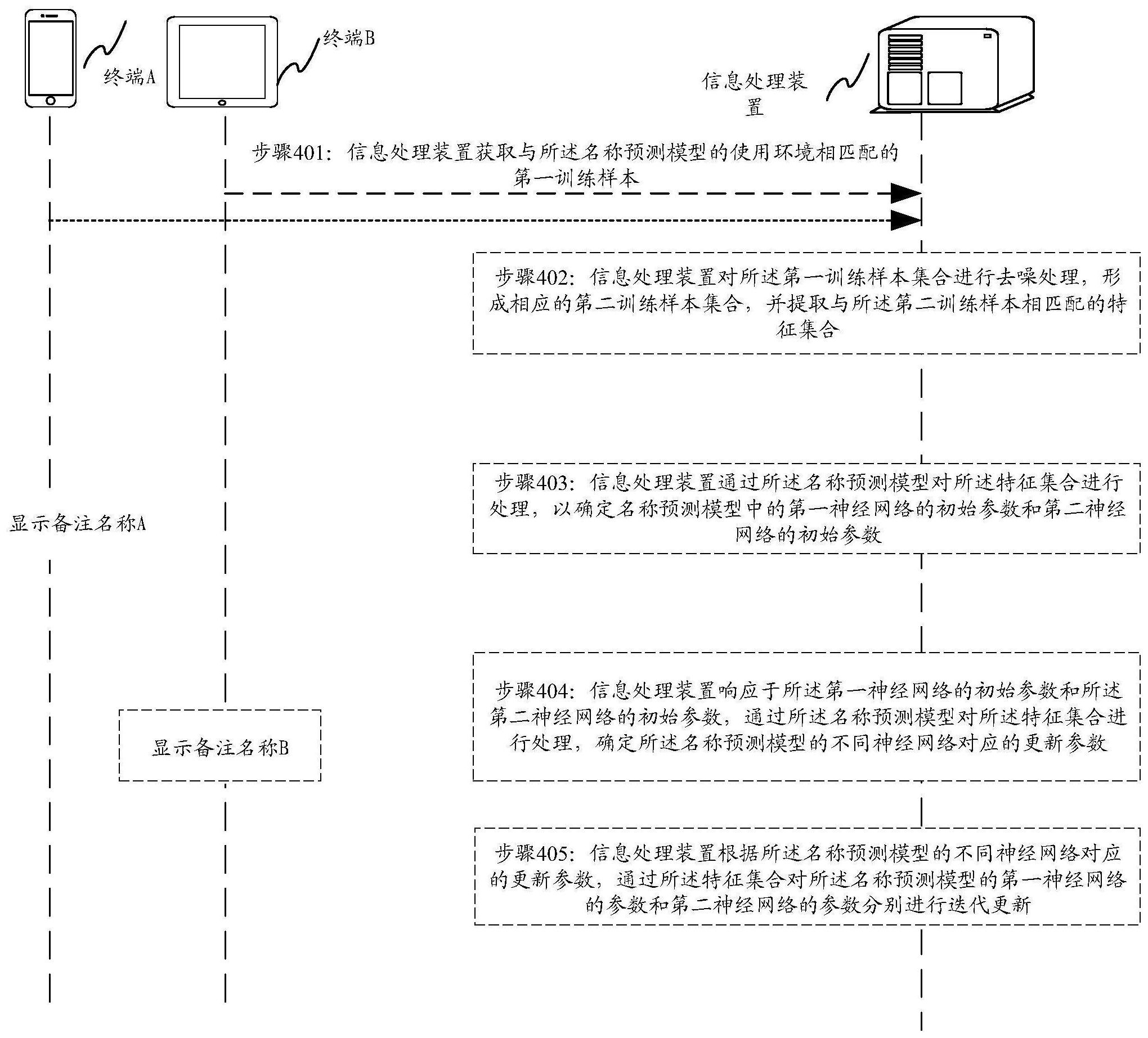
有鉴于此,本发明实施例提供一种信息处理方法、装置、电子设备及存储介质,本 发明实施例的技术方案是这样实现的: 本发明实施例提供了一种信息处理方法,包括: 获取与所述名称预测模型的使用环境相匹配的第一训练样本,其中,所述训练样 本中包括相应目标用户的历史行为信息; 对所述第一训练样本集合进行去噪处理,形成相应的第二训练样本集合,并提取 与所述第二训练样本相匹配的特征集合; 通过所述名称预测模型对所述特征集合进行处理,以确定名称预测模型中的第一 神经网络的初始参数和第二神经网络的初始参数; 响应于所述第一神经网络的初始参数和所述第二神经网络的初始参数,通过所述 名称预测模型对所述特征集合进行处理,确定所述名称预测模型的不同神经网络对应的更 新参数; 根据所述名称预测模型的不同神经网络对应的更新参数,通过所述特征集合对所 述名称预测模型的第一神经网络的参数和第二神经网络的参数分别进行迭代更新,以实现 通过所述名称预测模型确定与备注对象相匹配的备注名称。 上述方案中,所述基于所述备注对象的重合度,对所述不同社交网络中的备注对 象的待备注名称进行过滤处理,包括: 确定所述备注对象的文本信息中的昵称信息、职位信息和姓名信息,并对所述昵 称信息和所述职位信息进行过滤; 基于所述备注对象的重合度,确定与所述备注对象相对应的第一权重参数和第二 权重参数; 6 CN 111552799 A 说 明 书 2/23 页 基于所述备注对象相对应的第一权重参数和第二权重参数,对所述备注对象的文 本信息中的姓名信息进行过滤与合并,以形成不同的待备注名称。 上述方案中,所述方法还包括: 将所述备注对象的标识信息及对应的备注名称发送至区块链网络,以使 所述区块链网络的节点将所述备注对象的标识信息及对应的备注名称填充至新 区块,且当对所述新区块共识一致时,将所述新区块追加至区块链的尾部。 本发明实施例还提供了一种信息处理装置,所述装置包括: 信息传输模块,用于获取与所述名称预测模型的使用环境相匹配的第一训练样 本,其中,所述训练样本中包括相应目标用户的历史行为信息; 训练模块,用于对所述第一训练样本集合进行去噪处理,形成相应的第二训练样 本集合,并提取与所述第二训练样本相匹配的特征集合; 所述训练模块,用于通过所述名称预测模型对所述特征集合进行处理,以确定名 称预测模型中的第一神经网络的初始参数和第二神经网络的初始参数; 所述训练模块,用于响应于所述第一神经网络的初始参数和所述第二神经网络的 初始参数,通过所述名称预测模型对所述特征集合进行处理,确定所述名称预测模型的不 同神经网络对应的更新参数; 所述训练模块,用于根据所述名称预测模型的不同神经网络对应的更新参数,通 过所述特征集合对所述名称预测模型的第一神经网络的参数和第二神经网络的参数分别 进行迭代更新,以实现通过所述名称预测模型确定与备注对象相匹配的备注名称。 上述方案中, 所述传输模块,用于获取所述目标用户的日志信息; 所述传输模块,用于基于所述目标用户的日志信息,确定所述目标用户使用所述 名称预测模型所推荐的备注名称作为正例样本; 所述传输模块,用于基于所述目标用户的日志信息,确定所述目标用户未使用所 述名称预测模型所推荐的备注名称作为负例样本; 所述传输模块,用于基于所述正例样本和所述负例样本,确定与所述名称预测模 型的使用环境相匹配的第一训练样本。 