
技术摘要:
本发明涉及一种基于深度学习的细粒度图像弱监督目标定位方法,用于解决仅使用易于收集的弱监督的语言描述信息来识别和定位细粒度图像的问题。本发明直接在图像的像素级别上和语言描述的word进行模态间的细粒度语义对齐。把图像输入到卷积神经网络中提取特征向量,同时对 全部
背景技术:
探索图像与其自然语言之间的相关性一直是计算机视觉中的一个重要研究领域, 它与图像和文本的双向检索,图像标注,视觉问答(VQA),图像嵌入和zero-shot learning 密切相关。人类使用语言概念来描述他们看到的图像,尤其是如何区分细粒度图像,因此图 像与其语言描述之间存在强烈的相关性。目标检测在图像领域中也有很宽广的应用,但是 现在的很多定位方法非常依赖昂贵而且难以获得的强监督标签。而图像和其语言描述在现 实世界中广泛存在,非常容易获得。所以使用图像和语言描述之间的关系来定位图像中的 对象具有重要意义。这需要我们对细粒度图像定位的更深入的探索。 在先前的一些细粒度和语言描述的匹配工作中,他们只是在全局语义上进行图像 和语言描述的匹配,图像的细粒度信息没有得到充分的体现。因为同一个图像是由不同的 人来描述,描述图像的方式有很大的不同。所以,文本的全局语义信息不是很清晰,每个句 子中表达的局部词语在图像中也不能很好地反映出来。所以这些方法不仅不能挖掘图像中 的细粒度信息,而且还不能定位细粒度图像中的目标。在一些细粒度的图像定位和分类方 法中,他们使用强监督的信息进行定位和分类的,如边界框,物体部位和部位标记。然而,在 实际应用中,获得这些强监督标记是非常昂贵的。 目标检测是计算机视觉的重要领域。R-CNN是两阶段的对象检测器,这是将深度学 习应用于对象检测器的第一项工作。R-CNN使用选择性搜索生成兴趣区域(RoI),然后使用 SVM分类器进行分类。然后Faster R-CNN使用区域提议网络(RPN)生成RoI,它可以端到端训 练网络并进一步提高检测器的速度。为了获得细粒度图像与语言描述之间的足够的关系信 息,一些模型使用ground-truth作为监督信息,提取特定图像区域,然后与语言描述信息对 齐以获得更好的对齐效果。但是,这些方法仅与单个向量空间的匹配有关,而忽略了图像和 语言描述之间的细粒度关系,其他工作则需要强的监督信息。本方法提出了一种新的方法, 在仅使用弱监督语言描述来解决上述问题,并取得很好的定位效果,并且该模型还具有强 大的zero-shotlearning能力,可以轻松迁移到其他数据集。
技术实现要素:
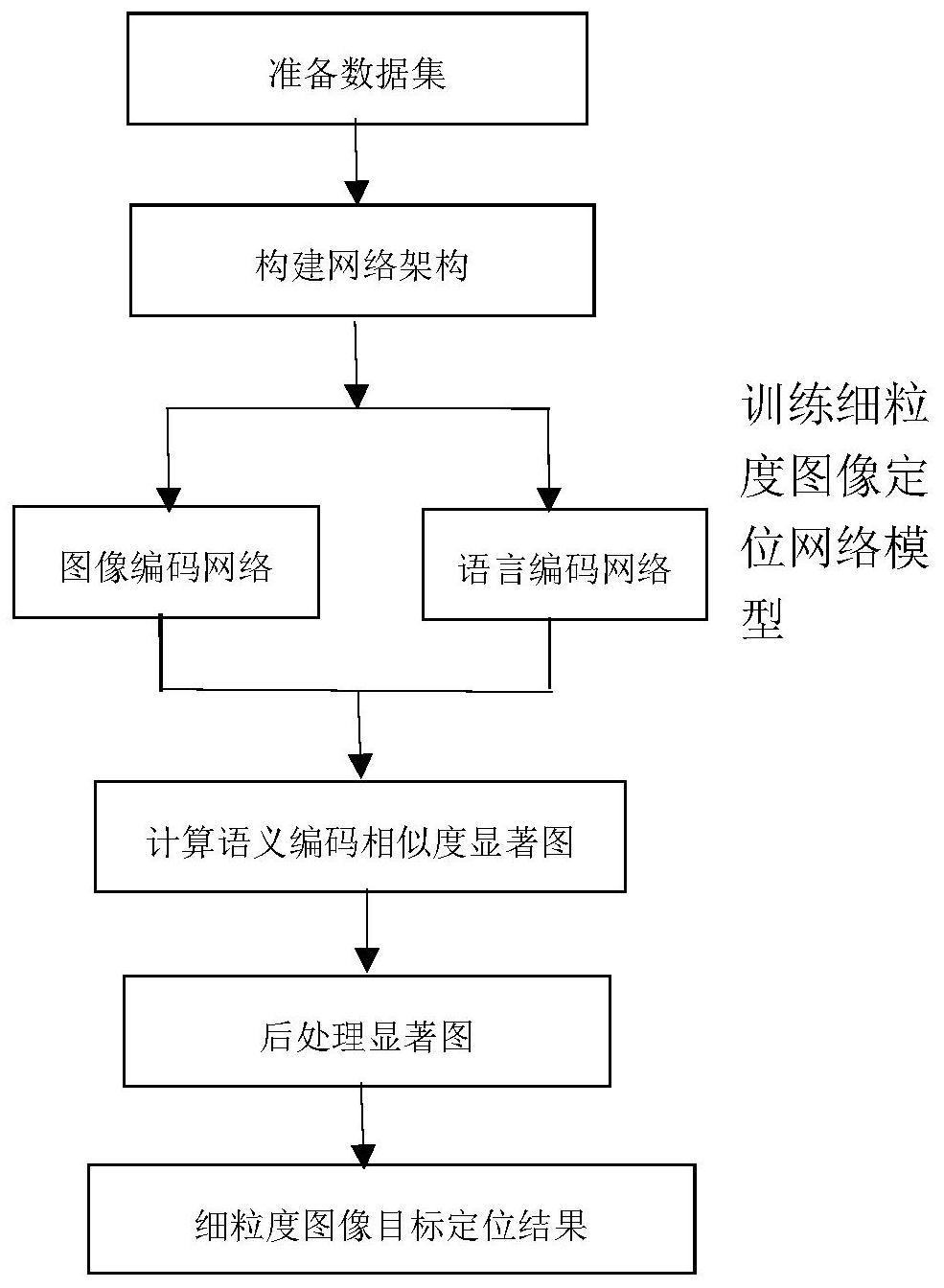
