
技术摘要:
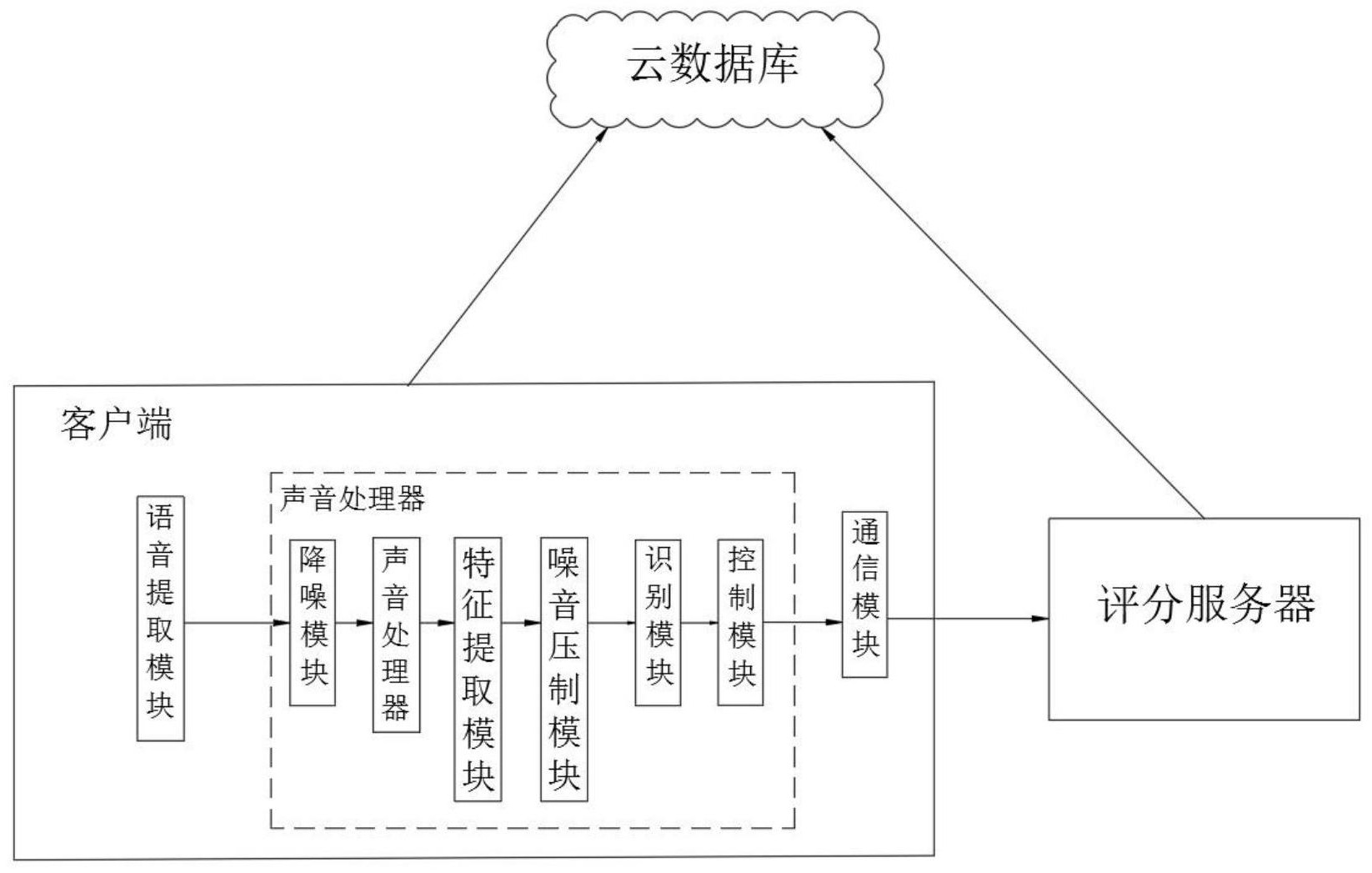
本发明公开了一种基于声音识别的英语口语朗读自动评分系统,包括互相连接的客户端、评分服务器以及云数据库;所述客户端包括语音提取模块、声音处理器、通信模块;所述语音提取模块通过录音装置录得用户的口语声音,并转化成数字信号输出至声音识别器;所述声音处理器 全部
背景技术:
随着计算机科学技术的发展,信息技术已经被广泛地应用到教育教学中,它丰富 了教学资源,改善了学习环境,使学生的学习方式和教师的教学方式发生了根本的变化。另 一方面,随着人工智能、声学、语言学的发展,语音智能技术已经成为一种新型的信息技术, 语言教学逐渐向着计算机辅助教学迈进。但是,英语口语改卷涉及的技术问题还很多,其中 主要有语音识别技术、自然语言处理技术。 近年来出现了一些基于计算机和网络技术的英语口语机考系统,如上海外语教育 出版社的口语机考系统、蓝鸽的系统等,实现了考官和考生在场所上的分离,支持了大规模 的口语考试的组织。但在阅卷方面,仅支持客观题的阅卷。主观题的阅卷工作仍需要投入大 量的人力物力。例如英语考试主观题当中的复述题。因此现实当中对于口语表达水平评分 任务而言,仍然完全由人工进行批阅,且这种评分任务不仅主观性强,而且时间紧、强度高, 因此阅卷的质量很难控制。
技术实现要素:
本发明的目的是为了解决现有技术中的问题,而提出的一种基于声音识别的英语 口语朗读自动评分系统。 为了实现上述目的,本发明采用了如下技术方案:一种基于声音识别的英语口语 朗读自动评分系统,包括互相连接的客户端、评分服务器以及云数据库; 所述客户端包括语音提取模块、声音处理器、通信模块; 所述语音提取模块通过录音装置录得用户的口语声音,并转化成数字信号输出至 声音识别器; 所述声音处理器包括:降噪模块、转化模块、特征提取模块、噪音压制模块、识别模 块、控制模块; 所述通信模块收集语音提取模块和声音处理器的信号并输送至评分服务器中; 所述评分服务器包括评分装置和统计上传模块;所述评分装置包括识别模块和评 分模块; 所述识别模块包括声学模块、语言模块以及具体识别模块,所述声学模块提取用 户作答音频的声学特征得到声学模型,所述语言模块根据题目信息及训练文本得到语言模 型,所述识别模块通过声学模型和语言模型对用户作答音频进行解码得到识别结果; 