
技术摘要:
本发明公开了一种基于图卷积神经网络的弱监督目标检测方法。本发明通过引入只检测到物体一部分的伪标注框作为弱监督目标检测网络的监督条件,通过多实例网络只检测到物体的一部分而不是覆盖全部物体;利用图卷积神经网络把检测为物体框的邻近且相交的候选框学习物体框 全部
背景技术:
目标检测是基于计算机视觉的基本问题,在医疗诊断和自动驾驶领域有着长足的 发展。同时随着机器学习的飞速发展,计算资源有了长足的进步,几年来目标检测模型性能 得到了巨大的提升。但是目前的目标检测模型基本上都是采用有标注框的训练数据作为标 注数据训练目标检测模型。这需要大量时间和物力对图片进行标注。全监督目标检测网络 模型精度有很大的提升。但是边框的标注信息也有许多缺点。第一:大量的边框标注信息提 高了目标检测的金钱成本,第二:人为标注的边框信息存在误差和错误,误差和错误会使模 型偏离预训练的精度,使得精度变低。 由于全监督目标检测需要花费大量的成本,以及会产生不必要的错误和误差,弱 监督模型就被推广出来,弱监督模型的训练标签只有物体的类别信息,而没有物体的位置 信息,所以在进行目标检测时,只能用类别信息作为监督条件,因此,弱监督目标检测比全 监督目标检测的精度要低很多。 目前的弱监督目标监测模型都是利用多示例学习,利用类别标签作为监督条件训 练一个弱监督目标检测模型,然后通过弱监督目标检测模型产生新的伪标注框作为训练条 件,来训练一个全监督目标检测模型,这样就有了位置的标注信息。提高模型的检测效率。 然而通过多示例学习之后的分类网络往往准确率很低,检测到的物体框只覆盖物 体的一部分,没有完全覆盖物体的全部,导致检测精度降低。并且传统的弱监督目标检测网 络中,实例分类器提炼网络模型是三层的迭代训练模型,检测模型结构冗余,降低了检测的 效率。
技术实现要素:
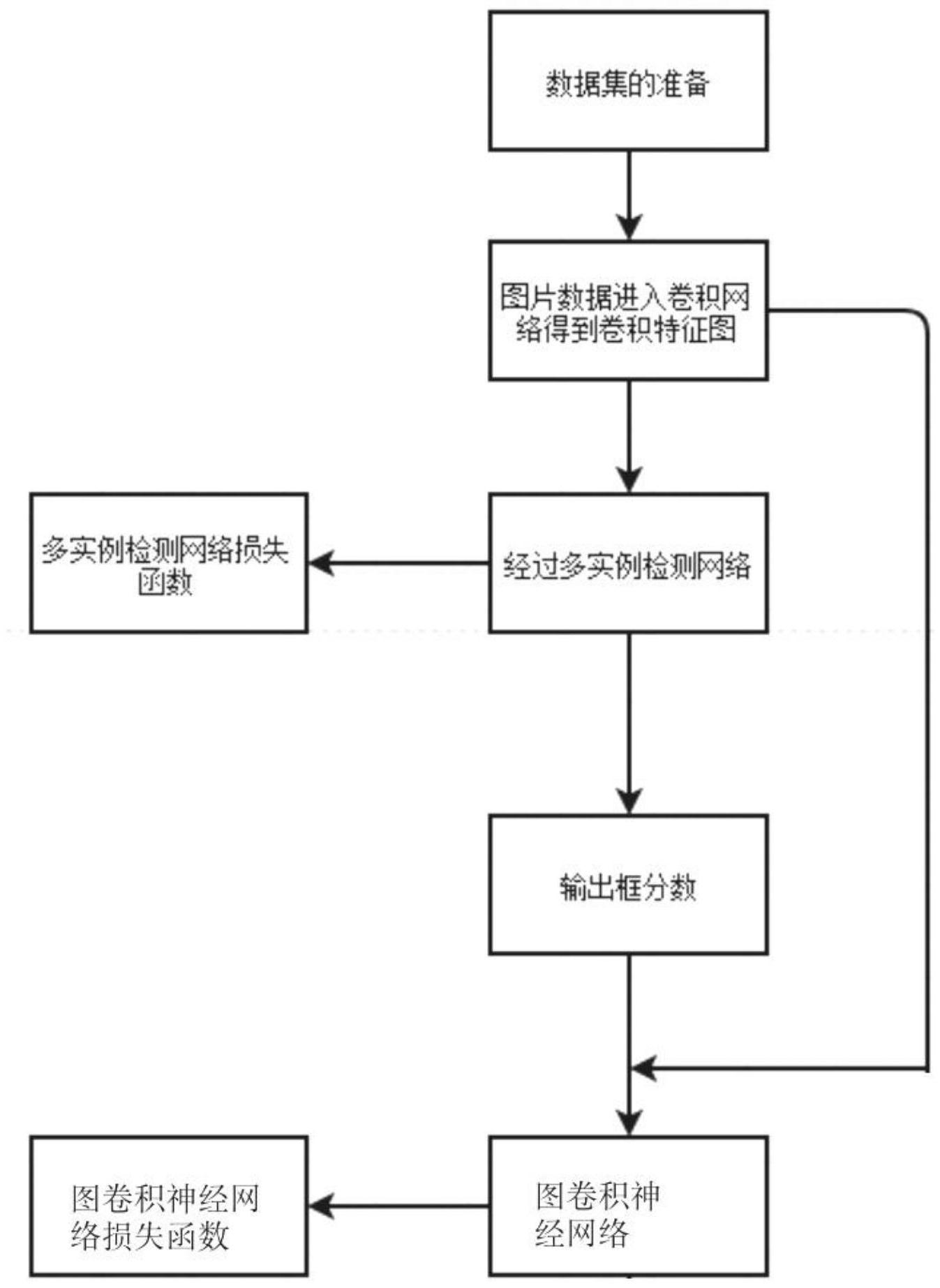
本发明所要解决的技术问题是:提出一种基于图卷积神经网络的弱监督目标检测 方法,解决传统的弱监督目标检测网络只检测到物体的一部分而不是整个物体这一问题。 本发明通过图卷积神经网络降低弱监督目标检测模型的冗余性,从而提高弱监督目标检测 的精度,以及降低弱监督目标检测的时间,提升目标检测的效率。 针对上述实际情况,提出一种基于图卷积神经网络的弱监督目标检测方法,通过 引入只检测到物体一部分的伪标注框作为弱监督目标检测网络的监督条件,通过多实例网 络只检测到物体的一部分而不是覆盖全部物体。利用图卷积神经网络把检测为物体框的邻 近且相交的候选框学习物体框的特征表示。因为和物体框相交的候选框也是物体的一部 分,通过学习检测为物体的框的特征表示来改变候选框的特征表示,邻近的框学习检测为 物体的框的特征。候选框和检测为物体框的特征表示就会相似,弱监督网络测试的时候会 把与检测为物体框的邻近候选框也分类为目标物体。从而检测出的目标框覆盖更大的面积 4 CN 111612051 A 说 明 书 2/6 页 和更全的物体,提高弱监督目标检测的精度。 本发明将两个步骤的弱监督检测模型简化为一个端到端的网络模型结构,不仅简 化了网络模型。