
技术摘要:
本发明公开了一种基于FFT的脉间频率捷变雷达的目标速度估计方法,主要解决现有脉间频率捷变雷达进行目标速度估计时计算量大、耗时久的问题。其实现方案是:随机生成脉间频率捷变雷达的跳频频点;按生成的跳频频点顺序发射和接收脉间频率捷变雷达回波;通过正交下变频获 全部
背景技术:
随着雷达干扰机的技术进步,针对传统固定参数脉冲多普勒体制雷达的干扰策略 与干扰设备已经日趋成熟,于是一种脉冲间载波频率随机跳变的新体制雷达应运而生。脉 间频率捷变雷达由于其载波频率随机跳变的特性,不易被干扰机截获,从而提高雷达抗干 扰的能力。但也正是因为脉间频率跳变,导致脉间信号相位不连续,因此无法进行传统的相 参积累,从而无法通过传统的动目标检测MTD技术来估计目标的速度。西安电子科技大学在 其公开的专利文献“基于相参频率捷变雷达的速度解模糊方法”(专利申请号 201910369131X,公布号CN110109078A)中公开了一种基于相参频率捷变雷达的速度解模糊 方法,包括脉冲压缩、构造多普勒向量组、采用最大相关法确定多普勒偏移频率。该方案虽 然可以估计出目标多普勒偏移频率从而得到目标速度的估计,但是由于其采用最大相关 法,计算量较大,对于雷达信号处理实时性要求高的应用场合,难以满足实时处理的需求。
技术实现要素:
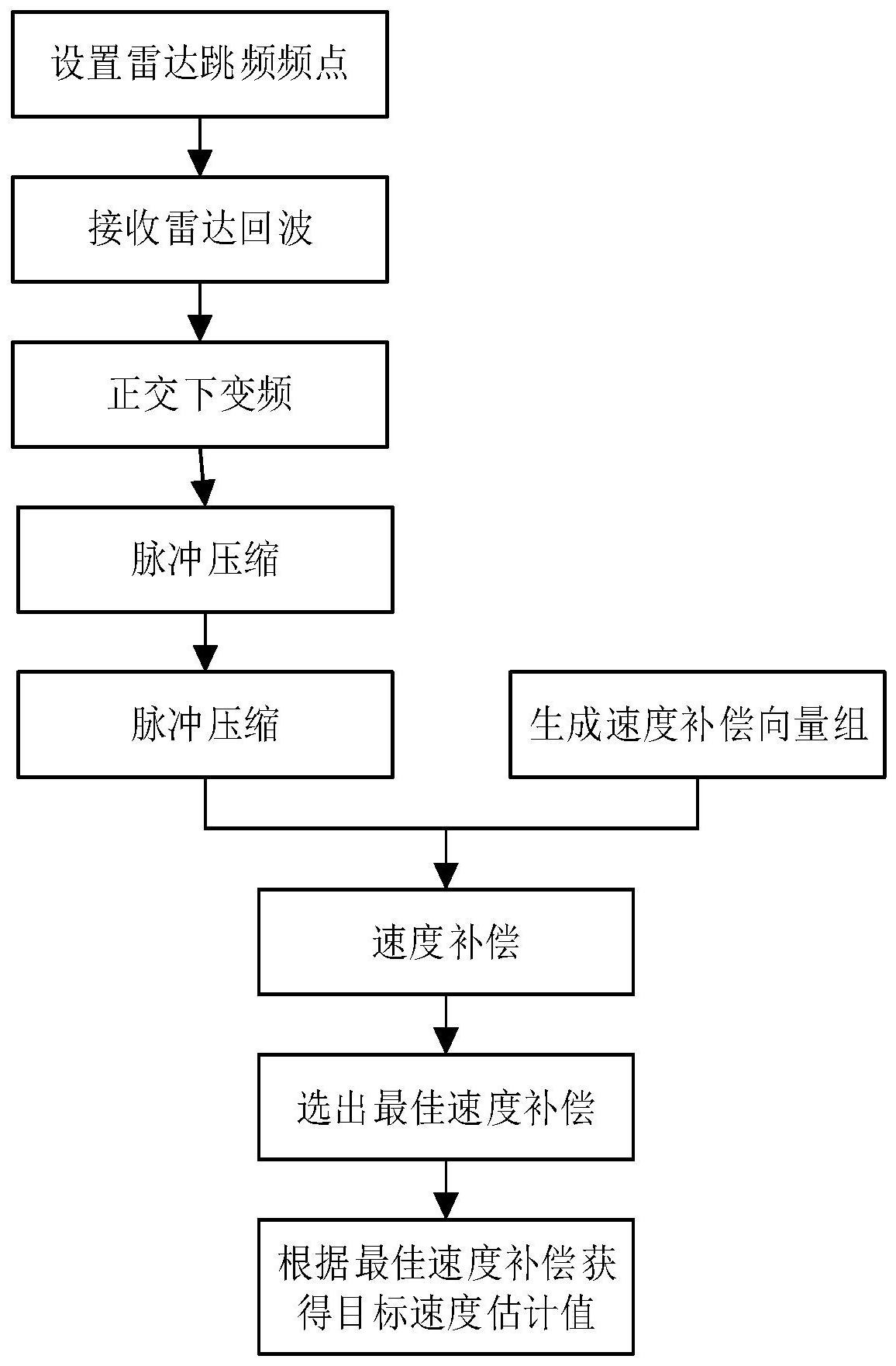
本发明的目的是针对上述现有技术的不足,提出一种基于FFT的脉间频率捷变雷 达的目标速度估计方法,减小计算量,提高信号处理速度,满足雷达信号处理实时性要求。 为实现上述目的,本发明技术方案包括如下步骤: (1)预设载波频率跳变范围,并将其等分为N个频点,N为2的整数次幂,从1到N顺次 编号;在脉间频率捷变雷达的每个相干积累间隔内从N个频点中随机选出M个频点作为载波 频率,M不小于N/4; (2)在一个相干积累间隔内,脉间频率捷变雷达发射机以(1)中选出的M个频点为 载频,依次发射M个线性调频脉冲信号;该脉冲信号经目标反射后,由脉间频率捷变雷达接 收机顺次接收; (3)用正交下变频方法,去除每一个雷达接收回波中的载频信息,得到M个基带复 信号; (4)将M个基带复信号与雷达发射脉冲信号分别转换至频域,并对后者取共轭,再 对两者依次进行哈达玛积和快速傅里叶逆变换IFFT,得到M行L列的脉冲压缩矩阵Φ,其中L 为每个脉冲压缩的数据长度; (5)设置速度检测范围和检测精度,并参照M个载频的排序关系,生成Q个补偿速度 v1 ,v2,…,vq ,...,vQ以及Q个M维的速度补偿向量 其中vq表示第q个 补偿速度, 