上述方案中, 所述训练模块,用于确定与所述名称预测模型的使用环境相匹配的动态噪声阈 值; 所述训练模块,用于根据所述动态噪声阈值对所述第一训练样本集合进行去噪处 理,以形成与所述动态噪声阈值相匹配的第二训练样本集合; 所述训练模块,用于提取与所述第二训练样本相匹配的词语级特征向量,并对所 述不同的词语级特征向量进行除噪处理,形成与所待备注名称文本内容相对应的词语级特 征向量集合,其中,所述与所待备注名称文本内容相对应的词语级特征向量集合包括所述 待备注名称文本内容的数据来源。 上述方案中, 所述训练模块,用于确定与所述名称预测模型的使用环境相匹配的固定噪声阈 值; 7 CN 111552799 A 说 明 书 3/23 页 所述训练模块,用于根据所述固定噪声阈值对所述第一训练样本集合进行去噪处 理,以形成与所述固定噪声阈值相匹配的第二训练样本集合; 所述训练模块,用于提取与所述第二训练样本相匹配的词语级特征向量,并对所 述不同的词语级特征向量进行除噪处理,形成与所待备注名称文本内容相对应的词语级特 征向量集合,其中,所述与所待备注名称文本内容相对应的词语级特征向量集合包括所述 待备注名称文本内容的数据来源。 上述方案中, 所述训练模块,用于将所述特征集合中不同备注名称向量,代入由所述名称预测 模型的第一神经网络的编码器和解码器构成的自编码网络对应的损失函数; 所述训练模块,用于确定所述损失函数满足第一收敛条件时对应所述第一神经网 络的编码器的参数和相应的解码器参数作为所述第一神经网络的更新参数; 所述训练模块,用于将所述特征集合中不同语句样本,代入由所述名称预测模型 的第二神经网络的编码器和解码器构成的自编码网络对应的损失函数; 所述训练模块,用于确定所述损失函数满足第二收敛条件时对应所述第二神经网 络的编码器的参数和相应的解码器参数作为所述第二神经网络的更新参数。 上述方案中, 所述训练模块,用于确定与所述名称预测模型中不同神经网络相匹配的收敛条 件; 所述训练模块,用于对所述第一神经网络的编码器参数和解码器参数进行迭代更 新,直至所述第一神经网络的编码器和解码器构成的自编码网络对应的损失函数满足对应 的收敛条件; 所述训练模块,用于对所述第二神经网络的编码器参数和解码器参数进行迭代更 新,直至所述第二神经网络的编码器和解码器构成的自编码网络对应的损失函数满足对应 的收敛条件。 上述方案中,所述装置还包括: 信息处理模块,用于确定与名称预测模型的使用环境相对应的不同社交网络中的 备注对象的重合度; 所述信息处理模块,用于基于所述备注对象的重合度,对所述不同社交网络中的 备注对象的待备注名称进行过滤处理; 所述信息处理模块,用于响应于所述待备注名称的过滤处理结果,通过所述名称 预测模型获取不同维度中的待备注名称,并将所述待备注名称转换为相应的文本特征向 量; 所述信息处理模块,用于根据所述文本特征向量确定与所述文本内容所对应的至 少一个词语级的隐变量; 所述信息处理模块,用于根据所述至少一个词语级的隐变量,生成与所述词语级 的隐变量相对应的候选词语以及所述候选词语的被选取概率; 所述信息处理模块,用于根据所述候选词语的被选取概率,选取至少一个候选词 语组成与当前社交网络中的备注对象相匹配的备注名称。 