
技术摘要:
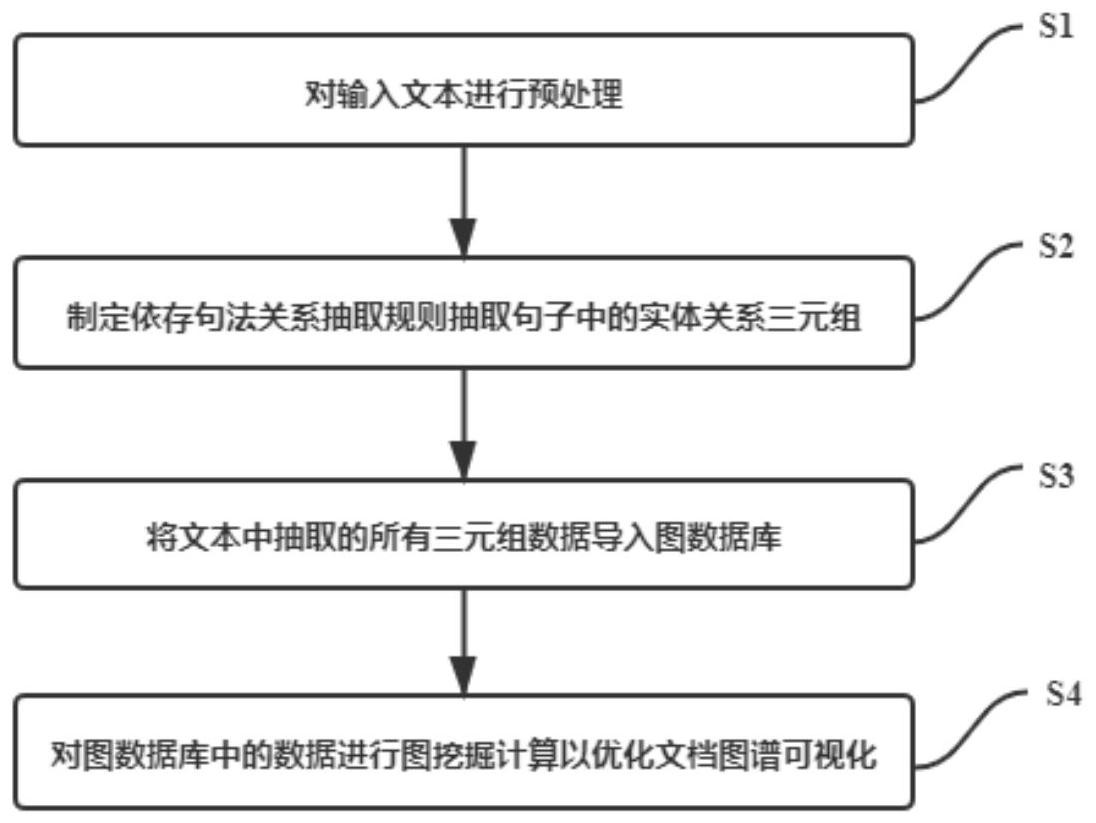
本发明公开了一种可视化文档图谱构建方法,其包括如下步骤:S1,依序对输入文本抽取关键词及对输入文本进行分句,并对分句生成的各单句进行分词,并对分词形成的各单词依序进行词性标注、命名实体识别和依存句法分析;S2:制定关系抽取规则,并基于关系抽取规则从S1所 全部
背景技术:
在互联网信息爆炸的时代,人们很难从非结构化文本信息中快速而准确地获取文 档主旨内容,尤其是报告、论文、报道等长文本文档,信息过载更加严重。因此,对各类文本 进行一个“降维”处理显得非常必要。其中一种常见的方式是形成文本摘要,即对原文本进 行归纳与总结,以简洁文本来概括文章的主要内容,但这种自然语言信息表达方式并不能 使人们直观清晰地获取到所需信息。在2012年,谷歌提出了知识图谱概念。知识图谱本质上 是一种基于图的数据结构,由节点(point)和边(edge)组成。知识图谱的每个节点表示实 体,每条边为实体与实体之间的关系。因此,如何基于知识图谱的概念设计出一种文档图谱 构建方法,实现将文本信息转化为图形格式并简化图文内容,以帮助用户感知和分析文章 语义信息,是本领域技术人员需要研究的方向。
技术实现要素:
本发明的目的是提供一种可视化文档图谱构建方法,能够抽取文本的关键信息, 并基于语义关联将文档映射为可视化图谱,并简化图谱复杂度帮助用户高效掌握文章信 息。 其采用的技术方案如下: 一种可视化文档图谱构建方法,其包括如下步骤:S1,依序对输入文本抽取关键词 及对输入文本进行分句,并对分句生成的各单句进行分词,并对分词形成的各单词依序进 行词性标注、命名实体识别和依存句法分析;S2:制定关系抽取规则,并基于关系抽取规则 从S1所得各单句中抽取三元组数据;所述三元组数据由两个实体词和一个关系词构成;S3: 将S2所得三元组数据导入图数据库,形成文档图谱;S4:对图数据库中的数据进行图挖掘运 算,基于挖掘运算实现文档图谱可视化。 通过采用这种技术方案:首先对文档进行关键信息抽取,基于抽取到的关键信息 挖掘输入文本中各个实体词之间的语义关联,并转化为“节点-边-节点”的图谱形式。并基 于图挖掘计算实现和优化该图谱的可视化。通过将抽象的数据映射为图形元素,帮助用户 有效地感知和分析文章语义信息。在上述过程中,采用基于逗号、句号、感叹号和问号对文 本进行分割完成分句。而命名实体识别过程抽取的是句子中的人物、地点和机构这些具体 特定意义的词项。 优选的是,上述可视化文档图谱构建方法中:步骤S1中基于TextRank算法对输入 文本提取关键词。 通过采用这种技术方案:可只保留文本中名词性词汇参与TextRank权重计算,并 通过设定阈值过滤掉一部分关键词。 更优选的是,上述可视化文档图谱构建方法中:步骤S1中在进行命名实体识别时 3 CN 111597351 A 说 明 书 2/6 页 引入外部词典;所述外部词典包括人名、地名和机构名称。 通过采用这种技术方案:通过引入人名、地点以及机构等外部词典,能够有效提升 命名实体识别的准确率。 进一步优选的是,上述可视化文档图谱构建方法中:步骤S2中所述关系抽取规则 采用依存句法分析结合中文语法规则构建,其包括isA规则和非isA规则。 