
技术摘要:
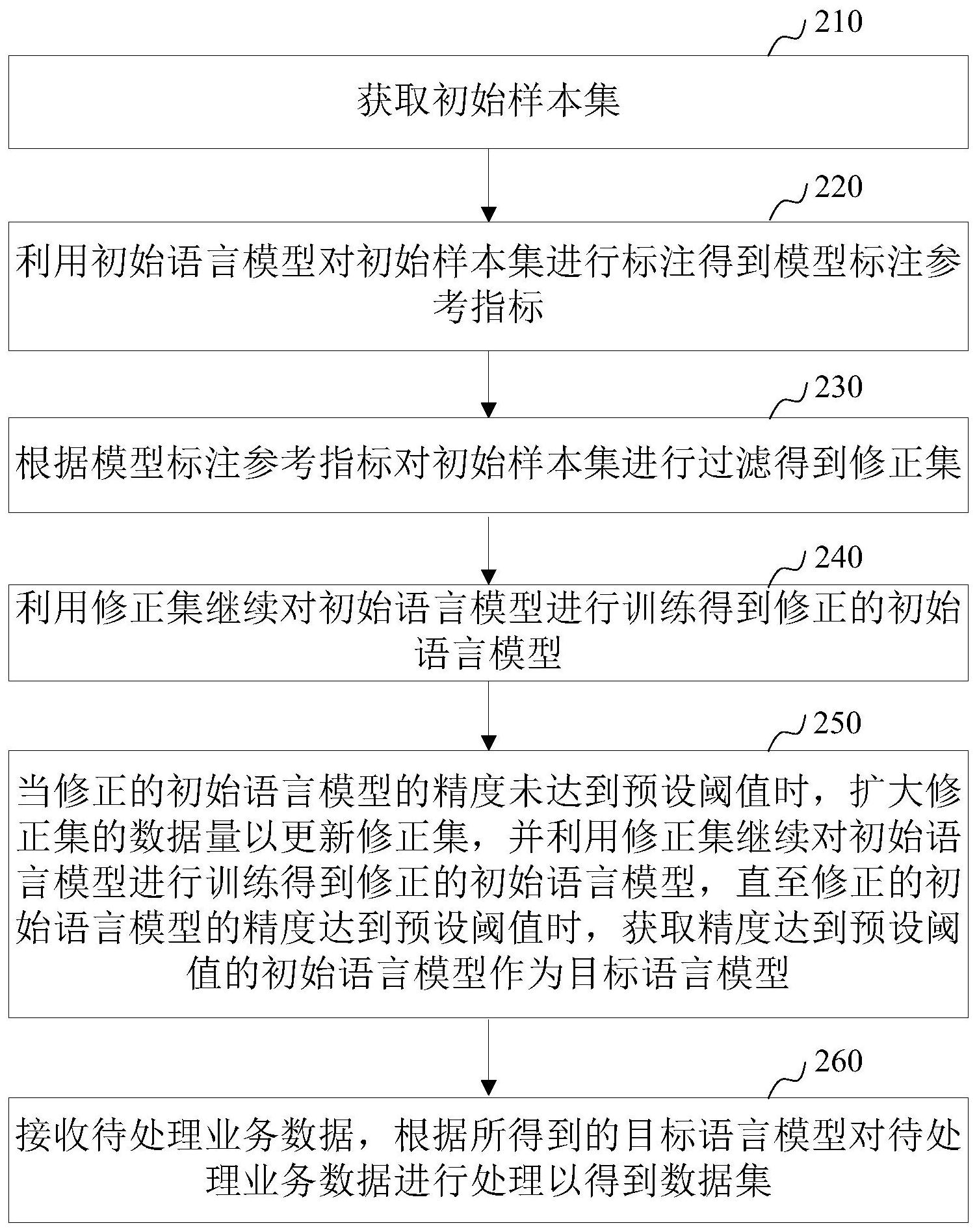
本申请涉及一种基于人工智能的数据集获取方法、装置、设备和介质。方法包括:获取初始样本集;利用初始语言模型对初始样本集进行标注得到模型标注参考指标;根据模型标注参考指标对初始样本集进行过滤得到修正集;利用修正集对初始语言模型进行训练得到修正的初始语言 全部
背景技术:
在人工智能的开发过程中,目前业界普遍采用数据驱动的方式,因此数据质量是 重中之重。数量多、质量好、覆盖面完整的数据能够帮助开发者更快的研发出效果更好的模 型,从而提升客户的满意度。 在训练模型的过程中需要对数据进行标注,目前在获取到日志数据后,利用计算 机进行内容提取和数据审核,但是对于日志数据进行处理的时候,机器在不知道正确信息 的前提下,则无法从大量的日志数据中确定正确的数据,从而使得数据标注失败导致无法 获取正确的数据集。
技术实现要素:
基于此,有必要针对上述技术问题,提供一种能够数据集获取效率的基于人工智 能的数据集获取方法、装置、计算机设备和存储介质。 一种基于人工智能的数据集获取方法,方法包括: 获取初始样本集; 利用初始语言模型对初始样本集进行标注得到模型标注参考指标; 根据模型标注参考指标对初始样本集进行过滤得到修正集; 利用修正集继续对初始语言模型进行训练得到修正的初始语言模型; 当修正的初始语言模型的精度未达到预设阈值时,扩大修正集的数据量以更新修 正集,并利用修正集继续对初始语言模型进行训练得到修正的初始语言模型,直至修正的 初始语言模型的精度达到预设阈值时,获取精度达到预设阈值的初始语言模型作为目标语 言模型; 接收待处理业务数据,根据所得到的目标语言模型对待处理业务数据进行处理以 得到数据集。 在其中一个实施例中,获取初始样本集,包括: 获取业务数据; 从业务数据中提取语义相近的业务问题组成业务问题集,将业务问题集作为初始 样本集。 在其中一个实施例中,从业务数据中提取语义相近的业务问题组成业务问题集, 将业务问题集作为初始样本集,包括: 从业务数据中提取业务问题; 识别各业务问题对应的语义向量; 计算各语义向量之间的语义相似度; 4 CN 111723870 A 说 明 书 2/12 页 根据各语义相似度将业务问题划分为多个业务问题集,将业务问题集作为初始样 本集。 在其中一个实施例中,初始语言模型的获取方法包括: 获取预先训练的通用语言模型; 利用初始样本集对通用语言模型进行训练得到具有预测业务数据能力的初始语 言模型。 在其中一个实施例中,根据模型标注参考指标对初始样本集进行过滤得到修正 集,包括: 获取初始样本集中各待处理问题对应的模型标注参考指标; 当模型标注参考指标与标准标注指标不匹配时,将不匹配的待处理问题从初始样 本集中删除,根据删除后的样本集得到修正集。 在其中一个实施例中,当模型标注参考指标与标准标注指标不匹配时,将不匹配 的待处理问题从初始样本集中删除,根据删除后的样本集得到修正集之后,还包括: 将不匹配的待处理问题提取为过滤样本集; 对过滤样本集中的各模型标注参考指标进行校验; 当校验失败时,将校验失败的待处理问题添加至修正集。 