所述评分模块包括有效特征提取模块和有效特征评分模块,所述有效特征提取模 块用于提取所述识别结果中的语流综合特征,所述语流综合特征包括口语测评中发音准确 度方向的特征、流利度方向的特征以及文本语义相似度方向的特征,所述文本语义相似度 4 CN 111599234 A 说 明 书 2/5 页 方向的特征包括语义相关度特征以及语法结构相似度特征;所述有效特征提取模块用于提 取所述语义相关度特征; 所述统计上传模块收集评分模块中的有效特征并按照其相似度顺序排序,所述统 计上传模块将排序完成的有效特征上传至云数据库。 在上述的基于声音识别的英语口语朗读自动评分系统中,所述降噪模块对实时获 取的用户声音或已存储的其它声音进行噪声抑制,获得降噪后的声音信息;所述噪声抑制 模块采用了谱去除法和/或学习同定法和/或降噪自动编码器至少之一进行噪声抑制; 所述转化模块将声音信息进行拉普拉斯变换,得到拉普拉斯频谱信息; 所述特征提取模块将得到的拉普拉斯频谱信息进行二维傅里叶变换,得到拉普拉 斯变换声音信息数据波数谱特征; 所述噪音压制模块根据所述拉普拉斯变换声音信息数据波数谱,截取至少5个时 间切片的滤波因子组合成滤波团;将时间切片的信息数据进行二维傅里叶变换,得到滤波 信息数据波数谱,利用滤波信息数据波数谱对整段录音的声音数据波数谱进行环境噪音压 制,并将环境噪音压制后的声音数据输送至评分服务器。 在上述的基于声音识别的英语口语朗读自动评分系统中,所述识别模块使用与作 为识别对象而预先设定的语言即英语对应的声音识别引擎,参照识别对象语信息,对正在 输入的输入声音进行声音识别,该识别对象语信息具有声音识别词典中预先登记的识别对 象词汇所包含的各识别对象语的标记信息和读音信息; 所述云数据库中登记有表示单词的读音信息在多种语言之间的对应关系的读音 信息转换规则,所述读音信息转换基于云数据库的读音信息转换规则,在语言之间转换单 词的读音信息。 在上述的基于声音识别的英语口语朗读自动评分系统中,所述控制模块控制由声 音识别模块对识别对象语信息进行参照的识别对象词汇中包含有与所述设定语言不同的 语言即其它语言的单词的情况下,由所述读音信息转换模块将所述其它语言的读音信息转 换成所述设定语言的读音信息,所述识别模块参照将正在输入的所述输入声音的转换后的 所述设定语言的读音信息以及所述声音识别词典中预先登记的所述识别对象词汇的所述 识别对象语信息来进行声音识别。 