通过采用这种技术方案:在依存句法结构中,主要标注关系包括:主谓关系、动宾 关系、前置宾语、动补结构、状中结构、介宾关系等。将这些结构中的几个结构组合映射为关 系句法规则,应用于实体关系抽取。isA规则以“是”系动词为连接,包括实体与关系词有依 存关系的规则、实体与关系词无依存关系的规则两类。非isA规则是以系动词之外的动词为 连接,主要包含“主谓宾”、“主谓介宾”、“主谓补宾”、“前置介宾”四类句法结构的规则;此 外,非isA规则还包含句子无主语的规则,该规则表示句子不存在主语,存在一个实体能与 某个动词直接建立动宾关系或间接建立介宾、动补宾等关系,根据中文启发式规则追溯该 句子的前一个句子,以前一个句子核心动词的主语作为该句的主语,抽取相应的三元组。 进一步优选的是,上述可视化文档图谱构建方法中,步骤S3包括如下步骤:S31:分 别建立各实体词之间基于语义的关联;S32:分别建立输入文本与各抽取的实体词之间的关 联,存储于图数据库中并赋予唯一节点名称;S33:对S31和S32所得各关联赋予文档ID。 通过采用这种技术方案:所述建立语义关联是指以三元组中的实体词对应到图数 据库中的节点,以关系词对应到图数据库中的边,节点间通过边相连形成关系网络;实体词 根据其类型标记为不同的Label;S32中通过建立实体与文档的关联可从全局图谱中获取每 篇文档的子图谱。为避免冗余,存储于图数据库中各节点的名称是唯一的;通过对各关联赋 予文档ID(即加上fileID属性),实现了区分节点间关系的所属文档。所述文档ID采用系统 自动生成的唯一性标识或预存人工设定的唯一性标识。 进一步优选的是,上述可视化文档图谱构建方法中,步骤S4包括如下步骤:S41:计 算文档图谱中各节点与其他节点的关联数;S42:基于节点权重公式分别计算各个节点的权 重;S43:将存在同种关系的各个节点进行关系合并;S44:将S43所得数据导入前端进行可视 化展示。 通过采用这种技术方案:步骤S41计算所得文档图谱中各节点与其他节点的关联 数即为各节点的度中心性,度中心性是在网络分析中刻画节点中心性的最直接度量指标。 一个节点的度中心性越高,该节点在网络中就越具有凝聚力。图谱展示围绕度中心性最高 的TOP前N个节点展开。同时在步骤S42计算各个节点的权重,目的是根据权重大小设置不同 的节点展示大小,突出文本内容侧重点。通过步骤S41和步骤S42,简化了最终生成的图谱网 络的复杂度、便于用户对图谱的理解。 更进一步优选的是,上述可视化文档图谱构建方法中:步骤S42中所述节点权重公 式为 所述Wij为第i个文档图谱第j个节点的最终权重值;所述Dij为第i个文档图谱中第 j个节点与该文档谱图内其他节点的关联数;所述T为存入图数据库中的文档数;所述Nj表 示含有节点j的文档图谱数目。 通过采用这种技术方案:以上述权重公式计算各个节点的权重,不仅可以突显同 4 CN 111597351 A 说 明 书 3/6 页 一文档不同节点的重要性,同时可以突出含有某些相同节点的文档之间的差异性。 与现有技术相比,本发明能够基于依存句法关系抽取规则抽取文档中实体间的语 义关系形成可视化的文档图谱,能够更加清晰直观地揭示文章主旨内容,突出各文档图谱 内容的重点与不同点,同时简化了图谱网络的复杂度、便于用户高效掌握图谱信息。 附图说明 下面结合附图与











