
技术摘要:
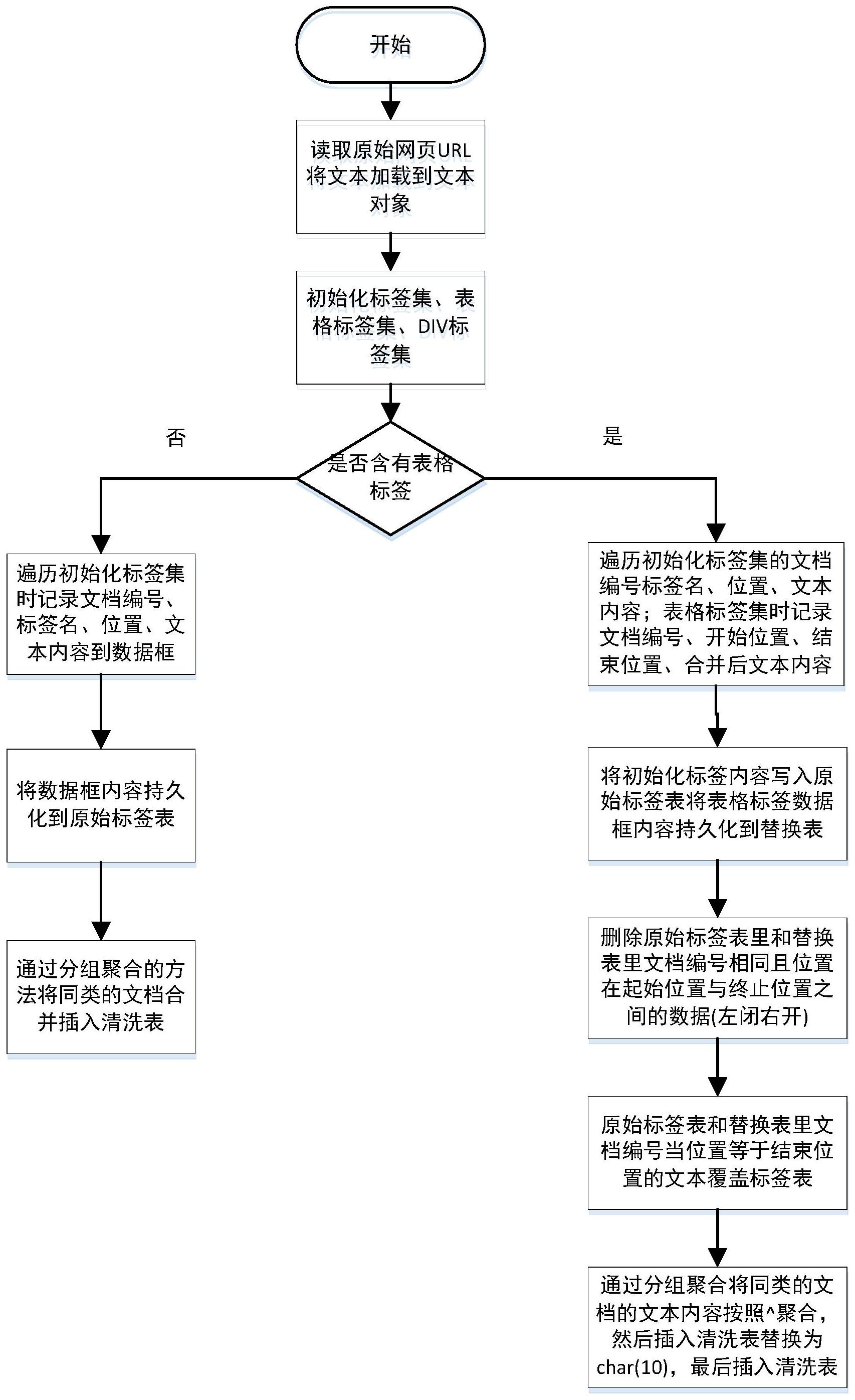
本发明公开了一种基于网页标签位置的文本格式化清洗方法,包括以下步骤:S1:遍历整个网页的所有标签,并记录各个标签名、标签的位置、文本内容、文档编号到原始表;S2:若网页中含有表格数据,将网页中的表格数据进行按行和列动态遍历,提取关键信息得到替换表;S3: 全部
背景技术:
众所周知网页使用的是HTML标记类语言,它里面的标签代表一定的格式。比如 table标签是一个表格(类似excel里的表格),tr是表格里的行,td就是行里的单元格。网页 文本解析又称网页文本内容提取,该技术就是剔除原始网页内的标记,但同时保留原有的 格式的一项提取技术。提取清洗后的文本可用作信息展示、数据整合、数据持久化、数据分 析等各种场景。该技术主要应用到爬虫、正则表达式、规则提取等相关文本处理技术。 现有网页文本解析技术针对每个网页,需要额外编写定制的清洗规则,应用于内 容较多的网页时,文本内容的提取效率较低,同时会出现部分内容缺失,对标签(特别是表 格)解析时,会出现换位以至于跟原网页格式相差较大。 因此亟需提供一种新型的基于网页标签位置的文本格式化清洗方法来解决上述 问题。
技术实现要素:
本发明所要解决的技术问题是提供一种基于网页标签位置的文本格式化清洗方 法,适合不定长度表格和批量处理,能够提高网页文本解析的准确度。 为解决上述技术问题,本发明采用的一个技术方案是:提供一种基于网页标签位 置的文本格式化清洗方法,包括以下步骤: S1:遍历整个网页的所有标签,并记录各个标签名、标签的位置、文本内容、文档编 号到原始表; S2:若网页中含有表格数据,针对网页中的表格数据进行按行和列动态遍历,并将 每个表格单位格的内容合并成按照制表符分割的字符串,记录文档编号、字符串、表格标签 起始位置、终止位置到替换表; S3:将原始表和替换表通过文档编号匹配,删除原始表里与替换表里文档编号相 同且表位置在替换表的起始位置和终止位置之间的数据,更新原始表表位置等于替换表终 止位置的数据,并将清洗后的数据输出到清洗表; S4:若网页中没有表格数据,将网页里DIV所对应的文本提取出来,提取文档编号、 文本内容到数据框后持久化到原始表,通过分组聚合的方法,将同类的文档合并插入清洗 表中,完成网页文本的清洗。 