减少了弱监督目标检测的时间,图卷积网络损失函数和弱监督模型的分类 损失函数共同组成新的损失函数训练弱监督检测模型。提高弱监督检测模型的精度,减少 了弱监督检测的时间。 本发明解决其技术问题所采用的技术方案具体包括以下步骤: 步骤(1)训练数据集的准备阶段: 在目标检测中用PASCAL VOC 2007以及PASCAL VOC 2012数据集作为训练数据集, 训练数据集中包括20种物体类别,PASCAL VOC2007一共有9963张图片,其中有训练数据集 5011张图片,测试数据集有4952张图片。PASCAL VOC 2012数据集一共有22531张图片,其中 训练数据集11540张图片,测试数据集有10991张图片。其中除了图片信息外还有每张图片 含有的物体类别信息。 步骤(2)获取图片的特征图以及多实例检测网络模型: 首先,图片经过卷积层得到卷积特征图Ⅰ; 其次,选择性搜索边框图片经过金字塔池化层得到每个选择性搜索边框图片的卷 积特征图Ⅱ,将卷积特征图Ⅱ连续经过两层全连接层得到选择性搜索边框图片的特征向量 Ⅰ,特征向量Ⅰ分别经过全连接层Ⅰ和全连接层Ⅱ,全连接层Ⅰ与物体类别方向的softmax层Ⅰ 连接,全连接层Ⅱ与选择性搜索边框图片方向的softmax层Ⅱ连接;将softmax层Ⅰ和 softmax层Ⅱ输出的两个特征向量进行数量积相乘得到特征向量Ⅱ,根据特征向量Ⅱ得到 每个选择性搜索边框图片在每个类别上的得分。 所述的图片包含多个选择性搜索边框图片; 步骤(3)图卷积神经网络,为了提高弱监督网络模型的检测精度,将步骤(2)获取 的选择性搜索边框图片的特征向量Ⅱ输入图卷积神经网络,图卷积神经网络(GCN network)包括第一个隐藏层、第一个ReLU激活函数层、第二个隐藏层、第二个ReLU激活函数 层。 将特征向量Ⅰ作为第一个隐藏层的输入,所述的特征向量Ⅰ是2000*4096大小的的 特征矩阵;将第一个隐藏层输出设置为256维,因此第一个隐藏层将4096维转为256维,输出 特征向量Ⅲ,降低了网络参数的个数,减少训练复杂度。然后输出的特征向量Ⅲ点乘邻接矩 阵A,再然后连接第一个ReLU激活函数层;第一个ReLU激活函数层的输出作为第二个隐藏层 的输入,第二个隐藏层的输出网络参数为21维,因此第二个隐藏层将256维转为21维,第二 个隐藏层输出21维的特征向量Ⅳ,第二个隐藏层输出的特征向量Ⅳ再次点乘邻接矩阵A,然 后再连接第二个ReLU激活函数层,得到特征向量Ⅴ;特征向量Ⅴ是2000*21大小的的特征矩 阵; 图卷积神经网络的输出层连接一个softmax层,softmax层输出特征向量Ⅵ,即每 个选择性搜索边框图片获得特征向量Ⅵ中,属于21个类别中每个类别的概率;最后连接损 失函数。 所述的邻接矩阵A的获取如下: 计算n行和m列的选择性搜索边框图片之间的IOU,当IOU大于0.1时邻接矩阵A的n 行m列的值为1,当IOU小于0.1时,邻接矩阵A的n行m列的值为0,具体步骤如图所示。 5 CN 111612051 A 说 明 书 3/6 页 本发明用图卷积神经网络的一个分支网络替代了三个实例分类器优化网络,利用 图卷积算法降低了模型的冗余性,只需连接一个图卷积神经网络,提高了模型的检测效率。 