
技术摘要:
本发明公开一种基于多头自注意力机制的动态元嵌入方法。所述方法包括:将输入句子中的每个词表示为词向量序列,将每个词向量映射到同一维度,基于多头自注意力机制计算嵌入矩阵,得到元嵌入表示的词向量矩阵。本发明利用多头自注意力机制进行多次计算,解决了现有DME、 全部
背景技术:
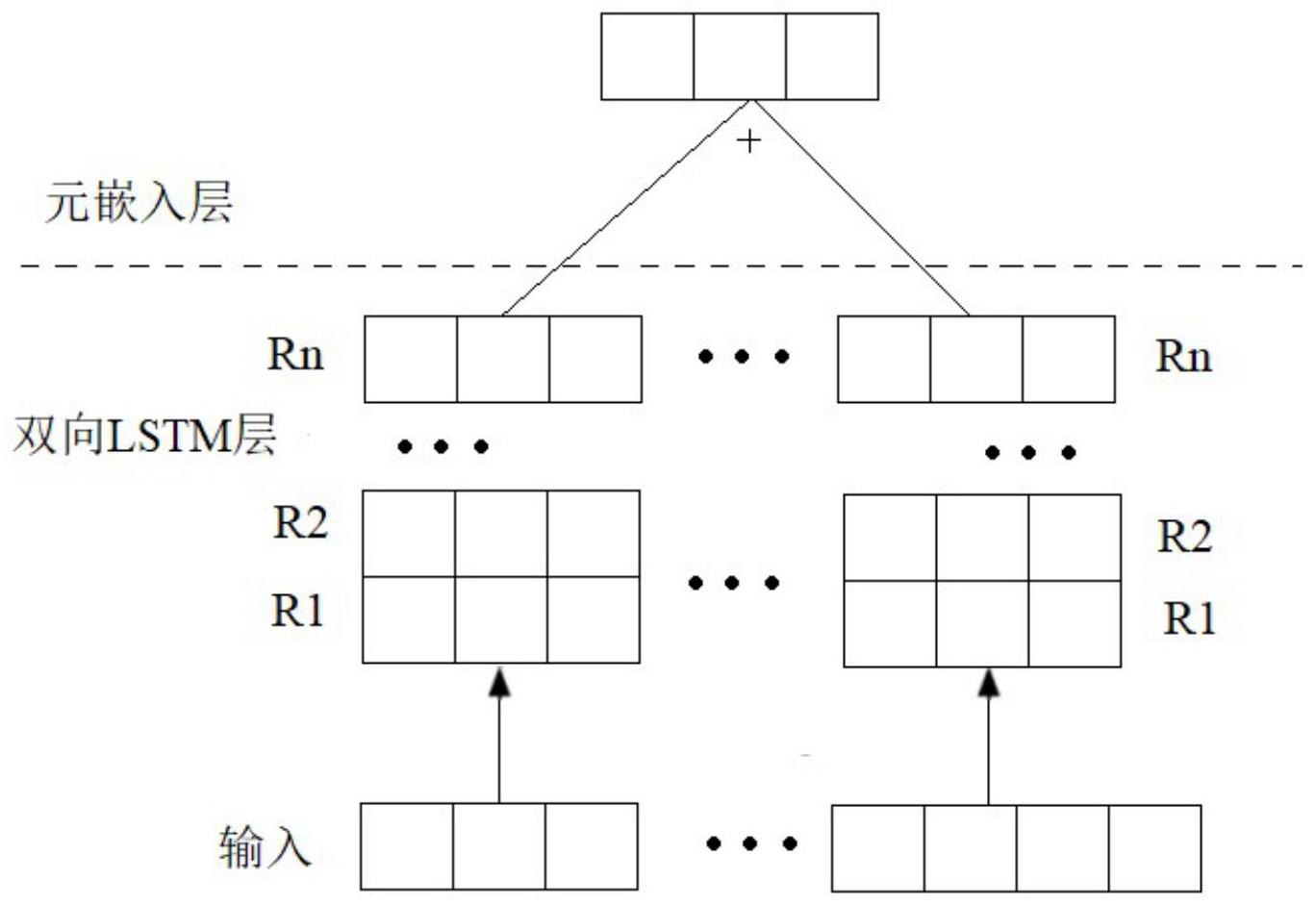
深度学习中的词向量(单词的分布式表示,也称为词嵌入)对自然语言处理的许多 任务中都有应用。近年来,Word2Vec、GloVe等预训练嵌入集得到了广泛应用。元嵌入学习是 是集成词嵌入的一种技术,目的是将同一个词的不同词嵌入通过某种方式融合得到新的词 向量表示。元嵌入学习得到的元嵌入捕获了不同嵌入集中词法语义的互补信息。 元嵌入学习包括静态元嵌入和动态元嵌入。静态元嵌入把元嵌入学习作为预处理 过程。CONC、SVD、1TON和1TON 是常用的四种基线静态元嵌入学习方法。前三种方法在嵌入 集的重叠词汇上学习元嵌入。CONC串联来自不同嵌入集的单词向量。SVD在CONC的基础上执 行降维操作。1TON假设存在该单词的元嵌入,比如一开始随机初始化元嵌入,并使用该元嵌 入通过线性投影预测单个词向量集中该单词的表示,进行了微调的元嵌入期望包含来自所 有嵌入集的知识。在静态元嵌入学习中,会遇到这样的未登录词问题:单词A在嵌入集M中出 现,但是在嵌入集N中没有录入。为了解决未登录词问题,1TON 首先随机初始化OOV(Out- of-vocabulary)和元嵌入的向量表示,然后使用类似于1TON的预测设置来更新元嵌入和 OOV嵌入。因此,1TON 同时达到两个目标:学习元嵌入和扩展词汇表(最终会是所有嵌入集 词汇表的并集)。动态元嵌入将集成词向量的过程融入到特定NLP(Natural Language Processing,自然语言处理)任务端到端模型的过程中,使得模型可以根据特定任务自主选 择不同词向量的权重。将元嵌入思想应用于句子表示,可以动态地学习不同嵌入集的注意 力权重。计算权重的基本框架包括元嵌入层、句子编码层、匹配层和分类器。