上述方案中, 8 CN 111552799 A 说 明 书 4/23 页 所述信息处理模块,用于确定所述备注对象所对应的目标用户所对应的不同社交 网络; 所述信息处理模块,用于对所述目标用户所对应的不同社交网络中的信息进行融 合; 所述信息处理模块,用于基于经过融合的所述目标用户所对应的不同社交网络中 的信息,确定所述备注对象在不同社交网络中的社交拓扑关系; 所述信息处理模块,用于确定所述备注对象所对应的目标用户的社交拓扑关系; 所述信息处理模块,用于基于所述备注对象在不同社交软件中的社交拓扑关系和 所述目标用户的社交拓扑关系的重合比例,确定与名称预测模型的使用环境相对应的不同 社交网络中的备注对象的重合度。 上述方案中, 所述处理模块,用于基于所述目标用户在不同社交网络中的登录信息、注册信息、 设备信息以及关系人网络相似度信息,确定所述不同社交网络所归属的用户; 所述处理模块,用于当确定所述不同社交网络所归属于同一目标用户时,对所述 目标用户所对应的不同社交网络中的信息进行融合。 上述方案中, 所述处理模块,用于确定所述备注对象的文本信息中的昵称信息、职位信息和姓 名信息,并对所述昵称信息和所述职位信息进行过滤; 所述处理模块,用于基于所述备注对象的重合度,确定与所述备注对象相对应的 第一权重参数和第二权重参数; 所述处理模块,用于基于所述备注对象相对应的第一权重参数和第二权重参数, 对所述备注对象的文本信息中的姓名信息进行过滤与合并,以形成不同的待备注名称。 上述方案中, 所述处理模块,用于根据所述名称预测模型所获取的不同维度中的待备注名称, 对所述候选词语的被选取概率进行融合处理; 所述处理模块,用于根据所述候选词语的被选取概率的融合处理结果,选取至少 一个候选词语组成所述备注对象相匹配的备注名称。 上述方案中,所述装置还包括: 显示模块,用于显示用户界面,所述用户界面中包括以第一人称视角对相应软件 进程中的备注对象进行名称备注的视角画面,所述用户界面中还包括辅助信息控制组件; 所述显示模块,用于通过所述辅助信息控制组件,控制展示与所述备注对象相匹 配的备注名称,以实现通过所述显示用户界面中选择与所述备注对象相匹配的备注名称。 上述方案中, 所述显示模块,用于当通过所述显示用户界面中选择与所述备注对象相匹配的备 注名称完成时,触发所述辅助信息控制组件,以实现通过所述辅助信息控制组件对相应软 件进程中的备注对象添加电子名片或图片。 上述方案中, 所述处理模块,用于将所述备注对象的标识信息及对应的备注名称发送至区块链 网络,以使 9 CN 111552799 A 说 明 书 5/23 页 所述区块链网络的节点将所述备注对象的标识信息及对应的备注名称填充至新 区块,且当对所述新区块共识一致时,将所述新区块追加至区块链的尾部。 本发明实施例还提供了一种电子设备,所述电子设备包括: 存储器,用于存储可执行指令; 处理器,用于运行所述存储器存储的可执行指令时,实现前序的信息处理方法。 本发明实施例还提供了一种计算机可读存储介质,存储有可执行指令,其特征在 于,所述可执行指令被处理器执行时实现前序的信息处理方法。 