步骤(4)设置弱监督目标检测模型的损失函数,多实例检测网络模型的损失函数 为分类损失函数,具体的为交叉熵损失函数,如公式(1)所示。 其中,φc是多实例网络模型输出的所有选择性搜索框图片的一个类别c上的权重 之和。yc表示图片存在或者不存在物体类别c,当存在时等于1,不存在时等于0。C表示物体 种类的总数量,PASCALVOC有20类;加上背景这一类,C的取值为21,c表示物体的种类。 所述的权重之和是指在一个类别c上的所有选择性搜索框图片的概率之和,且该 权重之和的数值在(0,1)之间。 图片中,当c种类存在时,yc等于1;那么式(1)的加号右侧为0,所以此时φc越大损 失函数越小,则存在的分类的置信分数就会越大。 图片中,当c种类不存在时,yc等于0,那么式(1)的加号左侧为0,所以此时φc越小 损失函数越小,则不存在的类别的置信分数就会越小。 图卷积神经网络分支结构的损失函数是一个分类损失函数,首先每个选择性搜索 框图片的输出特征向量Ⅵ再经过softmax层,分类出每个选择性搜索框图片的类别概率的 置信分数 分类损失函数如下所示: 其中, 表示第r个选择性搜索框图片属于c类别的置信分数,属于(0,1)之间。yc 表示图像存在或者不存在类别c,当存在时yc等于1,不存在时yc等于0。C表示物体种类数目, PASCAL VOC中有20个类。对图片中所有的选择性搜索框图片对应的类进行聚类,经过聚类 分为N束,sn表示第n个聚类束的置信分数,Mn表示第n个聚类束的物体框的个数。 步骤(5)用步骤(1)中训练数据集中的训练接迭代训练弱监督目标检测模型,得到 模型结果。由上述步骤可以得到弱监督目标检测模型的训练结果,通过迭代训练,训练20个 epoch,每个epoch迭代一万张图片,每个epoch存储一个训练的模型. 步骤(6)测试弱监督目标检测模型结果,通过两个重要的指标判断目标定位精度: 平均正确率mAP和定位正确率CorLoc;其中平均正确率mAP是对于测试集的目标检测精度, 定位正确率CorLoc是对于训练集的目标定位精度。 通过本方法获取的平均正确率mAP和定位正确率CorLoc比现有PCL弱监督算法精 确度提高5%mAP。 实验结果表面,在弱监督目标检测模型上达到了端到端的平均正确率mAP最好的 性能和定位准确率CorLoc最好的性能。 本发明的有益效果: 本发明所述的方法是一个基于图卷积神经网络的弱监督目标检测方法,本方法是 一个端到端的弱监督目标检测模型,而不是两个步骤的弱监督加全监督网络模型。 6 CN 111612051 A 说 明 书 4/6 页 本发明提出了更简洁的网络结构,减少了检测时间,提高了目标检测的效率,本发 明第一次加入了图卷积神经网络模型,在没有物体边框作监督的条件下,利用自身网络产 生伪标注框,通过图卷积神经网络使模型检测出更完整的物体。极大的提升了弱监督目标 检测精度。 附图说明 图1为本发明的弱监督目标检测网络的实现步骤流程图; 图2为本发明的选择性搜索框示意图; 图3为本发明邻接矩阵示意图; 图4为本发明弱监督目标检测网络的网络结构示意图;