在本发明一个较佳实施例中,步骤S1的具体步骤包括: S101:读取原始网页的网络地址,将该网页的内容转换为树形结构的文档对象; S102:遍历所述树形结构的文档对象,提取包含所有标签、样式、文本内容的初始 化标签集、包含表格信息的表格标签集、包含DIV的DIV标签集; 3 CN 111597292 A 说 明 书 2/4 页 S103:遍历初始化标签集,并初始化首次出现的标签,标识为0;若标签名是DIV和 SCRIPT则继续循环;若首次出现标识等于当前标签的位置,则继续循环;若首次出现标识不 等于当前标签的位置,则清洗含空格、半角空格、全角空格、不间断空格的文本内容,并重置 初始化标签等于当前的标签位置; S104:将初始化标签集的文档编号、标签名、标签的位置、文本内容记录到数据库, 并持久化到原始表中。 在本发明一个较佳实施例中,步骤S2的具体步骤包括: S201:先遍历每一个表格列表对象,记录当前的位置为开始位置,再逐个遍历tr列 表对象,记录td列表的最后一个位置为结束位置,对同是一行的标签提取文本内容; S202:提取文本时,清洗原始网页里可能存在的空格、半角空格、全角空格、不间断 空格,按照制表符分隔同一行数据合并成新的文本; S203:将上述过程中的文档编号、标签开始位置、标签结束位置、合并后的文本内 容集中输出到数据框后,再持久化到原始表。 在本发明一个较佳实施例中,步骤S3的具体过程为: 在数据库侧匹配原始表里和替换表里文档编号的数据,将原始表里与替换表里文 档编号相同且表位置在替换表的起始位置和终止位置之间的数据删除; 匹配原始表里和替换表里文档编号的数据,将替换表结束位置与原始表位置相同 的文本覆盖原原始表的文本; 通过分组聚合的方法将同类的文档按照一特殊标记字符合并成一条记录,再插入 清洗表前将文本字段替换成换行符,最终完成网页文本的清洗。 本发明的有益效果是: (1)本发明基于网页标签位置提取网页文本,可提高文本解析的准确度,基于网页 标签位置的提取是基于网页原始结构,相比于正则表达式或规则提取的方式更全面、完整; (2)本发明适合批量处理,支持大量历史数据的全量提取;因为后端处理网页文本 时是以存储过程的方式,所以可以对大量历史数据进行批量更新; (3)本发明对表格采取了动态遍历的方式,所以可以兼容任意长度的表格,适合不 定长度表格,保留网页原始的表格格式,同时也能识别整个网页里所有的表格; (4)本发明采用文本解析和清洗分离的联调和核对,使提取的网页文本内容能够 持久化存储,方便核对。 附图说明 图1是本发明基于网页标签位置的文本格式化清洗方法的流程图; 图2是所述原始表的示例图; 图3是所述替换表的示例图; 图4是所述清洗表的示例图。