嵌入层采用DME (dynamic meta-embeddings)算法,利用自注意力机制和门控函数,动态计算集成各个嵌入 集的权重;也可采用上下文相关的CDME(contextualized DME)算法来增强投影嵌入,用双 向的长短时记忆网络LSTM(Long Short-Term Memory)替代简单的线性映射。 DME和CDME动态元嵌入算法,使用句子级别的自注意力来确定不同嵌入集的权重, 其中自注意力方法着重于学习各个词向量线性回归的参数,缺乏多角度的综合考虑,很容 易造成元嵌入权重的学习不充分。
技术实现要素:
为了解决现有技术中存在的上述问题,本发明提出一种基于多头自注意力机制的 动态元嵌入方法。 为实现上述目的,本发明采用如下技术方案: 一种基于多头自注意力机制的动态元嵌入方法,包括以下步骤: 步骤1,将输入句子中的每个词表示为词向量序列 wi ,j为嵌入第i个嵌入 集的第j个词,j=1,2,…,s,s为句子中词的数量,i=1,2,…,n,n为嵌入集的数量; 3 CN 111581351 A 说 明 书 2/4 页 步骤2,通过一个全连接层将每个词向量映射到同一维度,表示为: w′i,j=piwi,j ci (1) 其中,pi、ci为学习参数; 步骤3,基于多头自注意力机制计算嵌入矩阵,按(2)~(5)式得到元嵌入表示的词 向量矩阵B=[w″i,j]n×s: XR×1=(x1,x2,…,x TR) (5) 其中,ar、br和xr为学习参数,r=1,2,…,R,R为多头自注意力机制的计算次数,A1×R 为嵌入矩阵,φ为softmax或sigmoid门控函数。 与现有技术相比,本发明具有以下有益效果: 本发明通过将输入句子中的每个词表示为词向量序列,将每个词向量映射到同一 维度,基于多头自注意力机制计算嵌入矩阵,得到元嵌入表示的词向量矩阵,实现了词向量 序列的动态嵌入。本发明由于利用多头自注意力机制进行多次计算,解决了现有动态元嵌 入(DME、CDME)使用句子级别的自注意力确定不同嵌入集的权重,其中自注意力方法侧重学 习各个词向量线性回归的参数,缺乏多角度的综合考虑,容易造成元嵌入权重的学习不充 分的问题。 附图说明 图1为基于多头自注意力机制进行动态元嵌入的结构框图。