表示第q个速度补偿向量,q=1,2,...,Q; (6)按距离单元取出脉冲压缩矩阵,分别与Q个速度补偿向量做哈达玛积,得到Q个 速度补偿结果,即Q个M维的向量 其中 表示第q个速度补偿结果,q=1 , 5 CN 111551925 A 说 明 书 2/5 页 2,...,Q,l=1,2,...,L表示第l个距离单元,每一个补偿结果中的M个元素一一对应相干积 累间隔内的M个跳频频点; (7)选取最佳速度补偿结果: (7a)将每一个速度补偿结果向量中的M个元素依据跳频频点的编号进行重排,并 在编号不连续处填充0元素,使其扩充到N维,得到Q个N维的新的速度补偿结果 其中 表示重排后的第q个速度补偿结果,q=1,2,...,Q,l=1,2,...,L 表示第l个距离单元; (7b)对每一个距离单元对应的Q个新的速度补偿结果,分别做Q次N点快速傅里叶 变换FFT,得到频谱 其中 表示第q个速度补偿结果的频谱; (7c)根据最大FFT峰值确定每一个距离单元对应的Q个速度补偿结果中的最佳速 度补偿结果 (8)根据最佳速度补偿结果 找到对应的最佳速度补偿向量 中的速度 值vq '即为目标速度的估计值,其中 vq '∈v1 ,v2,...,vq ,..., vQ,q=1,2,...,Q。 本发明具有如下优点: 第一,本发明基于脉间频率捷变体制雷达,相比传统固定参数雷达,脉间频率捷变 雷达信号不容易被截获,有更强的抗干扰能力。 第二,本发明采用速度补偿的方式估计目标速度,在选取最佳补偿速度时,先利用 快速傅里叶变换FFT将速度补偿结果转换到频域,然后通过搜索最大谱峰来确定最佳补偿 结果,从而获得最佳补偿速度。在系统参数满足一定条件时,相比于现有的最大相关法,本 发明能够显著减小计算量,提高雷达系统实时信号处理能力。 例如,对于跳频总点数为N、一个相干积累间隔内的雷达脉冲数为M、速度补偿向量 数目为Q的脉间频率捷变雷达,其中M<N,若采用现有的最大相关法选取最佳补偿速度时, 需要额外提供一个M*N的字典矩阵,总共需要QMN次复数乘法和Q(M-1)N次复数加法;而采用 本发明方法时,筛选出最佳补偿速度总共需要 次复数乘法和QN log2N次复数加 法。当满足M>(1 log2N)时,本发明可以大大减小计算量,有利于提高雷达信号处理速度、 满足实时性需求,同时节省硬件计算资源。以M=64、N=128、Q=27为例,最大相关法需要 221184复数乘法和217728次复数加法,而本发明方法只需要6048次复数乘法和12096次复 数加法,计算量显著减小。 附图说明 图1为本发明的实现总流程图; 图2为本发明中选取最佳速度补偿结果子流程图。











