
技术摘要:
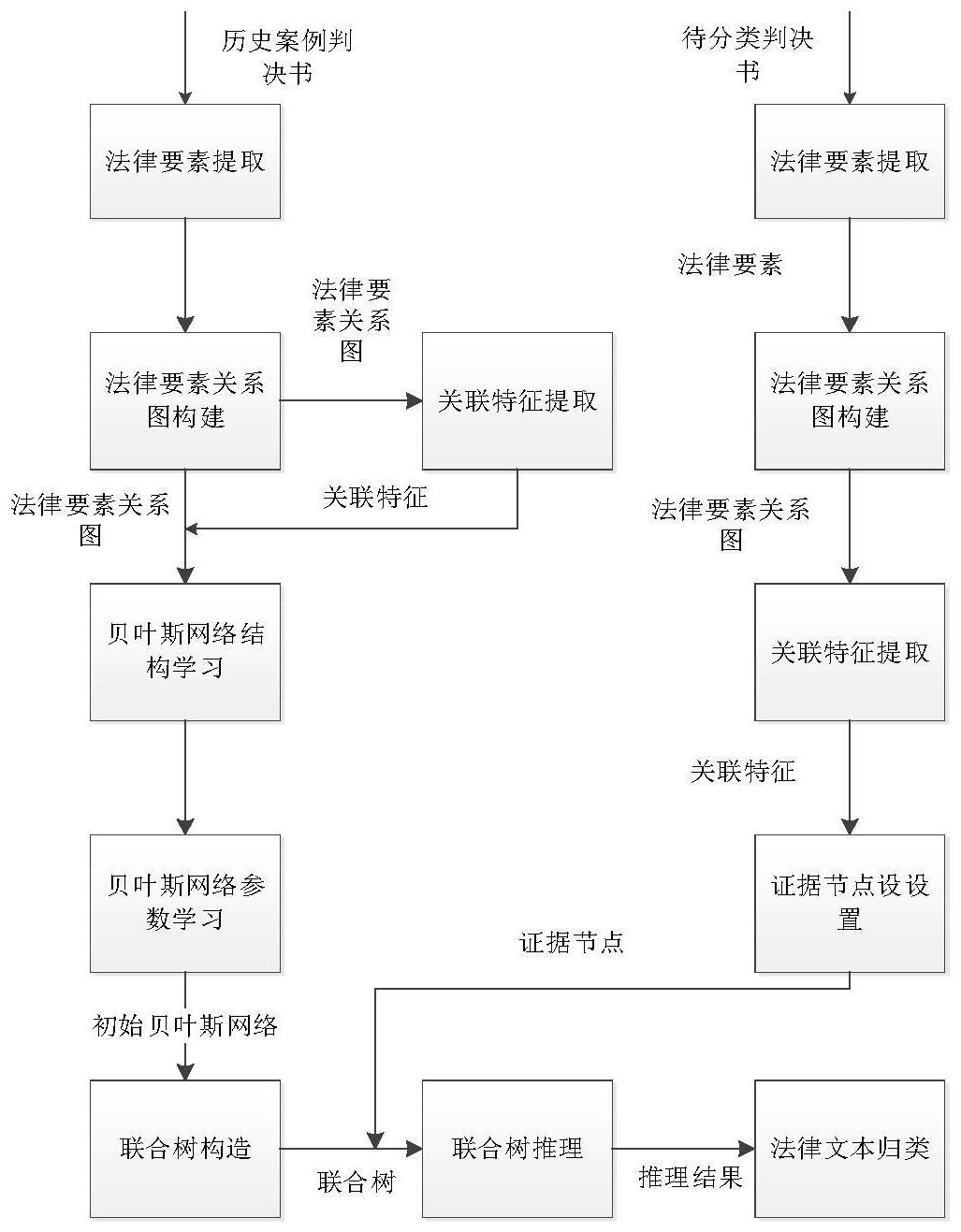
本发明涉及一种基于贝叶斯网络的裁判文书分类方法,包括以下步骤:提取基本法律要素;构建法律要素关系网络;提取关联特征;构建裁判文书贝叶斯网络;构建联合树推理模型,进行推理分类。本发明通过基于平均信息熵的权重指标体系对法律要素的主题表现力进行评估,有效 全部
背景技术:
近年来,我国民事纠纷案件数量呈上升趋势。而纠纷案件的增加,对于案件解决的 效率和案件处理结果的合理性都有着更高的要求。历史民事纠纷裁判文书作为宝贵的材料 对于纠纷的解决有着重要参考作用,通过对历史民事纠纷裁判文书的分析,向相关法务人 员推荐相似的裁判文书,可以帮助案件分析理清争议焦点,协助纠纷双方客观分析现状,拉 近双方的期望值,提高解决纠纷的质量和效率。作为类案推荐的基础,快速而精准地从裁判 文书中提取特征信息,并以此为基础高效地对文书进行分类成为了相关法务工作人员的迫 切需求。 裁判文书的分类相较其他中文文本具有诸多特点。首先,领域知识在法律文本分 类问题中占据重要地位,法律文本的分类问题研究应该在评估特征信息对法律文书主题反 映能力时将司法领域知识融入其中。其次,法律文本案由众多而且相互具有很大的差异性, 不同的案由通常涉及到不同的领域知识,建立一个能够适用各种案由甚至建立一个做到领 域无关的通用模型都是不现实的,将无法客观准确地提取能够反映文本主题的特征信息。 最后,法律文本属于长文本,且各个段落在内容上存在大量冗余,使得文本的特征不突出, 特征信息提取困难。 现有基于词频的特征提取算法未考虑裁判文书存在大量冗余信息及法律要素之 间存在紧密逻辑关系的特殊性,导致提取的法律要素准确率较低。传统文本向量化算法 word2vec受上下文窗口大小所限,容易陷入局部最优,无法准确捕捉法律要素之间的逻辑 关系。现有贝叶斯网络结构学习方法易陷入局部最优,且存在一些难以定向的边,无法习得 最优的裁判文书贝叶斯网络结构。
技术实现要素:
本发明的目的是为了解决上述问题,提出基于贝叶斯网络的裁判文书分类方法 (Classification of Judgment Documents Based on Bayesian Network,CBBN)。 为了达到上述目的,本发明采用的方法是:一种基于贝叶斯网络的裁判文书分类 方法,包括以下步骤: (1)提取基本法律要素,先对裁判文书进行分段操作,之后经过分词,停用词去除 操作得到候选法律要素;接着对候选法律要素进行权重的计算,以衡量其对裁判文书主题 的表现能力,并根据权重大小提取法律要素; (2)构建法律要素关系网络; (3)提取关联特征; (4)构建裁判文书贝叶斯网络; 4 CN 111597331 A 说 明 书 2/13 页 (5)构建联合树推理模型,进行推理分类。 作为本发明的一种改进,裁判文书是一种具有鲜明主题特征的文本,经观察,可按 照“原告陈诉”、“被告辩诉”、“审理查明”、“本院认为”、“判决结果”等五个关键词将裁判文 书分为五个内容模块,这样分割之后,对于不同的法律要素可以有针对性的从五个模块中 进行提取,避免了大量冗余信息的干扰。 作为本发明的一种改进,所述的法律要素权重计算采用基于平均信息熵的法律要 素主题表现力评估方法,综合考虑平均信息熵、位置特征和词频特征三大标准进行计算。 