
技术摘要:
一种包括数据架构的集成电路,所述数据架构包括被配置为接收操作数的N个加法器和N个乘法器。所述数据架构接收用于选择所述数据架构的所述N个乘法器和所述N个加法器之间的数据流的指令。所选择的数据流包括以下选项:(1)使用所述N个乘法器和所述N个加法器的第一数据流, 全部
背景技术:
随着基于神经网络的深度学习应用在各个业务部门呈指数增长,基于商品中央处 理单元/图形处理单元(CPU/GPU)的平台不再是合适计算基础来支持性能、功率效率和经济 可扩展性方面不断增长的计算需求。开发神经网络处理器以加速基于神经网络的深度学习 应用已在许多业务领域获得了重大关注,包括成熟的芯片制造商、初创公司以及大型互联 网公司。单指令多数据(SIMD)架构能应用于芯片以加速深度学习应用的计算。 神经网络算法通常需要大矩阵乘法累加运算。因此,加速硬件通常需要大规模的 并行乘法累加结构来加快加速。然而,必须控制这种结构的面积和功率成本需求,以优化硬 件的计算速度并减小芯片数量的大小以节省功耗。
技术实现要素:
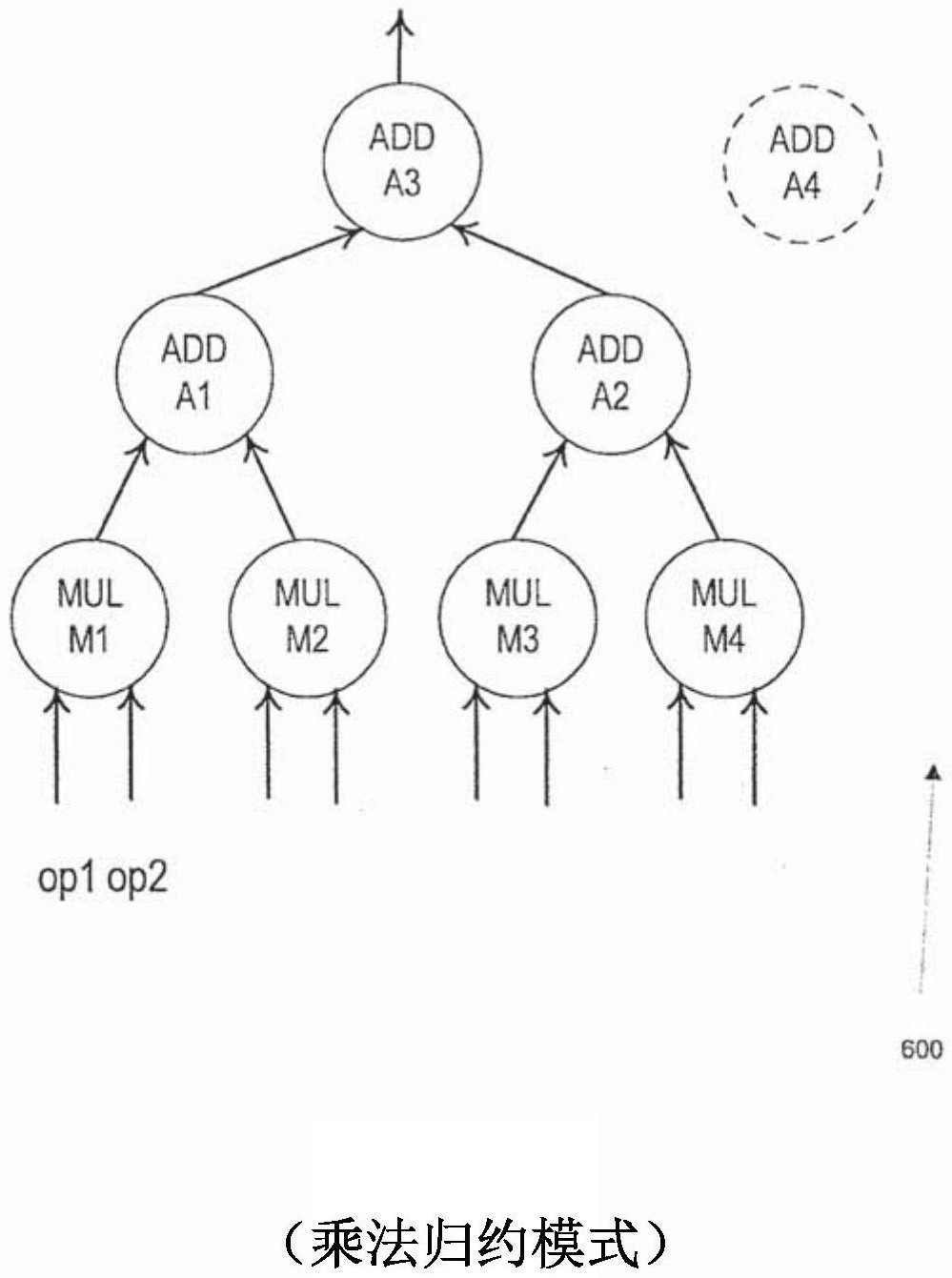
本公开的实施例提供了一种乘法器阵列与加法器阵列之间的软件可编程连接的 架构,以使得能够重用(reuse)加法器以执行乘法累加(multiply-accumulate)或乘法归约 (multiply-reduce)。与传统解决方案相比,此架构在面积和功率上更高效,这对于其中实 现大量数据通道的神经网络处理单元而言是重要的。 本公开的实施例提供了一种用于指定要在数据架构上执行的功能的方法,所述数 据架构包括被配置为接收操作数的N个加法器和N个乘法器。所述方法包括:接收用于所述 数据架构在乘法归约模式或乘法累加模式之一中进行操作的指令;以及基于所述指令,选 择所述数据架构的所述N个乘法器与所述N个加法器中的至少一些之间的数据流。 此外,本公开的实施例包括一种集成电路。所述集成电路包括数据架构,所述数据 架构包括被配置为接收操作数的N个加法器和N个乘法器。所述数据架构接收用于选择所述 数据架构的所述N个乘法器与所述N个加法器之间的数据流的指令。所选择的数据流包括以 下选项:(1)使用所述N个乘法器和所述N个加法器的第一数据流,用于提供乘法累加模式; 以及(2)第二数据流,用于提供乘法归约模式。 此外,本公开的实施例包括一种存储指令集的非暂时性计算机可读存储介质,所 述指令集能由设备的至少一个处理器执行,以使所述设备执行上述方法。 附图说明 图1示出了与本公开的实施例一致的示例性神经网络处理单元芯片架构。 图2示出了具有4个并行通道的乘加阵列的示例性架构。 图3示出了乘法累加器(MAC)单元设计的示例性架构。 4 CN 111615685 A 说 明 书 2/6 页 图4示出了跟随有归约加法器树的并行乘法器的示例性架构。 图5示出了映射通常需要在单个数据通道中和跨通道的累加能力的算法的示例性 架构。 图6A和6B示出了与本公开的实施例一致的乘加阵列的示例性架构。 图7示出了与本公开的实施例一致的用于指定要在数据架构上执行的功能的示例 性方法。