本发明的目的在于,针对上述方法的不足,仅使用易于收集的弱监督的语言描述 信息来识别和定位细粒度图像,并且能够达到很好的定位精度。 实现本发明方法的主要思路是:我们观察到目标对象及其属性经常出现在图像的 语言描述当中。由于细粒度图像具有较大的类内差异和较小的类间差异,目标各个部位与 语言描述中的属性信息之间的对应关系对于区分物体是非常有用的。因此,我们提出了一 个新的框架来匹配和定位细粒度图像。本发明方法直接在图像的像素级别上和语言描述的 3 CN 111598155 A 说 明 书 2/4 页 word进行模态间的细粒度语义对齐。我们把图像输入到卷积神经网络中提取特征向量,同 时对语言描述进行编码,提取出语言描述的特征向量。我们将卷积特征图和语言描述特征 向量进行特征匹配,并对特征匹配图进行处理,得到目标的显著图,根据特征匹配图得到最 终定位的结果。 根据上述主要思路,本发明方法的具体实现包括如下步骤: 步骤1:准备数据集 每个样本均包括一张图像及对应的语言描述句子。 步骤2:构建图像和语言两路网络模型 网络模型是分为图像编码网络和语言编码网络,图像编码网络负责提取并编码图 像语义特征向量,语言网络负责提取并编码语言语义特征向量,然后根据损失函数处理两 个网络的语义特征向量。 步骤3:训练网络模型 对两个网络模型,利用训练样本集,将训练集中的图像和语言分别前向传播经过 该模型的两路,然后将经过该网络计算后得到的损失用反向传播算法调整网络权重,不断 迭代训练两路模型,得到训练后的网络模型。 步骤4:计算图像和语言的相似度显著图并定位目标 从步骤三中训练得到的两个网络模型后,将测试样本集中的每张图像和对应的语 言作为输入分别作为两个网络模型的输入,经前向传播得到测试样本集的图像和语言的语 言编码特征向量,然后进行相似度的计算(点积),得到相似度显著图maskmap,然后根据 maskmap矩阵的平均值作为阈值筛选目标,然后经过FloodFill算法处理点噪音点,最后根 据显著区域的最小外接四边形得到目标位置 本发明与现有技术相比,具有以下明显的优势和有益效果:本发明提出一种基于 深度学习的弱监督定位方法,采用图像和语言两路网络模型,训练出的网络模型能够对图 像和语言进行语义编码,实现端到端的学习和目标定位。网络能将从不同模态的数据进行 语义编码,计算相关性关系,在不需要强监督的标注边界框的情况下,解决了细粒度图像的 弱监督目标定位。 附图说明 图1为本发明所涉及方法总流程框图; 图2为本发明所涉及的细粒度图像定位网络模型的架构图; 图3为本发明所涉及的图像编码网络结构; 图4为本发明所涉及的语言编码网络结构; 图5为本发明所涉及的相似度计算和定位方法图;