作为本发明的一种改进,所述步骤(2)中,法律要素关系网络的构建过程是先将预 处理过后的裁判文书按照句子划分,对于每个句子,设置固定的滑动窗口,同时出现在同一 个窗口的法律要素之间存在一条边,法律要素在原文中出现的顺序即为边的方向。 作为本发明的一种改进,所述步骤(3)中,关联特征的提取是在法律要素关系网络 的基础上,使用Network Embedding方法得到,其过程为:在网络中选取中心节点,从中心节 点出发进行游走,得到固定长度的游走序列,将节点类比成词项,节点序列类比成句子,之 后放到Word Embedding的Skip-gram模型中训练,得到节点的向量表示。 作为本发明的一种改进,所述步骤(4)中,裁判文书贝叶斯网络的构建分为结构学 习和参数学习两个部分;结构学习的过程分为四步:首先基于前面构建的法律要素关系图 进行贝叶斯网络的初始化,得到一个单连通的无向图,此时图中结点之间关系仅有在原文 中的共现关系;第二阶段根据由Network Embedding得到的关联特征对第一阶段的单连通 图进行增厚,丰富节点之间的关系,得到无向图S;第三阶段在保证无向图S连通的前提下, 基于贪婪搜索的思想对冗余边进行去除;最后,将边权重作为网络的结构评分标准,进行边 定向操作,确定最优结构。 作为本发明的一种改进,参数学习需要在结构学习得到的网络结构基础上进行, 参数学习的过程主要是通过统计法律要素在文档集中出现的频率,学习各个节点的概率分 布表。 作为本发明的一种改进,所述步骤(5)中联合树推理模型的构造主要包括道义化, 三角化,联合树构造三个步骤;道义化的过程为先连接入度大于1的节点的父节点,之后将 所有有向边转化为无向边,得到道义图;三角化的过程为遍历网络中的所有节点,检验节点 与其所连接的节点是否构成长度为3的环,如果不构成,检验其是否存在边,如果不存在,则 添加边将其连接,得到有弦图;联合树构造的过程为将有弦图中的每个“三角”为联合树的 节点,三角之间重合的点和边即为联合树的边,得到联合树。 作为本发明的一种改进,所述步骤(5)中联合树推理的过程为给定的某些节点的 信息,在联合树模型上根据贝叶斯理论对裁判文书所涉案由进行推理,得到分类结果。 具体的算法描述如下: 5 CN 111597331 A 说 明 书 3/13 页 (1)第1-2行是对历史裁判文书和待分类裁判文书两个集合的裁判文书进行预处 理。具体地,先将裁判文书按照“原告陈诉”、“被告辩诉”、“审理查明”、“本院认为”、“判决结 果”等五个关键词分为五个内容模块,这样分割之后,对于不同的法律要素可以有针对性的 从五个模块中进行提取,避免了大量冗余信息的干扰。而对于民事判决书存在的大量冗余 叙述和固定的结构,本文通过对法律要素的定义及分类将其过滤掉,之后基于平均信息熵、 位置特征、词频特征等指标对法律要素进行权重的计算来评估其对案件纠纷性质的表现能 力,根据计算得到的权重提取法律要素。 (2)第3行是对上一步得到的法律要素,根据其在原文本中的共现关系,进行法律 要素关系网络的构建,具体地,选用异构信息网络来存储文本信息,对于民事判决书来说, 一方面,异构信息网络可以表示不同层次的法律要素,及不同法律要素之间的复杂关联关 系;另一方面,异构信息网络也是计算机可以直接读取和处理的数据类型,相较于中文文本 数据,拥有更低的处理难度和更高的处理效率。 (3)第4行是通过Network Embedding算法将法律要素关系网络映射到向量空间, 得到法律要素的向量表示。