本发明实施例具有以下有益效果: 本发明实施例通过获取与所述名称预测模型的使用环境相匹配的第一训练样本, 其中,所述训练样本中包括相应目标用户的历史行为信息;对所述第一训练样本集合进行 去噪处理,形成相应的第二训练样本集合,并提取与所述第二训练样本相匹配的特征集合; 通过所述名称预测模型对所述特征集合进行处理,以确定名称预测模型中的第一神经网络 的初始参数和第二神经网络的初始参数;响应于所述第一神经网络的初始参数和所述第二 神经网络的初始参数,通过所述名称预测模型对所述特征集合进行处理,确定所述名称预 测模型的不同神经网络对应的更新参数;根据所述名称预测模型的不同神经网络对应的更 新参数,通过所述特征集合对所述名称预测模型的第一神经网络的参数和第二神经网络的 参数分别进行迭代更新,以实现通过所述名称预测模型确定与备注对象相匹配的备注名 称,由此,由此,使得名称预测模型的泛化能力更强,提升名称预测模型的训练精度与训练 速度,同时使得名称预测模型能够适应不同的使用场景,避免环境噪声对名称预测模型的 影响,使得名称预测模型能够产生高质量的备注名称,进而实现通过名称预测模型利用不 同社交网络的信息融合产生并向用户推荐高质量的备注名称,用户可以直接使用所推荐的 备注名称,减少了用户手工进行名称备注的繁琐过程,提升了名称备注的处理效率,也提升 了名称备注的准确率。 附图说明 图1为本发明实施例提供的信息处理方法的使用场景示意图; 图2为本发明实施例提供的电子设备的组成结构示意图;、 图3为传统方案中生成用户备注名称的示意图; 图4为本发明实施例提供的信息处理方法一个可选的流程示意图; 图5为本发明实施例中第二神经网络一个可选的结构示意图; 图6为本发明实施例中第二神经网络一个可选的词语级机器阅读示意图; 图7为本发明实施例中第二神经网络中编码器一个可选的结构示意图; 图8为本发明实施例中第二神经网络中编码器的向量拼接示意图; 图9为本发明实施例中第二神经网络中编码器的编码过程示意图; 图10为本发明实施例中第二神经网络中解码器的解码过程示意图; 图11为本发明实施例中第二神经网络中解码器的解码过程示意图; 图12为本发明实施例中第二神经网络中解码器的解码过程示意图; 图13为本发明实施例中第二神经网络一个可选的备注名称机器阅读示意图; 图14为本发明实施例提供的信息处理方法一个可选的流程示意图; 10 CN 111552799 A 说 明 书 6/23 页 图15是本发明实施例提供的信息处理装置100的架构示意图; 图16是本发明实施例提供的区块链网络200中区块链的结构示意图; 图17是本发明实施例提供的区块链网络200的功能架构示意图; 图18为本发明实施例中对不同社交网络中的不同联系人进行名称备注的应用环 境示意图; 图19为本发明实施例中通过微信应用程序中显示备注名称的示意图; 图20为本发明实施例中通过企业微信微信应用程序中显示备注名称的示意图; 图21为本发明实施例中通过购物应用程序中显示备注名称的示意图; 图22为本发明实施例中通过即时通讯客户端的应用程序中显示备注名称的示意 图; 图23为本发明实施例所提供的名称预测模型的工作过程示意图; 图24为本发明实施例中微信进程中目标用户的社交网络拓扑关系示意图; 图25为本发明实施例中名称预测模型一个可选的结构示意图; 图26为本发明实施例中名称预测模型中第二神经网络的结构示意图。