在其中一个实施例中,当修正的初始语言模型的精度未达到预设阈值时,扩大修 正集的数据量以更新修正集,并利用修正集继续对初始语言模型进行训练得到修正的初始 语言模型,直至修正的初始语言模型的精度达到预设阈值时,获取精度达到预设阈值的初 始语言模型作为目标语言模型,包括: 获取修正集中各待处理问题对应的标准标注指标; 将各待处理问题对应的模型标注参考指标与标准标注指标进行比对,得到模型标 注参考指标对应的标注准确率; 当标注准确率小于预设阈值时,扩大修正集的数据量以更新修正集,并利用修正 集继续对初始语言模型进行训练得到修正的初始语言模型,直至修正的初始语言模型的标 注准确率达到预设阈值时,获取标注准确率达到预设阈值的初始语言模型作为目标语言模 型;将初始样本集、修正集以及数据集存储于区块链中。 一种基于人工智能的数据集获取装置,装置包括: 样本获取模块,用于获取初始样本集; 标注模块,用于利用初始语言模型对初始样本集进行标注得到模型标注参考指 标; 数据修正模块,用于根据模型标注参考指标对初始样本集进行过滤得到修正集; 模型修正模块,用于利用修正集继续对初始语言模型进行训练得到修正的初始语 言模型; 目标模型获取模块,用于当修正的初始语言模型的精度未达到预设阈值时,扩大 修正集的数据量以更新修正集,并利用修正集继续对初始语言模型进行训练得到修正的初 始语言模型,直至修正的初始语言模型的精度达到预设阈值时,获取精度达到预设阈值的 初始语言模型作为目标语言模型; 数据集获取模块,用于接收待处理业务数据,根据所得到的目标语言模型对待处 5 CN 111723870 A 说 明 书 3/12 页 理业务数据进行处理以得到数据集。 一种计算机设备,包括存储器和处理器,存储器存储有计算机程序,处理器执行计 算机程序时实现上述方法的步骤。 一种计算机可读存储介质,其上存储有计算机程序,计算机程序被处理器执行时 实现上述方法的步骤。 上述基于人工智能的数据集获取方法、装置、计算机设备和存储介质,首先利用初 始语言模型对获取到的初始样本集进行标注得到模型标注参考指标,为了进一步地提高语 言模型的标注精度,根据模型标注参考指标对初始样本集进行过滤以得到修正集,然后利 用修正集继续对初始语言模型进行训练得到修正的初始语言模型,并计算修正的初始语言 模型对应的模型精度,当修正的初始语言模型的精度未达到预设阈值时,继续扩大修正集 的数据量以更新修正集,并利用更新后的修正集继续对初始语言模型进行修正,直至修正 的初始语言模型的精度达到预设阈值时,将精度达到阈值时的初始语言模型作为目标语言 模型。实现了不断更新修正集对语言模型进行修正,保证了语言模型的预测精度,然后将获 取到的待处理业务数据输入至精度满足要求的语言模型中得到数据集,实现了利用语言模 型自动对业务数据进行标注,以及快速获取到精度高的数据集的技术效果。 附图说明 图1为一个实施例中基于人工智能的数据集获取方法的应用环境图; 图2为一个实施例中基于人工智能的数据集获取方法的流程示意图; 图3为一个实施例中提供的一种获取初始样本集的流程示意图; 图4为一个实施例中基于人工智能的数据集获取装置的结构框图; 图5为一个实施例中计算机设备的内部结构图。