第5行是根据得到的法律要素向量表示和法律要素关系网络中 法律要素的信息,进行关联特征的提取。关联特征是指两个或多个彼此之间存在共现、语 义、组合等关系的特征信息组合。通过提取关联特征项,不但可以帮助补充提取文本的特征 信息,丰富分类的数据源,还能够帮助贝叶斯网络模型学习最优的网络结构,提高分类的效 果。 (4)第6行是根据法律要素关系网络及提取出的关联特征进行贝叶斯网络的结构 学习,得到完整的判决书贝叶斯网络结构,主要包括初始化、网络增厚、冗余边去除、边定向 等步骤。之后在该网络结构基础上进行参数学习,参数学习的过程主要是通过统计法律要 素在文档集中出现的频率,学习各个节点的概率分布表。 6 CN 111597331 A 说 明 书 4/13 页 (5)第7行是对得到的贝叶斯网络结构进行道义化,先将入度大于1的节点的父节 点相连,再将所有有向边转化为无向边,得到道义图。 (6)第8行是对得到的道义图进行三角化,遍历节点,检验节点与其所连接的节点 是否构成长度为3的环,如果不构成,检验其是否存在边,如果不存在,则添加边将其连接, 得到有弦图。 (7)第9行是对得到的有弦图进行联合树构造,将有弦图中的每个“三角”作为联合 树的节点,三角之间重合的点和边作为联合树的边,得到联合树。 (8)第10行是根据给定的某些节点的信息,在联合树模型上进行推理,得到分类结 果。 进一步的,步骤(1)所述法律要素权重的计算公式如公式1所示: W(w)=α*W1 β*W2 γ*W3 (公式1) 其中W1,W2,W3分别为词w的平均信息熵、位置重要性及频度重要性。为了获得3个特 征参数对于本文研究问题的最优取值,我们采用BP神经网络算法[41]对参数进行训练优化, 首先选取部分已得到的裁判文书并进行人工标注,标注能够反映判决书主题的法律要素, 之后计算所有法律要素的平均信息熵,位置重要性和频度重要性并将其作为BP神经网络的 输入,不断调整参数,对得到的结果取前50%,计算其对人工标注法律要素的命中率。选取 命中率最高时候的α、β、γ取值。 进一步的,步骤(2)所述基于词共现关系的法律要素网络构建算法(Network ConstructionBased on Word Co-occurrence,NCBWC)如下: (21)第1-2行,是表示将法律要素添加到法律要素关系图的节点集合中。 (22)3-7行是将之前得到的法律特征集合以句子为单位,设置固定的时间窗口并 7 CN 111597331 A 说 明 书 5/13 页 按窗口进行滑动,窗口内共现的词项之间建立一条边并添加到法律要素关系图的边集合 中,词项在原文中出现的顺序即为边的方向。 (23)第8行是将所有句子的有向图合并,即得到最终的法律要素关系图模型。 (24)第9行是对法律要素关系图的每条边进行边权重计算,其主要借助了 PageRank的思想,将图中节点看做一个网页,将边的权重看做边所连接节点及其能到达节 点共同作用的结果,利用节点的投票机制对边权重进行迭代计算,其计算公式如公式2所 示: 其中reach(v)和reach(u)代表节点v、u可以到达的节点集合,di,v代表节点i和节 点v之间距离。 进一步的,步骤(3)所述Network Embedding方法中的游走策略,基于节点和边权 重的游走算法(Walk Based on WV and WE)如下: (31)第1行是将初始节点加入游走序列walk中。 (32)第2行是指定初始节点为当前节点, (33)其中第4行是将所有与当前节点直接相连的节点加入到节点集合V中, (34)5-6行是对节点集合V中的每个节点计算转移概率。 (35)第7行是将节点概率最高的节点设置为当前节点, (36)8-11行是检验当前节点的权重是否大于阀值threshold,如果大于等于阀值, 8 CN 111597331 A 说 明 书 6/13 页 则将当前节点加入到游走序列walk中,否则继续对当前节点执行5-11行的步骤。 对于转移概率的计算,引入法律要素关系图节点权重WV,边权重WE,在游走节点的 选择上,综合考虑当前节点可达节点的权重和两节点之间边的权重进行选择,具体的转移 概率PT计算公式如5.2 PT=(αWV βWE)*αpq (5.2) 其中WV和WE分别代表节点和边的权重,αpq是node2vec中的转移概率。α、β为WV和WE 系数。而对于游走策略,我们在序列生成的过程中,引入阀值threshold,目的是针对节点权 重较低,但是其与当前节点相连的边权重较高,导致最终的转移概率高于其他节点的情况, 此时,我们选择这条边,但是并不将该节点加入到游走序列中。因为边的权重是综合边直接 相连节点和间接相连节点计算得到,因此边的权重较高,说明沿着这条边游走,可以找到权 重较高的节点。这样既避免了权重较低节点的加入,又有效地增加了游走的范围。 进一步的,步骤(4)所述基于关联特征的贝叶斯网络结构学习算法(Structure Learning Based on Correlation Features,SLBCF)如下: (41)由于法律要素关系图是根据共现关系构建,在时间窗口为k时,每k个节点之 间存在 条边,冗余边较多,因此我们以窗口k为单位,对每k个节点根据边的权重大小 选取k-1条边进行单连通图的初始化。基于边权重的初始化算法(Initialization Based on Edge Weight,IBEW)如下: 9 CN 111597331 A 说 明 书 7/13 页 第1行指根据时间窗口k,将原法律要素关系图分为num-k个子图。第2-3行是将子 图内的边按照权重降序排列,并挑选前k-1条边加入到序列L中。4-7行是对由这k个节点和 k-1条边组成的子图进行连通检测,如果该子图是单连通图,将其加入到最终的单连通图 中。其中第4-5行是将这k个节点和选出的k-1条边加入到子图Gi中,第6行是对子图Gi进行单 连通检测,第7行是将子图Gi加入到最终结果的单连通图G中。第8-10行是对子图非连通情 况下的处理,按照边权重的排序,再挑选边加入序列L中组成新的子图,进行单连通检测,如 此重复,直到子图Gi连通,将子图Gi加入到最终结果的单连通图G中。循环num-k次得到最终 的单连通图G。 (42)经过初始化得到的单连通图,只包含法律要素在原文中的共现关系。网络增 厚的主要工作是将由Network Embedding提取出的关联关系添加到初始连通图中。对于任 意关联特征{Vi,Vj}节点对<Vi,Vj>,若其在初始图中不相连,则向连通图中添加边<Vi,Vj >,基于关联特征的网络增厚算法(Thicken Based on Correlation Features,TBCF)如 下: 10 CN 111597331 A 说 明 书 8/13 页 第2行对图G上的两个节点vi、vj,通过checkEdge函数检测其在初始图中是否存在 边。