在上述的基于声音识别的英语口语朗读自动评分系统中,所述语义相关度特征包 括:计算识别结果中的每一个单词和标准答案中每一个单词的语义相似度得分;计算识别 结果中的每一个单词和标准答案中每一个句子的语义相似度得分;计算识别结果中每一个 单词和标准答案中每一个句子中的语义相似度得分最大值或者平均值作为单词与句子之 间的相似度得分;计算用户答案和标准答案之间的相似度得分。 在上述的基于声音识别的英语口语朗读自动评分系统中,所述有效特征提取模块 用于提取所述语法结构相似度特征,包括:分别为识别结果的每一个句子建立语法顺序矢 量;分别求出识别结果中的每一个句子和标准答案中的每一个句子的语法结构相似度得 分,取识别结果中每一个句子语法结构相似度得分最大值作为这个句子的语法结构相似度 得分;通过对识别结果中每一个句子语法结构相似度得分加权平均计算用户答案和标准答 案之间的语法结构相似度特征。 在上述的基于声音识别的英语口语朗读自动评分系统中,所述识别模块采用基于 5 CN 111599234 A 说 明 书 3/5 页 大规模连续语音识别的解码系统,所述声学模型采用基于隐马尔科夫模型,所述语言模型 采用基于元文法的语言模型,在进行解码时采用基于多遍解码技术,所述多遍解码包括直 接解码、基于最大线性似然回归的非监督性自适应及二次解码;所述有效特征评分模块对 语流综合特征进行评分训练,得到评分模型,并依据评分模型对识别结果进行评分。 与现有的技术相比,本发明的优点在于: 1、在高噪音环境下,通过在噪音压制模块截取至少5个时间切片的滤波因子,利用 滤波信息数据波数谱对整段录音的声音数据波数谱进行环境噪音压制,并将环境噪音压 制,实现高噪音下的准确声音识别,便于后续的评分操作; 2、本申请中的声音识别模块和评分模块提取所述识别结果中的语流综合特征、发 音准确度方向的特征、流利度方向的特征以及文本语义相似度方向的特征,再根据计算识 别结果与标准答案比对相似度,从而得出相似度得分,相比现有技术的评分具有高效、准 确、迅速的技术效果。 附图说明 图1为本发明提出的一种基于声音识别的英语口语朗读自动评分系统的系统框 图; 图2为本发明提出的一种基于声音识别的英语口语朗读自动评分系统中评分装置 部分的系统框图。