若不存在边,则执行第6行,在这两个节点之间添加一条边。 (43)为得到高准确率的贝叶斯网络结构,需要对增厚阶段引入的冗余边予以去 除。在此需要引入评分机制,利用之前计算出来的点和边的权重进行贝叶斯网络的结构评 估。 这一步的主要任务是对连通图中的环进行破除,从长度为3的环开始检测,直到整 个网络。如果检测到环,在保证图连通性的前提下,从权重最小的边开始删除,直到环被破 除。基于边权重的冗余边去除算法(Delete Based on Edge Weight,DBEW)如下: 11 CN 111597331 A 说 明 书 9/13 页 第1行代表从长度为3的环开始检测,直到长度达到网络中节点数。第2-10行利用 环检测函数loopDetect对当前子网络是否存在环进行检测,如果存在环,则对当前子网络 所包含的边按权重降序排列,删除权重最小的边,检测子图是否还连通,若连通则继续进行 直到子网络没有环,若不连通则将第5行操作进行回滚,转而删除权重次小的边。其中第2行 是进行是否有环的检测,第4-10行是进行破环操作,6-9行是删除边后的连通检测。 (44)经过上述步骤,我们得到了一个无向图S,接下来要进行贝叶斯网络的边定向 操作,由于节点和边的权重只能衡量要素之间的关系,即节点之间是否有边,却无法确定边 的具体方向,因此,本节采用BDe评分[44]来评价边的方向对网络结构的影响。本节所述基 于评分-搜索的边定向方法(Edge Orientation Based on Score-Search,EOBSS)如下 12 CN 111597331 A 说 明 书 10/13 页 第1行是对所有的边添加操作和转向操作迭代执行num次,直到BDe评分不再变化, 2-8行是执行添加边操作,保留能使BDe评分增加的边,其中第3行是求得与节点u邻接的节 点集,第4行是添加边v→u,5-8行是检测BDe评分是否增加,若评分增加,则保留操作,否则 执行回退操作。9-14是执行边转向操作,如果评分增加则保留操作,否则回退。 有益效果: 通过基于平均信息熵的权重指标体系对法律要素的主题表现力进行评估,有效过 滤了干扰信息,提高了法律要素提取的准确率;基于异构信息网络的法律要素关系模型,有 效地表示了文本数据;基于Network Embedding的关联特征提取算法有效解决了传统文本 向量化算法受上下文窗口大小限制的问题,能够有效地捕捉法律要素之间的关联关系;基 于关联特征的贝叶斯网络结构学习算法能够保证图的连通性,学习到对于裁判文书来说最 优的网络结构。 13 CN 111597331 A 说 明 书 11/13 页 附图说明 图1为本发明中裁判文书分类方法的流程图; 图2为裁判文书示例; 图3为进行分段处理后的“五段”式文本示例; 图4为滑动窗口为3时对例句1进行关系图构建的结果; 图5为滑动窗口为3时对例句2进行关系图构建的结果; 图6为将图3和图4根据原文关系连接的结果; 图7为贝叶斯网络初始化示例; 图8为贝叶斯网络网络增厚示例; 图9为贝叶斯网络冗余边去除示例; 图10为贝叶斯网络边定向示例; 图11为贝叶斯网络示例; 图12为节点“住房”概率分布表; 图13为节点“抚养费”概率分布表; 图14为联合概率分布表; 图15为道义图示例; 图16为有弦图示例; 图17为联合树示例。











